

The typical code pattern comprises 6,000 defects per million traces of code, and the SEI’s analysis has discovered that 5 % of those defects change into vulnerabilities. This interprets to roughly 3 vulnerabilities per 10,000 traces of code. Can ChatGPT assist enhance this ratio? There was a lot hypothesis about how instruments constructed on high of huge language fashions (LLMs) may affect software program growth, extra particularly, how they are going to change the best way builders write code and consider it.
In March 2023 a staff of CERT Safe Coding researchers—the staff included Robert Schiela, David Svoboda, and myself—used ChatGPT 3.5 to look at the noncompliant software program code examples in our CERT Safe Coding normal, particularly the SEI CERT C Coding Normal. On this put up, I current our experiment and findings, which present that whereas ChatGPT 3.5 has promise, there are clear limitations.
Foundations of Our Work in Safe Coding and AI
The CERT Coding Requirements wiki, the place the C normal lives, has greater than 1,500 registered contributors, and coding requirements have been accomplished for C, Java, and C++. Every coding normal contains examples of noncompliant packages that pertain to every rule in an ordinary. The principles within the CERT C Safe Coding normal are organized into 15 chapters damaged down by topic space.
Every rule within the coding normal comprises a number of examples of noncompliant code. These examples are drawn from our expertise in evaluating program supply code and symbolize quite common programming errors that may result in weaknesses and vulnerabilities in packages, in contrast to artificially generated take a look at suites, comparable to Juliet. Every instance error is adopted by a number of compliant options, that illustrate how one can carry the code into compliance. The C Safe Coding Normal has a whole lot of examples of noncompliant code, which offered us a ready-made database of coding errors to run via ChatGPT 3.5, in addition to fixes that might be used to judge ChatGPT 3.5’s response.
Provided that we may simply entry a large database of coding errors, we determined to research ChatGPT 3.5’s effectiveness in analyzing code. We have been motivated, partly, by the push of many in software program to embrace ChatGPT 3.5 for writing code and fixing bugs within the months following its November 2022 launch by Open AI.
Operating Noncompliant Software program By ChatGPT 3.5
We lately took every of these noncompliant C packages and ran it via ChatGPT 3.5 with the immediate
What’s flawed with this program?
As a part of our experiment, we ran every coding pattern via ChatGPT 3.5 individually, and we submitted every coding error into the instrument as a brand new dialog (i.e., not one of the trials have been repeated). Provided that ChatGPT is generative AI know-how and never compiler know-how, we wished to evaluate its analysis of the code and never its capability to be taught from the coding errors and fixes outlined in our database.
Compilers are deterministic and algorithmic, whereas applied sciences underlying ChatGPT are statistical and evolving. A compiler’s algorithm is mounted and impartial of software program that has been processed. ChatGPT’s response is influenced by the patterns processed throughout coaching.
On the time of our experiment, March 2023, Open AI had educated ChatGPT 3.5 on Web content material as much as a cutoff level of September 2021. (In September 2023, nevertheless, Open AI introduced that ChatGPT may browse the online in real-time and now has entry to present information). Provided that our C Safe Coding Normal has been publicly accessible since 2008, we assume that our examples have been a part of the coaching information used to construct ChatGPT 3.5. Consequently, in principle, ChatGPT 3.5 might need been in a position to determine all noncompliant coding errors contained inside our database. Furthermore, the coding errors included in our C Safe Coding Normal have been all errors which are generally discovered within the wild. Therefore, there have been a major variety of articles posted on-line concerning these errors that ought to have been a part of ChatGPT 3.5’s coaching information.
ChatGPT 3.5 Responses: Easy Examples
The next samples present noncompliant code taken from the CERT Safe Coding wiki, in addition to our staff’s experiments with ChatGPT 3.5 responses in response to our experimental submissions of coding errors.
Because the Determine 1 beneath illustrates, ChatGPT 3.5 carried out nicely with an instance we submitted of a typical coding error: a noncompliant code instance the place two parameters had been switched.

Determine 1: Incorrect code identifies mismatches between arguments and conversion specs. Supply: https://wiki.sei.cmu.edu/confluence/show/c/FIO47-C.+Use+legitimate+format+strings.
ChatGPT 3.5, in its response, appropriately recognized and remedied the noncompliant code and provided the proper answer to the issue:

Determine 2: ChatGPT 3.5 appropriately recognized and remedied the noncompliant code and provided the proper answer to the issue.
Curiously, after we submitted an instance of the noncompliant code that led to the Heartbleed vulnerability, ChatGPT 3.5 didn’t determine that the code contained a buffer over-read, the coding error that led to the vulnerability. As a substitute, it famous that the code was a portion of Heartbleed. This was a reminder that ChatGPT 3.5 doesn’t use compiler-like know-how however slightly generative AI know-how.

Determine 3: ChatGPT 3.5 response to the noncompliant code that led to the Heartbleed vulnerability.
ChatGPT 3.5 Responses that Wanted Adjudicating
With some responses, we wanted to attract on our deep material experience to adjudicate a response. The next noncompliant code pattern and compliant suggestion is from the rule EXP 42-C. Don’t evaluate padding information:

Determine 4: Non-compliant code from the CERT Safe Coding Normal. Supply: https://wiki.sei.cmu.edu/confluence/show/c/EXP42-C.+Do+not+evaluate+padding+information.
Once we submitted the code to ChatGPT 3.5, nevertheless, we acquired the next response.

Determine 5: ChatGPT 3.5’s response recognized the important thing challenge, which was to examine every discipline individually, however expressed ambiguity in regards to the that means of an information construction.
We reasoned that ChatGPT ought to be given credit score for the response as a result of it recognized the important thing challenge, which was the necessity to examine every discipline individually, not your complete reminiscence utilized by the info construction. Additionally, the urged repair was according to one interpretation of the info construction. The confusion appeared to stem from the truth that, in C, there’s ambiguity about what an information construction means. Right here, buffer might be an array of characters, or it may be a string. If it’s a string, ChatGPT 3.5’s response was a greater reply, however it’s nonetheless not the proper reply. If buffer is simply an array of characters, then the response is inaccurate as a result of a string comparability stops when a price of “0” is discovered whereas array components after that time may differ. At face worth, one may conclude that ChatGPT 3.5 made an arbitrary selection that diverged from our personal.
One may have taken a deeper evaluation of this instance to attempt to reply the query of whether or not ChatGPT 3.5 ought to have been in a position to distinguish what “buffer” meant. First, strings are generally pointers, not mounted arrays. Second, the identifier “buffer” is usually related to an array of issues and never a string. There’s a physique of literature in reverse engineering that makes an attempt to recreate identifiers within the authentic supply code by matching patterns noticed in apply with identifiers. Provided that ChatGPT can be analyzing patterns, we imagine that almost all examples of code it discovered most likely used a reputation like “string” (or “identify,” “tackle,” and so on.) for a string, whereas buffer wouldn’t be related to a string. Therefore, one could make the case that ChatGPT 3.5 didn’t appropriately repair the problem fully. In these situations, we often gave ChatGPT 3.5 the advantage of the doubt although a novice simply chopping and pasting would wind up introducing different errors.
Instances The place ChatGPT 3.5 Missed Apparent Coding Errors
In different situations, we fed in samples of noncompliant code, and ChatGPT 3.5 missed apparent errors.

Determine 6: Examples of ChatGPT 3.5 responses the place it missed apparent errors in non-compliant code. Supply: DCL38-C is https://wiki.sei.cmu.edu/confluence/show/c/DCL38-C.+Use+the+appropriate+syntax+when+declaring+a+versatile+array+member; DCL39-C is https://wiki.sei.cmu.edu/confluence/show/c/DCL39-C.+Keep away from+data+leakage+when+passing+a+construction+throughout+a+belief+boundary; and EXP33-C is https://wiki.sei.cmu.edu/confluence/show/c/EXP33-C.+Do+not+learn+uninitialized+reminiscence.
In but different situations, ChatGPT 3.5 centered on a trivial challenge however missed the true challenge, as outlined in the instance beneath. (As an apart: additionally be aware that the urged repair to make use of snprintf was already within the authentic code.)

Determine 7: An instance of a noncompliant code instance the place ChatGPT 3.5 missed the primary error and centered on a trivial challenge.
Supply: https://wiki.sei.cmu.edu/confluence/pages/viewpage.motion?pageId=87152177.
As outlined within the safe coding rule for this error,
Use of the system() operate may end up in exploitable vulnerabilities, within the worst case permitting execution of arbitrary system instructions. Conditions through which calls to system() have excessive threat embody the next:
- when passing an unsanitized or improperly sanitized command string originating from a tainted supply
- if a command is specified with out a path identify and the command processor path identify decision mechanism is accessible to an attacker
- if a relative path to an executable is specified and management over the present working listing is accessible to an attacker
- if the desired executable program might be spoofed by an attacker
Don’t invoke a command processor by way of system() or equal features to execute a command.
As proven beneath, ChatGPT 3.5 as a substitute recognized a non-existent downside within the code with this name on the snsprintf() and cautioned once more in opposition to a buffer overflow with that decision.
Total Efficiency of ChatGPT 3.5
Because the diagram beneath exhibits, ChatGPT 3.5 appropriately recognized the issue 46.2 % of the time. Greater than half of the time, 52.1 %, ChatGPT 3.5 didn’t determine the coding error in any respect. Curiously, 1.7 % of the time, it flagged a program and famous that there was an issue, however it declared the issue to be an aesthetic one slightly than an error.

Determine 8: Total, we discovered that ChatGPT 3.5 appropriately recognized noncompliant code 46.2 % of the time.
We may additionally study a bit extra element to see if there have been explicit sorts of errors that ChatGPT 3.5 was both higher or worse at figuring out and correcting. The chart beneath exhibits efficiency damaged out by the characteristic concerned.
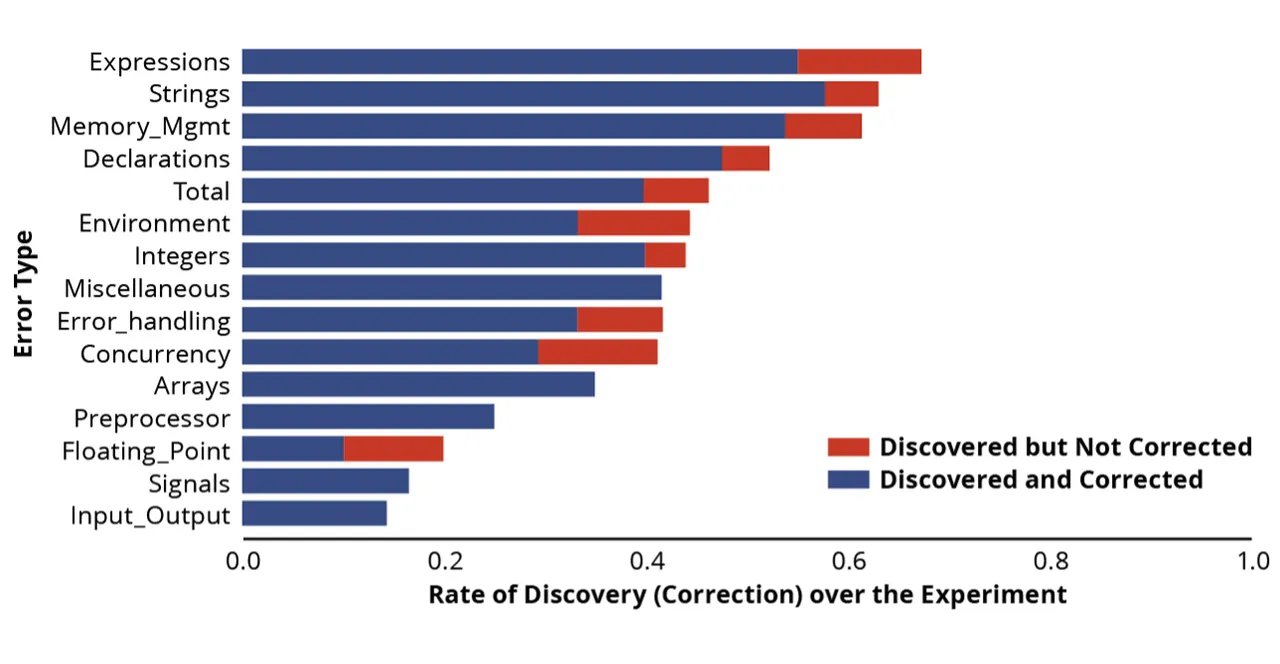
Determine 9: Total Outcomes by Function Examined
Because the bar graph above illustrates, primarily based on our evaluation, ChatGPT 3.5 appeared notably adept at
- discovering and fixing integers
- discovering and fixing expressions
- discovering and fixing reminiscence administration
- discovering and fixing strings
ChatGPT 3.5 appeared most challenged by coding errors that included
- discovering the floating level
- discovering the enter/output
- discovering alerts
We surmised that ChatGPT 3.5 was higher versed in points comparable to discovering and fixing integer, reminiscence administration, and string errors, as a result of these points have been nicely documented all through the Web. Conversely, there has not been as a lot written about floating level errors and alerts, which might give ChatGPT 3.5 fewer sources from which to be taught.
The ChatGPT Future
These outcomes of our evaluation present that ChatGPT 3.5 has promise, however there are clear limitations. The mechanism utilized by LLMs closely is dependent upon sample matching primarily based on coaching information. It’s outstanding that utilizing patterns of completion – “what’s the subsequent phrase” – can carry out detailed program evaluation when educated with a big sufficient corpus. The implications are three-fold:
- One may anticipate that solely the commonest sorts of patterns could be discovered and utilized. This expectation is mirrored within the earlier information, the place generally mentioned errors had a greater price of detection than extra obscure errors. Compiler-based know-how works the identical means no matter an error’s prevalence. Its capability to discover a kind of error is impartial of whether or not the error seems in 1 in 10 packages, a state of affairs closely favored by LLM-based methods, or 1 in 1000.
- One ought to be cautious of the tyranny of the bulk. On this context, LLMs might be fooled into figuring out a typical sample to be an accurate sample. For instance, it’s well-known that programmers reduce and paste code from StackOverflow, and that StackOverflow code has errors, each useful and weak. Giant numbers of programmers who propagate faulty code may present the recurring patterns that an LLM-based system would use to determine a typical (i.e., good) sample.
- One may think about an adversary utilizing the identical tactic to introduce vulnerability that may be generated by the LLM-based system. Having been educated on the weak code as frequent (and subsequently “appropriate” or “most popular”), the system would generate the weak code when requested to offer the desired operate.
LLM-based code evaluation shouldn’t be disregarded solely. Basically, there are methods (comparable to immediate engineering and immediate patterns) to mitigate the challenges listed and extract dependable worth. Analysis on this space is lively and on-going. For examples, updates included in ChaptGPT 4 and CoPilot already present enchancment when utilized to the sorts of safe coding vulnerabilities introduced on this weblog posting. We’re these variations and can replace our outcomes when accomplished. Till these outcomes can be found, educated customers should overview the output to find out if it may be trusted and used.
Our staff’s expertise in instructing safe coding lessons has taught us that builders are sometimes not proficient at reviewing and figuring out bugs within the code of different builders. Primarily based on experiences with repositories like StackOverflow and GitHub, we’re involved about situations the place ChatGPT 3.5 produces a code evaluation and an tried repair, and customers usually tend to reduce and paste it than to find out if it is likely to be incorrect. Within the quick time period, subsequently, a sensible tactic is to handle the tradition that uncritically accepts the outputs of programs like ChatGPT 3.5.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}