

At this 12 months’s Knowledge+AI Summit, Databricks SQL continued to push the boundaries of what a knowledge warehouse may be, leveraging AI throughout your entire product floor to increase our management in efficiency and effectivity, whereas nonetheless simplifying the expertise and unlocking new alternatives for our prospects. In parallel, we proceed to ship enhancements to our core knowledge warehousing capabilities that will help you unify your knowledge stack beneath Lakehouse.
On this weblog publish, we’re thrilled to share the highlights of what is new and coming subsequent in Databricks SQL:
The AI-optimized warehouse: Prepared for all of your workloads – no tuning required
We imagine that one of the best knowledge warehouse is a lakehouse; due to this fact, we proceed to increase our management in ETL workloads and harnessing the facility of AI. Databricks SQL now additionally delivers industry-leading efficiency on your EDA and BI workloads, whereas enhancing value financial savings – with no handbook tuning.

Say goodbye to manually creating indexes. With Predictive I/O for reads (GA) and updates (Public Preview), Databricks SQL now analyzes historic learn and write patterns to intelligently construct indexes and optimize workloads. Early prospects have benefited from a exceptional 35x enchancment in level lookup effectivity, spectacular efficiency boosts of 2-6x for MERGE operations and 2-10x for DELETE operations.
With Predictive Optimizations (Public Preview), Databricks will seamlessly optimize file sizes and clustering by operating OPTIMIZE, VACUUM, ANALYZE and CLUSTERING instructions for you. With this function, Anker Improvements benefited from a 2.2x enhance to question efficiency whereas delivering 50% financial savings on storage prices.
“Databricks’ Predictive Optimizations intelligently optimized our Unity Catalog storage, which saved us 50% in annual storage prices whereas rushing up our queries by >2x. It realized to prioritize our largest and most-accessed tables. And, it did all of this robotically, saving our group helpful time.”
— Anker Improvements
Uninterested in managing totally different warehouses for smaller and bigger workloads or tremendous tuning scaling parameters? Clever Workload Administration is a collection of options that retains queries quick whereas preserving value low. By analyzing actual time patterns, Clever Workload Administration ensures that your workloads have the optimum quantity of compute to execute incoming SQL statements with out disrupting already operating queries.
With AI-powered optimizations, Databricks SQL supplies {industry} main TCO and efficiency for any sort of workload, with none handbook tuning wanted. To study extra about obtainable optimization previews, watch Reynold Xin’s keynote and Databricks SQL Serverless Beneath the Hood: How We Use ML to Get the Greatest Worth/Efficiency from the Knowledge+AI Summit.
Unlock siloed knowledge with Lakehouse Federation
At this time’s organizations face challenges in discovering, governing and querying siloed knowledge sources throughout fragmented methods. With Lakehouse Federation, knowledge groups can use Databricks SQL to find, question and handle knowledge in exterior platforms together with MySQL, PostgreSQL, Amazon Redshift, Snowflake, Azure SQL Database, Azure Synapse, Google’s BigQuery (coming quickly) and extra.
Moreover, Lakehouse Federation seamlessly integrates with superior options of Unity Catalog when accessing exterior knowledge sources from inside Databricks. Implement row and column degree safety to limit entry to delicate info. Leverage knowledge lineage to hint the origins of your knowledge and guarantee knowledge high quality and compliance. To arrange and handle knowledge belongings, simply tag federated catalog belongings for easy knowledge discovery.
Lastly, to speed up sophisticated transformations or cross-joins on federated sources, Lakehouse Federation helps Materialized Views for higher question latencies.
Lakehouse Federation is in Public Preview at present. For extra particulars, watch our devoted session Lakehouse Federation: Entry and Governance of Exterior Knowledge Sources from Unity Catalog from the Knowledge+AI Summit.
Develop on the Lakehouse with the SQL Assertion Execution API
The SQL Assertion Execution API allows entry to your Databricks SQL warehouse over a REST API to question and retrieve outcomes. With HTTP frameworks obtainable for nearly all programming languages, you possibly can simply hook up with a various array of purposes and platforms on to a Databricks SQL Warehouse.
The Databricks SQL Assertion Execution API is out there with the Databricks Premium and Enterprise tiers. To study extra, watch our session, comply with our tutorial (AWS | Azure), learn the documentation (AWS | Azure), or examine our repository of code samples.
Streamline your knowledge processing with Streaming Tables, Materialized Views, and DB SQL in Workflows
With Streaming Tables, Materialized Views, and DB SQL in Workflows, any SQL consumer can now apply knowledge engineering finest practices to course of knowledge. Effectively ingest, remodel, orchestrate, and analyze knowledge with only a few traces of SQL.
Streaming Tables are the perfect solution to convey knowledge into “bronze” tables. With a single SQL assertion, scalably ingest knowledge from numerous sources reminiscent of cloud storage (S3, ADLS, GCS), message buses (EventHub, Kafka, Kinesis), and extra. This ingestion happens incrementally, enabling low-latency and cost-effective pipelines, with out the necessity for managing complicated infrastructure.
CREATE STREAMING TABLE web_clicks
AS
SELECT *
FROM STREAM
read_files('s3://mybucket')
Materialized Views cut back value and enhance question latency by pre-computing gradual queries and incessantly used computations, and are incrementally refreshed to enhance general latency. In a knowledge engineering context, they’re used for remodeling knowledge. However they’re additionally helpful for analyst groups in a knowledge warehousing context as a result of they can be utilized to (1) velocity up end-user queries and BI dashboards, and (2) securely share knowledge. In simply 4 traces of code, any consumer can create a materialized view for performant knowledge processing.
CREATE MATERIALIZED VIEW customer_orders
AS
SELECT
prospects.title,
sum(orders.quantity),
orders.orderdate
FROM orders
LEFT JOIN prospects ON
orders.custkey = prospects.c_custkey
GROUP BY
title,
orderdate;
Want orchestration with DB SQL? Workflows now means that you can schedule SQL queries, dashboards and alerts. Simply handle complicated dependencies between duties and monitor previous job executions with the intuitive Workflows UI or by way of API.
Streaming Tables and Materialized Views at the moment are in public preview. To study extra, learn our devoted weblog publish. To enroll within the public preview for each, enroll on this type. Workflows in DB SQL is now usually obtainable, and you may study extra by studying the documentation (AWS | Azure).
Databricks Assistant and LakehouseIQ: Write higher and sooner SQL with pure language
Databricks Assistant is a context-aware AI assistant embedded inside Databricks Notebooks and the SQL Editor. Databricks Assistant can take a pure language query and recommend a SQL question to reply that query. When attempting to know a fancy question, customers can ask the Assistant to elucidate it utilizing pure language, enabling anybody to know the logic behind question outcomes.
Behind the scenes, Databricks Assistant is powered by an AI data engine referred to as LakehouseIQ. LakehouseIQ understands alerts reminiscent of schemas, recognition, lineage, feedback, and docs to enhance the search and AI experiences in Databricks. LakehouseIQ will improve quite a lot of present product experiences with extra correct, related outcomes together with Search, Assist, and Databricks Assistant.
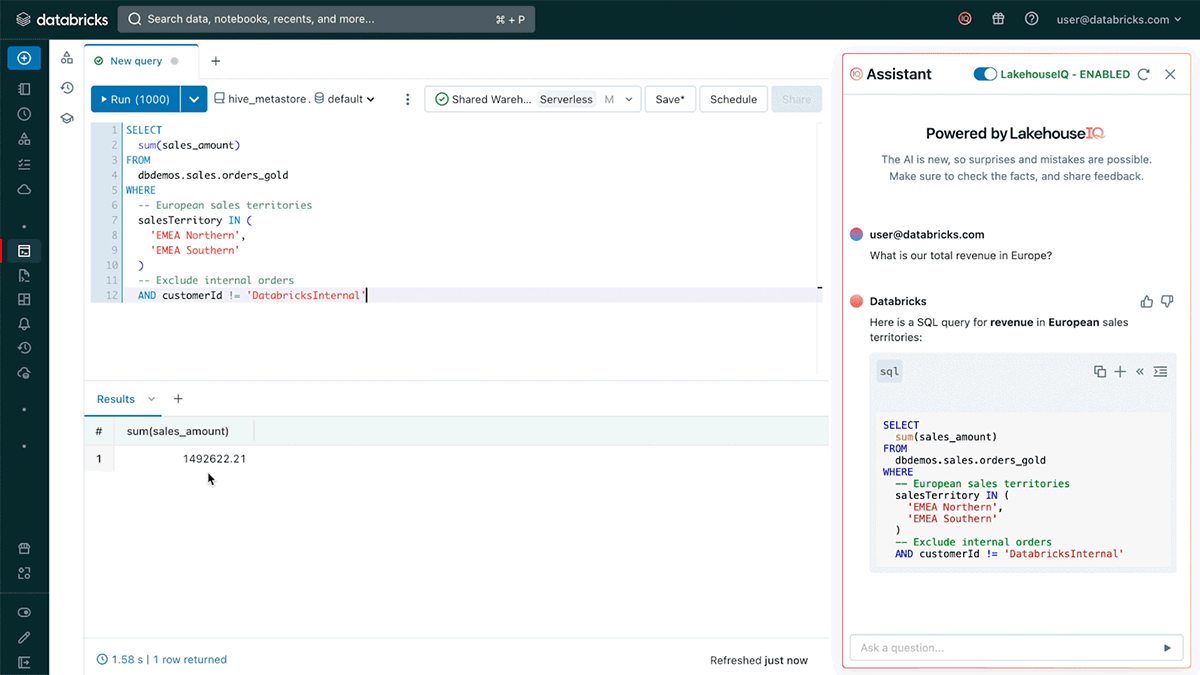
LakehouseIQ is presently in improvement and might be obtainable later this 12 months. Databricks Assistant might be obtainable for public preview within the subsequent few weeks. Over time, we’ll combine the Assistant with LakehouseIQ to offer extra correct strategies personalised in your firm’s knowledge.
Handle your knowledge warehouse with confidence
Directors and IT groups want the instruments to know knowledge warehouse utilization. With System Tables, Stay Question Profile, and Assertion Timeouts, admins can monitor and repair issues after they happen, guaranteeing that your knowledge warehouse runs effectively.
Achieve deeper visibility and insights into your SQL surroundings with System Tables. System Tables are Databricks-provided tables that include details about previous assertion executions, prices, lineage, and extra. Discover metadata and utilization metrics to reply questions like “What statements had been run and by whom?”, “How and when did my warehouses scale?” and “What was I billed for?”. Since System Tables are built-in inside Databricks, you could have entry to native capabilities reminiscent of SQL alerts and SQL dashboards to automate the monitoring and alerting course of.
As of at present, there are three System Tables presently in public preview: Audit Logs, Billable Utilization System Desk, and Lineage Sytem Desk (AWS | Azure). Extra system tables for warehouse occasions and assertion historical past are coming quickly.
For instance, to compute the month-to-month DBUs used per SKU, you possibly can question the Billiable Utilization System Tables.
SELECT sku_name, usage_date, sum(usage_quantity) as `DBUs`
FROM system.billing.utilization
WHERE
month(usage_date) = month(NOW())
AND 12 months(usage_date) = 12 months(NOW())
GROUP BY sku_name, usage_date
With Stay Question Profile, customers acquire real-time insights into question efficiency to assist optimize workloads on the fly. Visualize question execution plans and assess dwell question process executions to repair widespread SQL errors like exploding joins or full desk scans. Stay Question Profile means that you can be sure that operating queries in your knowledge warehouse are optimized and operating effectively. Study extra by studying the documentation (AWS | Azure).
Searching for automated controls? Assertion Timeouts assist you to set a customized workspace or question degree timeout. If a question’s execution time exceeds the timeout threshold, the question might be robotically halted. Study extra by studying the documentation (AWS | Azure)
Compelling new experiences in DBSQL
Over the previous 12 months, we have been exhausting at work so as to add new, cutting-edge experiences to Databricks SQL. We’re excited to announce new options that put the facility of AI in SQL customers palms reminiscent of, enabling SQL warehouses all through your entire Databricks platform; introducing a brand new technology of SQL dashboards; and bringing the facility of Python into Databricks SQL.
Democratize unstructured knowledge evaluation with AI Features
With AI Features, DB SQL is bringing the facility of AI into the SQL warehouse. Effortlessly harness the potential of unstructured knowledge by performing duties reminiscent of sentiment evaluation, textual content classification, summarization, translation and extra. Knowledge analysts can apply AI fashions by way of self-service, whereas knowledge engineers can independently construct AI-enabled pipelines.
Utilizing AI Features is sort of easy. For instance, think about a state of affairs the place a consumer desires to categorise the sentiment of some articles into Annoyed, Completely satisfied, Impartial, or Happy.
-- create a udf for sentiment classification
CREATE FUNCTION classify_sentiment(textual content STRING)
RETURNS STRING
RETURN ai_query(
'Dolly', -- the title of the mannequin serving endpoint
named_struct(
'immediate',
CONCAT('Classify the next textual content into one among 4 classes [Frustrated, Happy, Neutral, Satisfied]:n',
textual content),
'temperature', 0.5),
'returnType', 'STRING');
-- use the udf
SELECT classify_sentiment(textual content) AS sentiment
FROM critiques;
AI Features at the moment are in Public Preview. To join the Preview, fill out the shape right here. To study extra, you may also learn our detailed weblog publish or assessment the documentation (AWS | Azure).
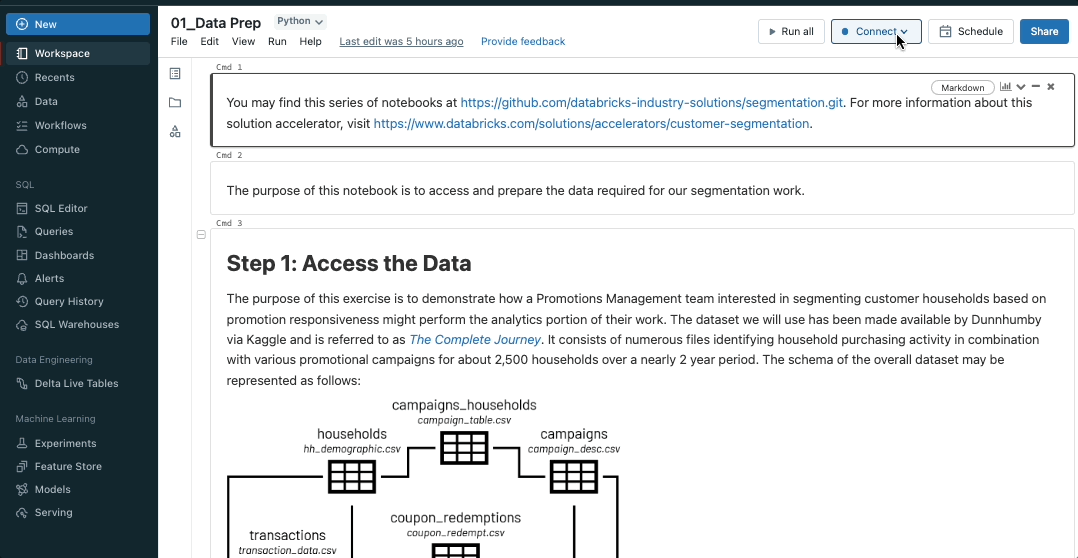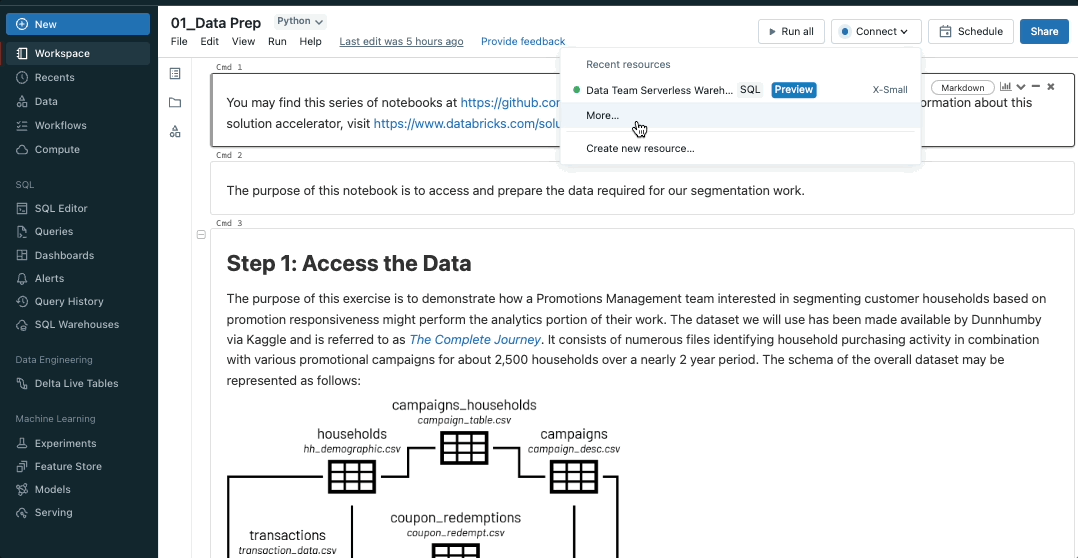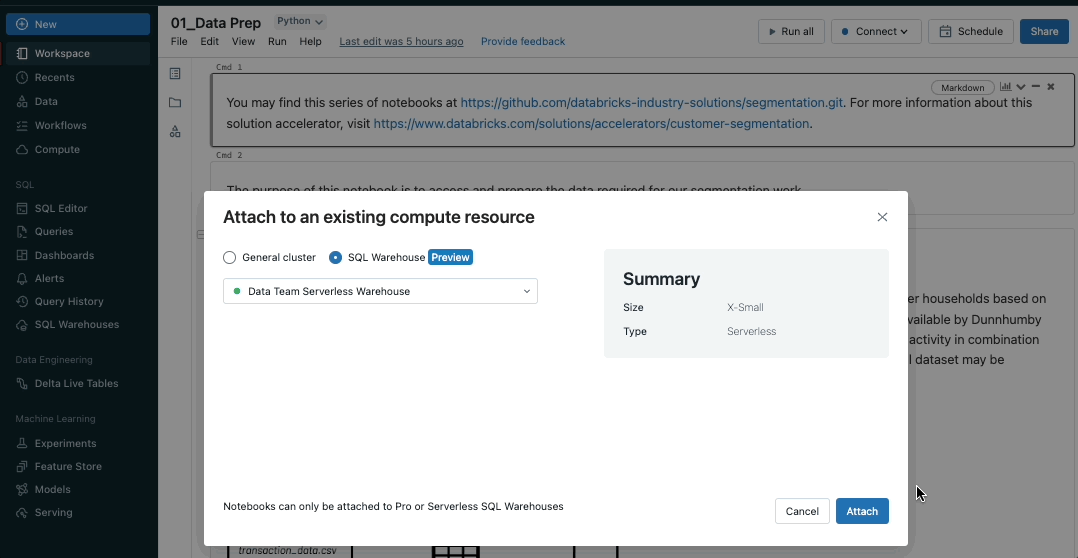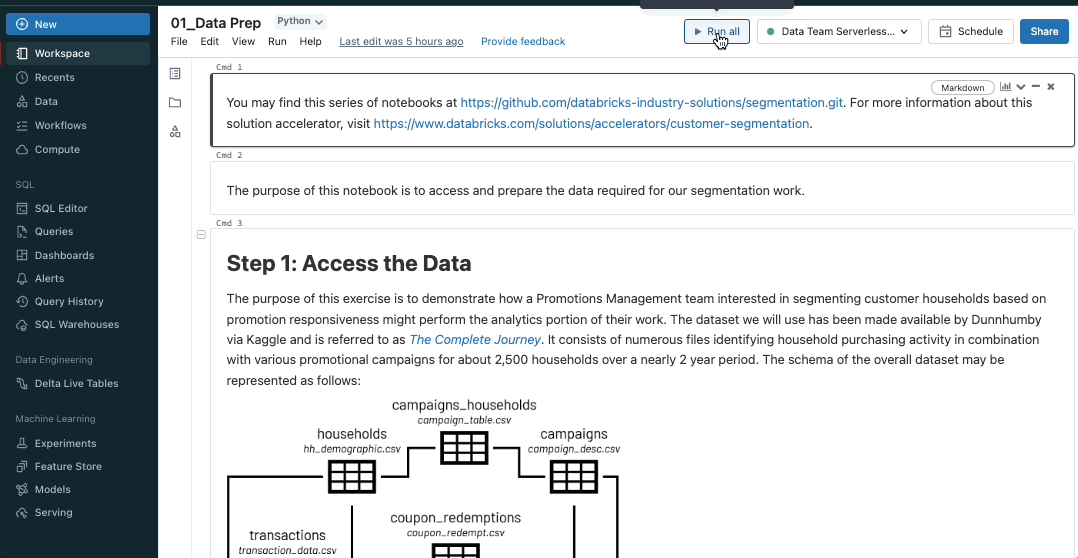
Convey the facility of SQL warehouses to notebooks
Databricks SQL warehouses are now public preview in notebooks, combining the pliability of notebooks with the efficiency and TCO of Databricks SQL Serverless and Professional warehouses. To allow SQL warehouses in notebooks, merely choose an obtainable SQL warehouse from the notebooks compute dropdown.
Discover and share insights with a brand new technology of dashboards
Uncover a revamped dashboarding expertise instantly on the Lakehouse. Customers can merely choose a desired dataset and construct beautiful visualizations with a SQL-optional expertise. Say goodbye to managing separate queries and dashboard objects – an all-in-one content material mannequin simplifies the permissions and administration course of. Lastly, publish a dashboard to your total group, in order that any authenticated consumer in your id supplier can entry the dashboard by way of a safe net hyperlink, even when they do not have Databricks entry.
New Databricks SQL Dashboards are presently in Non-public Preview. Contact your account group to study extra.
Leverage the pliability of Python in SQL
Convey the pliability of Python into Databricks SQL with Python user-defined capabilities (UDFs). Combine machine studying fashions or apply customized redaction logic for knowledge processing and evaluation by calling customized Python capabilities instantly out of your SQL question. UDFs are reusable capabilities, enabling you to use constant processing to your knowledge pipelines and evaluation.
For example, to redact e-mail and telephone numbers from a file, think about the next CREATE FUNCTION assertion.
CREATE FUNCTION redact(a STRING)
RETURNS STRING
LANGUAGE PYTHON
AS $$
import json
keys = ["email", "phone"]
obj = json.hundreds(a)
for okay in obj:
if okay in keys:
obj[k] = "REDACTED"
return json.dumps(obj)
$$;
Study extra about enrolling within the non-public preview right here.
Integrations together with your knowledge ecosystem
At Knowledge+AI Summit, Databricks SQL introduced new integrations for a seamless expertise together with your instruments of selection.
Databricks + Fivetran
We’re thrilled to announce the overall availability of Fivetran entry in Companion Join for all customers together with non-admins with adequate privileges to a catalog. This innovation makes it 10x simpler for all customers to ingest knowledge into Databricks utilizing Fivetran. This can be a enormous win for all Databricks prospects as they will now convey knowledge into the Lakehouse from a whole bunch of connectors Fivetran gives, like Salesforce and PostgreSQL. Fivetran now absolutely helps Serverless warehouses as effectively!
Study extra by studying the weblog publish right here.
Databricks + dbt Labs
Simplify real-time analytics engineering on the lakehouse structure with Databricks and dbt Labs. The mixture of dbt’s extremely fashionable analytics engineering framework with the Databricks Lakehouse Platform supplies highly effective capabilities:
- dbt + Streaming Tables: Streaming ingestion from any supply is now built-in to dbt tasks. Utilizing SQL, analytics engineers can outline and ingest cloud/streaming knowledge instantly inside their dbt pipelines.
- dbt + Materialized Views: Constructing environment friendly pipelines turns into simpler with dbt, leveraging Databricks’ highly effective incremental refresh capabilities. Customers can use dbt to construct and run pipelines backed by MVs, lowering infrastructure prices with environment friendly, incremental computation.
To study extra, learn the detailed weblog publish.
Databricks + PowerBI: Publish to PowerBI Workspaces
Publish datasets out of your Databricks workspace to PowerBI On-line workspace with a couple of clicks! No extra managing odbc/jdbc connections – merely choose the dataset you need to publish. Merely choose the datasets or schema you need to publish and choose your PBI workspace! This makes it simpler for BI admins and report creators to help PowerBI workspaces with out additionally having to make use of Energy BI Desktop.
PowerBI integration with Knowledge Explorer is coming quickly and can solely be obtainable on Azure Databricks.
Getting Began with Databricks SQL
Comply with the information (AWS | Azure | GCP ) on find out how to setup a SQL warehouse to get began with Databricks SQL at present! Databricks SQL Serverless is presently obtainable with a 20%+ promotional low cost, go to our pricing web page to study extra.
It’s also possible to watch Databricks SQL: Why the Greatest Serverless Knowledge Warehouse is a Lakehouse and What’s New in Databricks SQL — With Stay Demos for a whole overview.

{kind=link}