
Introduction
In deep studying, optimization algorithms are essential parts that assist neural networks study effectively and converge to optimum options. One of the vital common optimization algorithms utilized in coaching deep neural networks is the Adam optimizer, and attaining optimum efficiency and coaching effectivity is a quest that continues to captivate researchers and practitioners alike. This weblog publish deeply dives into the Adam optimizer, exploring its internal workings, benefits, and sensible suggestions for utilizing it successfully.
Studying Aims
- Adam adjusts studying charges individually for every parameter, permitting for environment friendly optimization and convergence, particularly in advanced loss landscapes.
- Incorporating bias correction mechanisms to counter initialization bias within the first moments facilitates sooner convergence throughout early coaching phases.
- In the end, Adam’s major aim is to stabilize the coaching course of and assist neural networks converge to optimum options.
- It goals to optimize mannequin parameters effectively, swiftly navigating by way of steep and flat areas of the loss operate.
This text was printed as part of the Knowledge Science Blogathon.
What’s the Adam Optimizer?
The Adam optimizer, brief for “Adaptive Second Estimation,” is an iterative optimization algorithm used to reduce the loss operate in the course of the coaching of neural networks. Adam might be checked out as a mix of RMSprop and Stochastic Gradient Descent with momentum. Developed by Diederik P. Kingma and Jimmy Ba in 2014, Adam has grow to be a go-to alternative for a lot of machine studying practitioners.

It makes use of the squared gradients to scale the educational charge like RMSprop, and it takes benefit of momentum by utilizing the shifting common of the gradient as an alternative of the gradient itself, like SGD with momentum. This combines Dynamic Studying Price and Smoothening to achieve the worldwide minima.
Adam Optimization Algorithm

The place w is mannequin weights, b is for bias, and eta (appears just like the letter n) is the step measurement (it may rely on iteration). And that’s it, that’s the replace rule for Adam, which is also referred to as the Studying charge.

Steps Concerned within the Adam Optimization Algorithm
1. Initialize the primary and second moments’ shifting averages (m and v) to zero.
2. Compute the gradient of the loss operate to the mannequin parameters.
3. Replace the shifting averages utilizing exponentially decaying averages. This includes calculating m_t and v_t as weighted averages of the earlier moments and the present gradient.
4. Apply bias correction to the shifting averages, notably in the course of the early iterations.
5. Calculate the parameter replace by dividing the bias-corrected first second by the sq. root of the bias-corrected second second, with an added small fixed (epsilon) for numerical stability.
6. Replace the mannequin parameters utilizing the calculated updates.
7. Repeat steps 2-6 for a specified variety of iterations or till convergence.
Key Options of Adam Optimizer
1. Adaptive Studying Charges: Adam adjusts the educational charges for every parameter individually. It calculates a shifting common of the first-order moments (the imply of gradients) and the second-order moments (the uncentered variance of gradients) to scale the educational charges adaptively. This makes it well-suited for issues with sparse gradients or noisy information.
2. Bias Correction: To counteract the initialization bias within the first moments, Adam applies bias correction in the course of the early iterations of coaching. This ensures sooner convergence and stabilizes the coaching course of.
3. Low Reminiscence Necessities: Not like some optimization algorithms that require storing a historical past of gradients for every parameter, Adam solely wants to take care of two shifting averages per parameter. This makes it memory-efficient, particularly for big neural networks.
Sensible Suggestions for Utilizing Adam Optimizer
1. Studying Price: Whereas Adam adapts the educational charges, selecting an affordable preliminary studying charge remains to be important. It usually performs effectively with the default worth of 0.001.
2. Epsilon Worth: The epsilon (ε) worth is a small fixed added for numerical stability. Typical values are within the vary of 1e-7 to 1e-8. It’s not often essential to vary this worth.
3. Monitoring: Monitor your coaching course of by monitoring the loss curve and different related metrics. Modify studying charges or different hyperparameters if essential.
4. Regularization: Mix Adam with regularization strategies like dropout or weight decay to stop overfitting.
Sensible Implementation
Gradient Descent With Adam
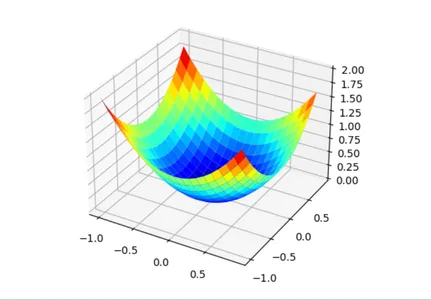
First, let’s outline an optimization operate. We are going to use a easy two-dimensional operate that squares the enter of every dimension and defines the vary of legitimate inputs from -1.0 to 1.0.
The target() operate beneath implements this operate.
from numpy import arange
from numpy import meshgrid
from matplotlib import pyplot
def goal(x, y):
return x**2.0 + y**2.0
# outline vary for enter
range_min, range_max = -1.0, 1.0
# pattern enter vary uniformly at 0.1 increments
xaxis = arange(range_min, range_max, 0.1)
yaxis = arange(range_min, range_max, 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
outcomes = goal(x, y)
determine = pyplot.determine()
axis = determine.add_subplot(111, projection='3d')
axis.plot_surface(x, y, outcomes, cmap='jet')
# present the plot
pyplot.present()
Adam in Neural Community
Right here’s a simplified Python code instance demonstrating learn how to use the Adam optimizer in a neural community coaching state of affairs utilizing the favored deep studying library TensorFlow. On this instance, we’ll use TensorFlow’s Keras API for creating and coaching a easy neural community for picture classification:
1. Importing Library:
import keras # Import the Keras library
from keras.datasets import mnist # Load the MNIST dataset
from keras.fashions import Sequential # Initialize a sequential mannequin
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
import numpy as np2. Break up Knowledge in prepare and check:
# Load the MNIST dataset from Keras
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Print the form of the coaching and check information
print(x_train.form, y_train.form)
# Reshape the coaching and check information to 4 dimensions
x_train = x_train.reshape(x_train.form[0], 28, 28, 1)
x_test = x_test.reshape(x_test.form[0], 28, 28, 1)
# Outline the enter form
input_shape = (28, 28, 1)
# Convert the labels to categorical format
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
# Convert the pixel values to floats between 0 and 1
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# Normalize the pixel values by dividing them by 255
x_train /= 255
x_test /= 255
# Outline the batch measurement and variety of courses
batch_size = 60
num_classes = 10
# Outline the variety of epochs to coach the mannequin for
epochs = 103. Outline mannequin operate:
"""
Builds a CNN mannequin for MNIST digit classification.
Args:
optimizer: The optimizer to make use of for coaching the mannequin.
Returns:
A compiled Keras mannequin.
"""
def build_model(optimizer):
mannequin = Sequential()
mannequin.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
mannequin.add(MaxPooling2D(pool_size=(2, 2)))
mannequin.add(Dropout(0.25))
mannequin.add(Flatten())
mannequin.add(Dense(128, activation='relu'))
mannequin.add(Dropout(0.5))
mannequin.add(Dense(num_classes, activation='softmax'))
mannequin.compile(loss="categorical_crossentropy", optimizer=optimizer, metrics=['accuracy'])
return mannequin
4. Optimization in Neural Community:
optimizers=['Adagrad','Adam','SGD']#import csv
histories ={decide:build_model(decide).match(x_train,y_train,batch_size=batch_size,
epochs=epochs,verbose=1,validation_data=(x_test,y_test)) for decide in optimiers}Benefits of Utilizing Adam Optimizer
1. Quick Convergence: Adam usually converges sooner than conventional gradient descent-based optimizers, particularly on advanced loss surfaces.
2. Adaptive Studying Charges: The adaptive studying charges make it appropriate for varied machine studying duties, together with pure language processing, laptop imaginative and prescient, and reinforcement studying.
3. Low Reminiscence Utilization: Low reminiscence necessities enable coaching giant neural networks with out operating into reminiscence constraints.
4. Robustness: Adam is comparatively strong to hyperparameter selections, making it a sensible choice for practitioners with out in depth hyperparameter tuning expertise.
Issues with Adam Optimizer
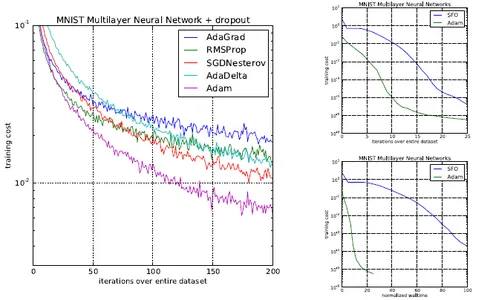
ADAM paper offered diagrams that confirmed even higher outcomes:
Current analysis has raised issues in regards to the generalization capabilities of the Adam optimizer in deep studying, indicating that it might not at all times converge to optimum options, notably in duties like picture classification on CIFAR datasets. Wilson et al.’s examine highlighted that adaptive optimizers like Adam may not generalize as successfully as SGD with momentum throughout varied deep-learning duties. Nitish Shirish Keskar and Richard Socher proposed an answer referred to as SWATS, the place coaching begins with Adam however switches to SGD as studying saturates. SWATS has proven promise in attaining aggressive generalization efficiency in comparison with SGD with momentum, prompting a reevaluation of optimization selections in deep studying.
Conclusion
Adam is without doubt one of the greatest optimization algorithms for deep studying, and its recognition is rising rapidly. Its adaptive studying charges, effectivity in optimization, and robustness make it a well-liked alternative for coaching neural networks. As deep studying evolves, optimization algorithms like Adam will stay important instruments. Nonetheless, practitioners ought to keep open to various approaches and techniques for attaining optimum mannequin efficiency.
Key Takeaways:
- Adam adjusts studying charges for every parameter individually, permitting environment friendly optimization by accommodating each excessive and low-gradient parameters.
- Adam’s adaptability and administration of moments make it environment friendly in navigating advanced loss landscapes, leading to sooner convergence.
- Hyperparameter tuning, notably for the preliminary studying charge and epsilon (ε), is essential for optimizing Adam’s efficiency.
I need to take a second to say thanks. Thanks for taking the time to learn this weblog and in your curiosity in Adam Optimizer in Neural Networks.
Till subsequent time, keep curious and continue learning!
Incessantly Requested Questions
A. Present a concise rationalization of the Adam optimizer’s rules and its adaptive studying charge mechanism.
A. Clarify eventualities and use instances the place the Adam optimizer is appropriate and its benefits over different optimization algorithms.
A. Focus on key hyperparameters just like the preliminary studying charge and epsilon (ε) and supply steering on learn how to set them successfully.
A. Tackle potential issues, reminiscent of sensitivity to hyperparameters or convergence points, and supply options.
A. Describe methods like SWATS for transitioning from Adam to a unique optimizer as coaching progresses.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Writer’s discretion.

{kind=link}