
Builders usually have to work with datasets with no mounted schema, like closely nested JSON information with a number of deeply nested arrays and objects, blended information varieties, null values, and lacking fields. As well as, the form of the info is inclined to vary when repeatedly syncing new information. Understanding the form of a dataset is essential to setting up complicated queries for constructing functions or performing information science investigations.
This weblog walks by how Rockset’s Sensible Schema function automates schema inference at learn time, enabling us to go from complicated JSON information, with nested objects and arrays, to insights with none friction.
Utilizing Sensible Schema to Perceive Your Knowledge
On Grammy evening, as I used to be watching the award ceremony dwell, I made a decision to begin poking across the dwell Twitter stream to see how the Twitterverse was reacting to it. To do that, I ingested the dwell Twitter stream right into a Rockset assortment known as twitter_collection to listing the highest 5 trending hashtags.
With none upfront data of what the Twitter information seems to be like, let’s name DESCRIBE on the gathering to grasp the form of the info.
The output of DESCRIBE has the next fields:
- subject: Each distinct subject identify within the assortment
- kind: The information kind of the sphere
- occurrences: The variety of paperwork which have this subject within the given kind
- whole: Complete variety of paperwork within the assortment for high stage fields, and whole variety of paperwork which have the mum or dad subject for nested fields
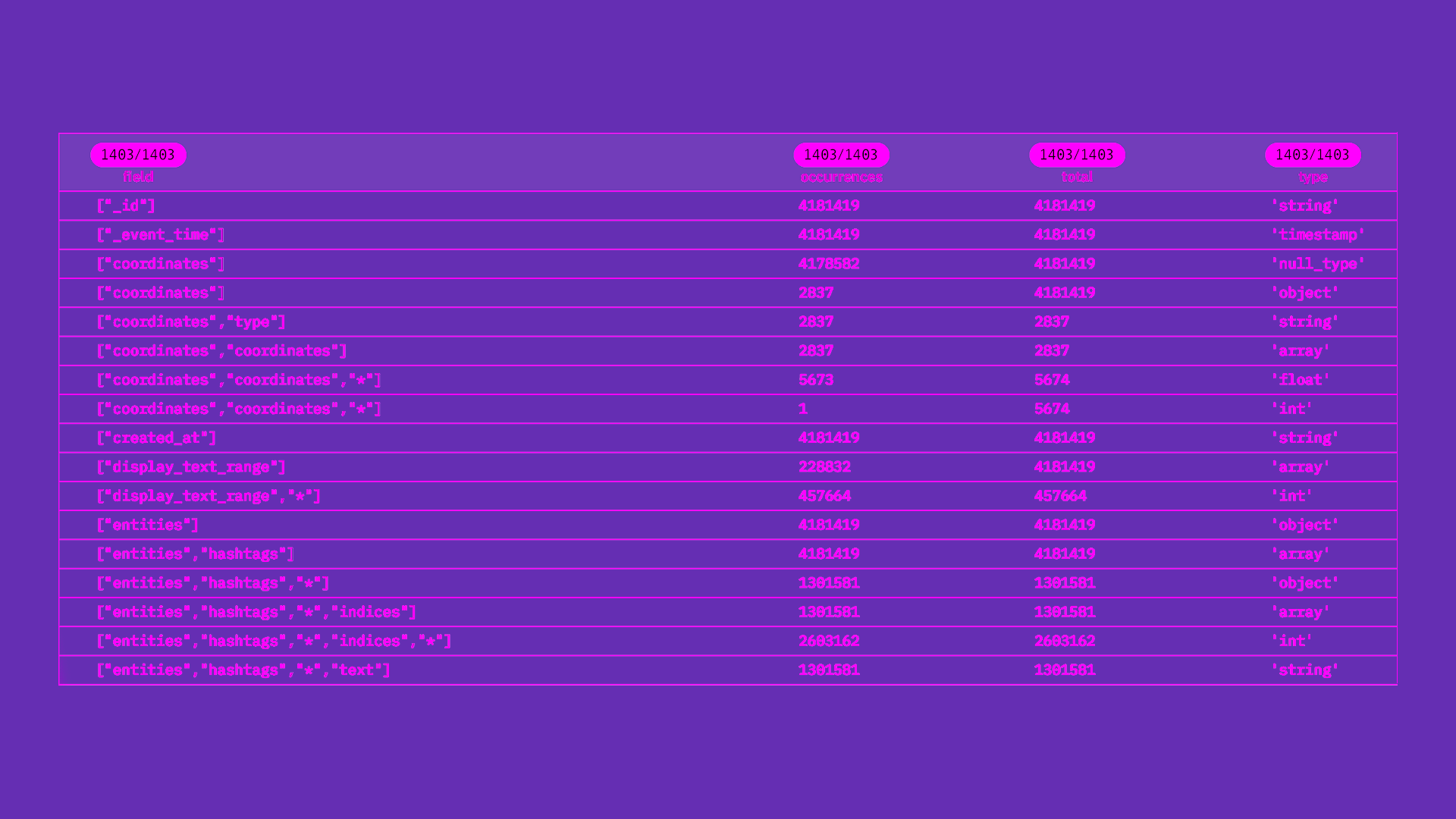
This output is what we discuss with as Sensible Schema. It tells us what fields are within the dataset, what varieties they’re, and the way dense or sparse they might be. Here’s a snippet of the Sensible Schema for twitter_collection.
rockset> DESCRIBE twitter_collection;
+-----------------------------------------------+---------------+---------+-----------+
| subject | occurrences | whole | kind |
|-----------------------------------------------+---------------+---------+-----------|
| ['id'] | 4181419 | 4181419 | string |
| ['_event_time'] | 4181419 | 4181419 | timestamp |
| ['coordinates'] | 4178582 | 4181419 | null_type |
| ['coordinates'] | 2837 | 4181419 | object |
| ['coordinates', 'type'] | 2837 | 2837 | string |
| ['coordinates', 'coordinates'] | 2837 | 2837 | array |
| ['coordinates', 'coordinates', '*'] | 5673 | 5674 | float |
| ['coordinates', 'coordinates', '*'] | 1 | 5674 | int |
| ['created_at'] | 4181419 | 4181419 | string |
| ['display_text_range'] | 228832 | 4181419 | array |
| ['display_text_range', '*'] | 457664 | 457664 | int |
| ['entities'] | 4181419 | 4181419 | object |
| ['entities', 'hashtags'] | 4181419 | 4181419 | array |
| ['entities', 'hashtags', '*'] | 1301581 | 1301581 | object |
| ['entities', 'hashtags', '*', 'indices'] | 1301581 | 1301581 | array |
| ['entities', 'hashtags', '*', 'indices', '*'] | 2603162 | 2603162 | int |
| ['entities', 'hashtags', '*', 'text'] | 1301581 | 1301581 | string |
| ['entities', 'user_mentions'] | 4181419 | 4181419 | array |
+-----------------------------------------------+---------------+---------+-----------+
We will infer from this Sensible Schema that the info seems to have JSON paperwork with nested objects, arrays, and scalars. As well as, it has sparse fields and fields of blended varieties.
The sector that appears most related right here is entities.hashtags, which is nested inside an object known as entities. Word that to entry nested fields inside objects, we concatenate the sphere names with a . (dot) as a separator. Let’s discover the array subject entities.hashtags additional to grasp its form.
entities.hashtags is an array of objects. Every of those objects has a subject known as indices, which is an array of integers, and a subject known as textual content, which is a string. Additionally, not all of the paperwork which have the entities.hashtags array have nested objects inside it, as is obvious from the occurrences of the nested objects inside entities.hashtags being lesser than the occurrences of entities.hashtags.
Listed here are 2 pattern hashtags objects from 2 paperwork within the assortment:
{
"hashtags": [
{ "text": "AmazonMusic",
"indices": [ 15, 27 ]
},
{ "textual content": "ジョニ・ミッチェル",
"indices": [ 33, 43 ]
},
{ "textual content": "Blue",
"indices": [ 46, 51 ]
}
]
}
{
"hashtags": []
}
One doc has the sphere hashtags with an array of nested objects, and the opposite doc has hashtags with an empty array.
The sector textual content nested contained in the entities.hashtags array is the one we’re fascinated with. Word that textual content is a SQL NULL or undefined in paperwork the place entities.hashtags is an empty array. We will use the IS NOT NULL predicate to filter out all such values.
So What’s Trending on the Grammys?
Now that we all know what the info seems to be like, let’s construct a easy question to get just a few textual content fields within the hashtags. Rockset treats arrays as digital collections. When utilizing a nested array as a goal assortment in queries we use the delimiter : (colon) as a separator between the basis assortment and the nested fields. We will use the sphere entities.hashtags, which is an array, as a goal assortment within the following question:
rockset> SELECT
textual content
FROM
twitter_collection:entities.hashtags AS hashtags
WHERE
textual content IS NOT NULL
LIMIT 5;
+----------------+
| textual content |
|----------------|
| Grammys |
| TearItUpBTS |
| BLINK |
| daSnakZ |
| SNKZ |
+----------------+
Nice! Constructing from right here, a question that lists 5 hashtags within the reducing order of their counts—principally the highest 5 trending hashtags—would seem like this:
rockset> SELECT
textual content AS hashtag
FROM
twitter_collection:entities.hashtags AS hashtags
WHERE
textual content IS NOT NULL
GROUP BY
textual content
ORDER BY
COUNT(*) DESC
LIMIT 5;
+-----------------+
| hashtag |
|-----------------|
| GRAMMYs |
| TearItUpBTS |
| Grammys |
| ROSÉ |
| music |
+-----------------+
Clearly, there was plenty of speak in regards to the Grammys on Twitter and BTS gave the impression to be tearing it up!
Subsequent, I used to be curious whom the Twitterverse was backing on the Grammys. I believed that might correlate with the most well-liked consumer mentions.
With a fast peek on the Sensible Schema snippet above, I see an array subject known as entities.user_mentions that appears related.
Let’s discover the nested array entities.user_mentions additional utilizing DESCRIBE.
rockset> DESCRIBE twitter_collection:entities.user_mentions;
+-----------------------+---------------+----------+-----------+
| subject | occurrences | whole | kind |
|-----------------------+---------------+----------+-----------|
| ['*'] | 1531518 | 1531518 | object |
| ['*', 'id'] | 329 | 1531518 | null_type |
| ['*', 'id'] | 1531189 | 1531518 | int |
| ['*', 'id_str'] | 1531189 | 1531518 | string |
| ['*', 'id_str'] | 329 | 1531518 | null_type |
| ['*', 'indices'] | 1531518 | 1531518 | array |
| ['*', 'indices', '*'] | 3063036 | 3063036 | int |
| ['*', 'name'] | 1531189 | 1531518 | string |
| ['*', 'name'] | 329 | 1531518 | null_type |
| ['*', 'screen_name'] | 1531518 | 1531518 | string |
+-----------------------+---------------+----------+-----------+
entities.user_mentions is an array of nested objects as we will see above.
Probably the most related fields in these nested objects seem like identify and screen_name. Let’s stick to identify for this evaluation. From the Sensible Schema above, we will see that whereas identify is of kind ‘string’ in most paperwork, it’s a JSON NULL(null_type) in just a few paperwork. A JSON NULL shouldn’t be the identical as a SQL NULL. We will filter the JSON NULLs out through the use of Rockset’s typeof perform.
Right here is a straightforward question that lists 5 consumer point out names.
rockset> SELECT
col.identify
FROM
twitter_collection:entities.user_mentions AS col
WHERE
typeof(col.identify) = 'string'
LIMIT 5;
+------------------------------------+
| identify |
|------------------------------------|
| Nina Dobrev |
| H.E.R. |
| nctea |
| StopVientresAlquiler |
| 小林由依1st写真集_3月13日発売_公式 |
+------------------------------------+
To listing the 5 hottest consumer mentions, I am going to display one other technique that includes utilizing UNNEST. I constructed the goal assortment by increasing the user_mentions array utilizing UNNEST and becoming a member of it with twitter_collection. Right here is the absolutely fleshed out question:
rockset> SELECT
consumer.consumer.identify
FROM
twitter_collection AS col,
UNNEST(col.entities.user_mentions AS consumer) AS consumer
WHERE
typeof(consumer.consumer.identify) = 'string'
GROUP BY
consumer.consumer.identify
ORDER BY
COUNT(*) DESC
LIMIT 5;
+---------------------+
| identify |
|---------------------|
| 방탄소년단 |
| Michelle Obama |
| H.E.R. |
| lego |
| BT21 |
+---------------------+
I wanted some assist from Google to translate “방탄소년단” for me.
Though they didn’t win on the Grammys, BTS had clearly gained over the Twitterverse!
And we have gone from information to insights very quickly, utilizing Sensible Schema to assist us perceive what our information is all about. No information prep, no schema modeling, no ETL pipelines.

{kind=link}