
Intro
In recent times, Kafka has grow to be synonymous with “streaming,” and with options like Kafka Streams, KSQL, joins, and integrations into sinks like Elasticsearch and Druid, there are extra methods than ever to construct a real-time analytics utility round streaming information in Kafka. With all of those stream processing and real-time information retailer choices, although, additionally comes questions for when every must be used and what their professionals and cons are. On this publish, I’ll focus on some widespread real-time analytics use-cases that we now have seen with our clients right here at Rockset and the way totally different real-time analytics architectures go well with every of them. I hope by the tip you end up higher knowledgeable and fewer confused in regards to the real-time analytics panorama and are able to dive in to it for your self.
First, an compulsory apart on real-time analytics.
Traditionally, analytics have been performed in batch, with jobs that may run at some specified interval and course of some properly outlined quantity of information. Over the past decade nonetheless, the web nature of our world has led rise to a distinct paradigm of information technology through which there is no such thing as a properly outlined begin or finish to the information. These unbounded “streams” of information are sometimes comprised of buyer occasions from a web-based utility, sensor information from an IoT system, or occasions from an inside service. This shift in the way in which we take into consideration our enter information has necessitated an identical shift in how we course of it. In spite of everything, what does it imply to compute the min or max of an unbounded stream? Therefore the rise of real-time analytics, a self-discipline and methodology for the way to run computation on information from real-time streams to provide helpful outcomes. And since streams additionally have a tendency have a excessive information velocity, real-time analytics is mostly involved not solely with the correctness of its outcomes but in addition its freshness.
Kafka match itself properly into this new motion as a result of it’s designed to bridge information producers and shoppers by offering a scalable, fault-tolerant spine for event-like information to be written to and browse from. Over time as they’ve added options like Kafka Streams, KSQL, joins, Kafka ksqlDB, and integrations with varied information sources and sinks, the barrier to entry has decreased whereas the ability of the platform has concurrently elevated. It’s essential to additionally word that whereas Kafka is sort of highly effective, there are numerous issues it self-admittedly will not be. Particularly, it isn’t a database, it isn’t transactional, it isn’t mutable, its question language KSQL will not be totally SQL-compliant, and it isn’t trivial to setup and preserve.
Now that we’ve settled that, let’s take into account just a few widespread use instances for Kafka and see the place stream processing or a real-time database may fit. We’ll focus on what a pattern structure may seem like for every.
Use Case 1: Easy Filtering and Aggregation
A quite common use case for stream processing is to supply primary filtering and predetermined aggregations on prime of an occasion stream. Let’s suppose we now have clickstream information coming from a client internet utility and we need to decide the variety of homepage visits per hour.
To perform this we are able to use Kafka streams and KSQL. Our internet utility writes occasions right into a Kafka matter referred to as clickstream. We are able to then create a Kafka stream primarily based on this matter that filters out all occasions the place endpoint != '/' and applies a sliding window with an interval of 1 hour over the stream and computes a rely(*). This ensuing stream can then dump the emitted information into your sink of alternative– S3/GCS, Elasticsearch, Redis, Postgres, and many others. Lastly your inside utility/dashboard can pull the metrics from this sink and show them nonetheless you want.
Word: Now with ksqlDB you possibly can have a materialized view of a Kafka stream that’s instantly queryable, so chances are you’ll not essentially must dump it right into a third-party sink.

This sort of setup is form of the “hey world” of Kafka streaming analytics. It’s so easy however will get the job accomplished, and consequently this can be very widespread in real-world implementations.
Professionals:
- Easy to setup
- Quick queries on the sinks for predetermined aggregations
Cons:
- You must outline a Kafka stream’s schema at stream creation time, which means future modifications within the utility’s occasion payload may result in schema mismatches and runtime points
- There’s no alternate method to slice the information after-the-fact (i.e. views/minute)
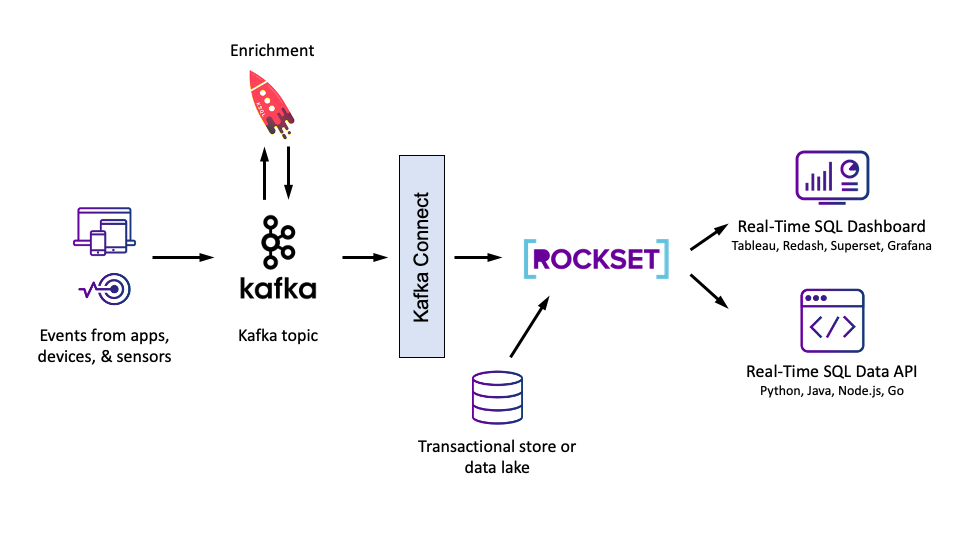
Use Case 2: Enrichment
The following use case we’ll take into account is stream enrichment– the method of denormalizing stream information to make downstream analytics less complicated. That is generally referred to as a “poor man’s be part of” since you are successfully becoming a member of the stream with a small, static dimension desk (from SQL parlance). For instance, let’s say the identical clickstream information from earlier than contained a subject referred to as countryId. Enrichment may contain utilizing the countryId to search for the corresponding nation title, nationwide language, and many others. and inject these further fields into the occasion. This is able to then allow downstream purposes that have a look at the information to compute, for instance, the variety of non-native English audio system who load the English model of the web site.
To perform this, step one is to get our dimension desk mapping countryId to call and language accessible in Kafka. Since every thing in Kafka is a subject, even this information should be written to some new matter, let’s say referred to as international locations. Then we have to create a KSQL desk on prime of that matter utilizing the CREATE TABLE KSQL DDL. This requires the schema and first key be specified at creation time and can materialize the subject as an in-memory desk the place the newest report for every distinctive major key worth is represented. If the subject is partitioned, KSQL may be good right here and partition this in-memory desk as properly, which can enhance efficiency. Underneath the hood, these in-memory tables are literally cases of RocksDB, an extremely highly effective, embeddable key worth retailer created at Fb by the identical engineers who’ve now constructed Rockset (small world!).
Then, like earlier than, we have to create a Kafka stream on prime of the clickstream Kafka matter. Let’s name this stream S. Then utilizing some SQL-like semantics, we are able to outline one other stream, let’s name it T which would be the output of the be part of between that Kafka stream and our Kafka desk from above. For every report in our stream S, it would lookup the countryId within the Kafka desk we outlined and add the countryName and language fields to the report and emit that report to stream T.

Professionals:
- Downstream purposes now have entry to fields from a number of sources multi functional place
Cons:
- Kafka desk is simply keyed on one subject, so joins for an additional subject require creating one other desk on the identical information that’s keyed in another way
- Kafka desk being in-memory means dimension tables have to be small-ish
- Early materialization of the be part of can result in stale information. For instance if we had a userId subject that we have been attempting to affix on to complement the report with the consumer’s complete visits, the information in stream
Twouldn’t replicate the up to date worth of the consumer’s visits after the enrichment takes place
Use Case 3: Actual-Time Databases
The following step within the maturation of streaming analytics is to start out operating extra intricate queries that deliver collectively information from varied sources. For instance, let’s say we need to analyze our clickstream information in addition to information about our promoting campaigns to find out the way to most successfully spend our advert {dollars} to generate a rise in site visitors. We’d like entry to information from Kafka, our transactional retailer (i.e. Postgres), and perhaps even information lake (i.e. S3) to tie collectively all the size of our visits.
To perform this we have to decide an end-system that may ingest, index, and question all these information. Since we need to react in real-time to traits, a knowledge warehouse is out of query since it might take too lengthy to ETL the information there after which attempt to run this evaluation. A database like Postgres additionally wouldn’t work since it’s optimized for level queries, transactions, and comparatively small information sizes, none of that are related/superb for us.
You might argue that the method in use case #2 may fit right here since we are able to arrange one connector for every of our information sources, put every thing in Kafka matters, create a number of ksqlDBs, and arrange a cluster of Kafka streams purposes. Whilst you may make that work with sufficient brute power, if you wish to assist ad-hoc slicing of your information as an alternative of simply monitoring metrics, in case your dashboards and purposes evolve with time, or if you would like information to at all times be recent and by no means stale, that method gained’t reduce it. We successfully want a read-only duplicate of our information from its varied sources that helps quick queries on massive volumes of information; we want a real-time database.
Professionals:
- Help ad-hoc slicing of information
- Combine information from quite a lot of sources
- Keep away from stale information
Cons:
- One other service in your infrastructure
- One other copy of your information
Actual-Time Databases
Fortunately we now have just a few good choices for real-time database sinks that work with Kafka.
The primary possibility is Apache Druid, an open-source columnar database. Druid is nice as a result of it may well scale to petabytes of information and is very optimized for aggregations. Sadly although it doesn’t assist joins, which implies to make this work we should carry out the enrichment forward of time in another service earlier than dumping the information into Druid. Additionally, its structure is such that spikes in new information being written can negatively have an effect on queries being served.
The following possibility is Elasticsearch which has grow to be immensely well-liked for log indexing and search, in addition to different search-related purposes. For level lookups on semi-structured or unstructured information, Elasticsearch could also be the best choice on the market. Like Druid, you’ll nonetheless must pre-join the information, and spikes in writes can negatively affect queries. In contrast to Druid, Elasticsearch gained’t be capable of run aggregations as rapidly, and it has its personal visualization layer in Kibana, which is intuitive and nice for exploratory level queries.
The ultimate possibility is Rockset, a serverless real-time database that helps totally featured SQL, together with joins, on information from quite a lot of sources. With Rockset you possibly can be part of a Kafka stream with a CSV file in S3 with a desk in DynamoDB in real-time as in the event that they have been all simply common tables in the identical SQL database. No extra stale, pre-joined information! Nevertheless Rockset isn’t open supply and gained’t scale to petabytes like Druid, and it’s not designed for unstructured textual content search like Elastic.
Whichever possibility we decide, we are going to arrange our Kafka matter as earlier than and this time join it utilizing the suitable sink connector to our real-time database. Different sources can even feed instantly into the database, and we are able to level our dashboards and purposes to this database as an alternative of on to Kafka. For instance, with Rockset, we may use the net console to arrange our different integrations with S3, DynamoDB, Redshift, and many others. Then by way of Rockset’s on-line question editor, or by way of the SQL-over-REST protocol, we are able to begin querying all of our information utilizing acquainted SQL. We are able to then go forward and use a visualization device like Tableau to create a dashboard on prime of our Kafka stream and our different information sources to higher view and share our findings.
For a deeper dive evaluating these three, take a look at this weblog.

Placing It Collectively
Within the earlier sections, we checked out stream processing and real-time databases, and when finest to make use of them at the side of Kafka. Stream processing, with KSQL and Kafka Streams, must be your alternative when performing filtering, cleaning, and enrichment, whereas utilizing a real-time database sink, like Rockset, Elasticsearch, or Druid, is sensible in case you are constructing information purposes that require extra advanced analytics and advert hoc queries.
You might conceivably make use of each in your analytics stack in case your necessities contain each filtering/enrichment and complicated analytic queries. For instance, we may use KSQL to complement our clickstreams with geospatial information and in addition use Rockset as a real-time database downstream, bringing in buyer transaction and advertising information, to serve an utility making suggestions to customers on our web site.

Hopefully the use instances mentioned above have resonated with an actual drawback you are attempting to unravel. Like another expertise, Kafka may be extraordinarily highly effective when used accurately and intensely clumsy when not. I hope you now have some extra readability on the way to method a real-time analytics structure and will probably be empowered to maneuver your group into the information future.

{kind=link}