

Background
The single desk design for DynamoDB simplifies the structure required for storing information in DynamoDB. As a substitute of getting a number of tables for every document kind you may mix the various kinds of information right into a single desk. This works as a result of DynamoDB is ready to retailer very large tables with various schema. DynamoDB additionally helps nested objects. This enables customers to mix PK because the partition key, SK as the kind key with the mix of the 2 changing into a composite main key. Widespread columns can be utilized throughout document varieties like a outcomes column or information column that shops nested JSON. Or the completely different document varieties can have completely completely different columns. DynamoDB helps each fashions, and even a mixture of shared columns and disparate columns. Oftentimes customers following the only desk mannequin will use the PK as a main key inside an SK which works as a namespace. An instance of this:

Discover that the PK is identical for each data, however the SK is completely different. You possibly can think about a two desk mannequin like the next:

and

Whereas neither of those information fashions is definitely an excellent instance of correct information modeling, the instance nonetheless represents the thought. The only desk mannequin makes use of PK as a main Key throughout the namespace of an SK.
Easy methods to use the only desk mannequin in Rockset
Rockset is a real-time analytics database that’s usually used along side DynamoDB. It syncs with information in DynamoDB to supply a simple approach to carry out queries for which DynamoDB is much less suited. Be taught extra in Alex DeBrie’s weblog on DynamoDB Filtering and Aggregation Queries Utilizing SQL on Rockset.
Rockset has 2 methods of making integrations with DynamoDB. The primary is to use RCUs to scan the DynamoDB desk, and as soon as the preliminary scan is full Rockset tails DynamoDB streams. The opposite technique makes use of DynamoDB export to S3 to first export the DynamoDB desk to S3, carry out a bulk ingestion from S3 after which, after export, Rockset will begin tailing the DynamoDB streams. The primary technique is used for when tables are very small, < 5GB, and the second is way more performant and works for bigger DynamoDB tables. Both technique is acceptable for the only desk technique.
Reminder: Rollups can’t be used on DDB.
As soon as the mixing is ready up you have got a number of choices to think about when configuring the Rockset collections.
Technique 1: Assortment and Views
The primary and easiest is to ingest all the desk right into a single assortment and implement views on prime of Rockset. So within the above instance you’ll have a SQL transformation that appears like:
-- new_collection
choose i.* from _input i
And you’ll construct two views on prime of the gathering.
-- consumer view
Choose c.* from new_collection c the place c.SK = 'Consumer';
and
--class view
choose c.* from new_collection c the place c.SK='Class';
That is the best method and requires the least quantity of information concerning the tables, desk schema, sizes, entry patterns, and so on. Usually for smaller tables, we begin right here. Reminder: views are syntactic sugar and won’t materialize information, in order that they have to be processed like they’re a part of the question for each execution of the question.
Technique 2: Clustered Assortment and Views
This technique is similar to the primary technique, besides that we’ll implement clustering when making the gathering. With out this, when a question that makes use of Rockset’s column index is run, your complete assortment have to be scanned as a result of there is no such thing as a precise separation of information within the column index. Clustering can have no impression on the inverted index.
The SQL transformation will appear like:
-- clustered_collection
choose i.* from _input i cluster by i.SK
The caveat right here is that clustering does eat extra sources for ingestion, so CPU utilization will probably be increased for clustered collections vs non-clustered collections. The benefit is queries might be a lot quicker.
The views will look the identical as earlier than:
-- consumer view
Choose c.* from new_collection c the place c.SK = 'Consumer';
and
--class view
choose c.* from new_collection c the place c.SK='Class';
Technique 3: Separate Collections
One other technique to think about when constructing collections in Rockset from a DynamoDB single desk mannequin is to create a number of collections. This technique requires extra setup upfront than the earlier two strategies however provides appreciable efficiency advantages. Right here we’ll use the the place clause of our SQL transformation to separate the SKs from DynamoDB into separate collections. This enables us to run queries with out implementing clustering, or implement clustering inside a person SK.
-- Consumer assortment
Choose i.* from _input i the place i.SK='Consumer';
and
-- Class assortment
Choose i.* from _input i the place i.SK='Class';
This technique doesn’t require views as a result of the information is materialized into particular person collections. That is actually useful when splitting out very giant tables the place queries will use mixes of Rockset’s inverted index and column index. The limitation right here is that we’re going to must do a separate export and stream from DynamoDB for every assortment you need to create.
Technique 4: Mixture of Separate Collections and Clustering
The final technique to debate is the mix of the earlier strategies. Right here you’ll get away giant SKs into separate collections and use clustering and a mixed desk with views for the smaller SKs.
Take this dataset:
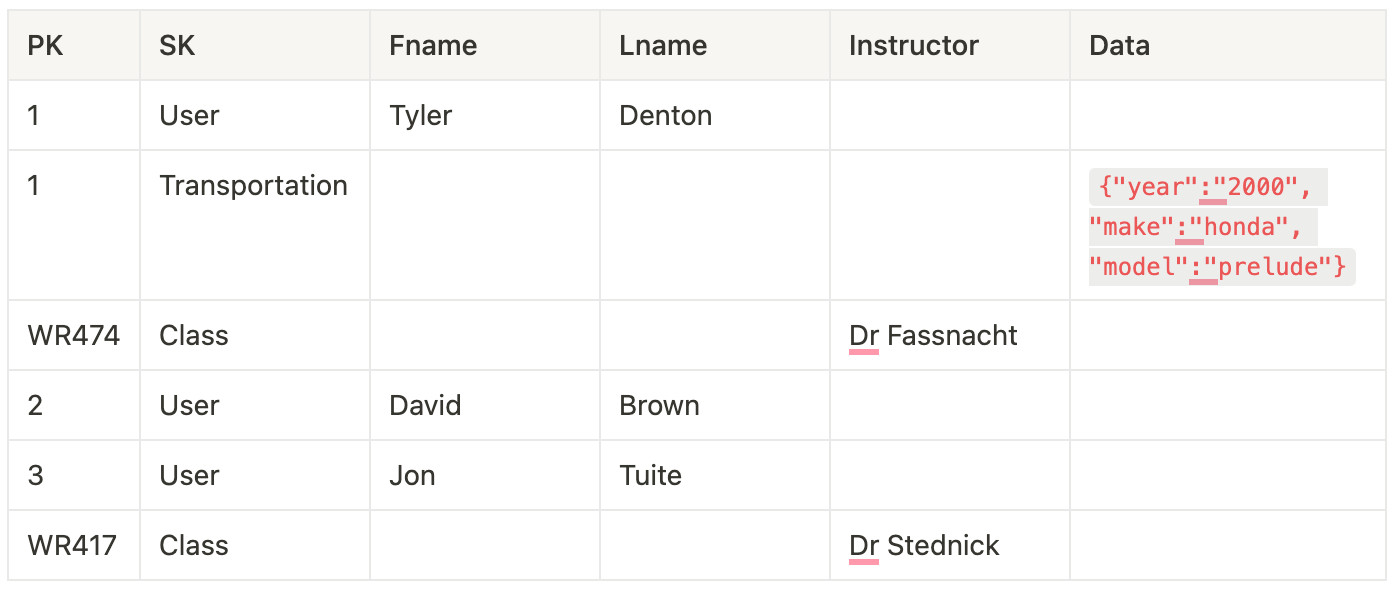
You’ll be able to construct two collections right here:
-- user_collection
choose i.* from _input i the place i.SK='Consumer';
and
-- combined_collection
choose i.* from _input i the place i.SK != 'Consumer' Cluster By SK;
After which 2 views on prime of combined_collection:
-- class_view
choose * from combined_collection the place SK='Class';
and
-- transportation_view
choose * from combined_collection the place SK='Transportation';
This offers you the advantages of separating out the big collections from the small collections, whereas preserving your assortment measurement smaller, permitting different smaller SKs to be added to the DynamoDB desk with out having to recreate and re-ingest the collections. It additionally permits probably the most flexibility for question efficiency. This selection does include probably the most operational overhead to setup, monitor, and preserve.
Conclusion
Single desk design is a well-liked information modeling method in DynamoDB. Having supported quite a few DynamoDB customers via the event and productionization of their real-time analytics functions, we have detailed a number of strategies for organizing your DynamoDB single desk mannequin in Rockset, so you may choose the design that works finest to your particular use case.

{kind=link}