

Information lakes have been gaining recognition for storing huge quantities of knowledge from various sources in a scalable and cost-effective approach. Because the variety of knowledge customers grows, knowledge lake directors usually must implement fine-grained entry controls for various consumer profiles. They may want to limit entry to sure tables or columns relying on the kind of consumer making the request. Additionally, companies typically need to make knowledge accessible to exterior purposes however aren’t positive how to take action securely. To handle these challenges, organizations can flip to GraphQL and AWS Lake Formation.
GraphQL supplies a robust, safe, and versatile approach to question and retrieve knowledge. AWS AppSync is a service for creating GraphQL APIs that may question a number of databases, microservices, and APIs from one unified GraphQL endpoint.
Information lake directors can use Lake Formation to control entry to knowledge lakes. Lake Formation affords fine-grained entry controls for managing consumer and group permissions on the desk, column, and cell stage. It could due to this fact guarantee knowledge safety and compliance. Moreover, this Lake Formation integrates with different AWS companies, corresponding to Amazon Athena, making it excellent for querying knowledge lakes by means of APIs.
On this publish, we display the way to construct an software that may extract knowledge from a knowledge lake by means of a GraphQL API and ship the outcomes to various kinds of customers primarily based on their particular knowledge entry privileges. The instance software described on this publish was constructed by AWS Associate NETSOL Applied sciences.
Answer overview
Our answer makes use of Amazon Easy Storage Service (Amazon S3) to retailer the information, AWS Glue Information Catalog to accommodate the schema of the information, and Lake Formation to offer governance over the AWS Glue Information Catalog objects by implementing role-based entry. We additionally use Amazon EventBridge to seize occasions in our knowledge lake and launch downstream processes. The answer structure is proven within the following diagram.
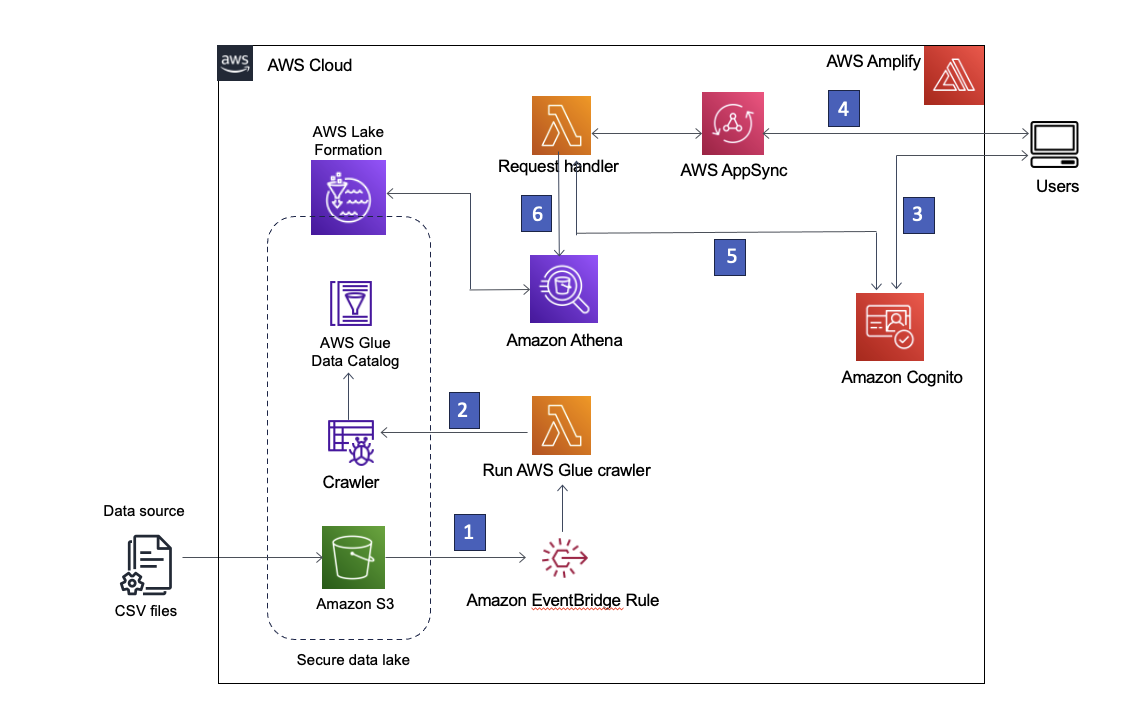
Determine 1 – Answer structure
The next is a step-by-step description of the answer:
- The info lake is created in an S3 bucket registered with Lake Formation. Each time new knowledge arrives, an EventBridge rule is invoked.
- The EventBridge rule runs an AWS Lambda operate to begin an AWS Glue crawler to find new knowledge and replace any schema adjustments in order that the most recent knowledge could be queried.
Observe: AWS Glue crawlers can be launched instantly from Amazon S3 occasions, as described on this weblog publish. - AWS Amplify permits customers to register utilizing Amazon Cognito as an id supplier. Cognito authenticates the consumer’s credentials and returns entry tokens.
- Authenticated customers invoke an AWS AppSync GraphQL API by means of Amplify, fetching knowledge from the information lake. A Lambda operate is run to deal with the request.
- The Lambda operate retrieves the consumer particulars from Cognito and assumes the AWS Id and Entry Administration (IAM) function related to the requesting consumer’s Cognito consumer group.
- The Lambda operate then runs an Athena question in opposition to the information lake tables and returns the outcomes to AWS AppSync, which then returns the outcomes to the consumer.
Conditions
To deploy this answer, it’s essential to first do the next:
Put together Lake Formation permissions
Sign up to the LakeFormation console and add your self as an administrator. Should you’re signing in to Lake Formation for the primary time, you are able to do this by deciding on Add myself on the Welcome to Lake Formation display screen and selecting Get began as proven in Determine 2.
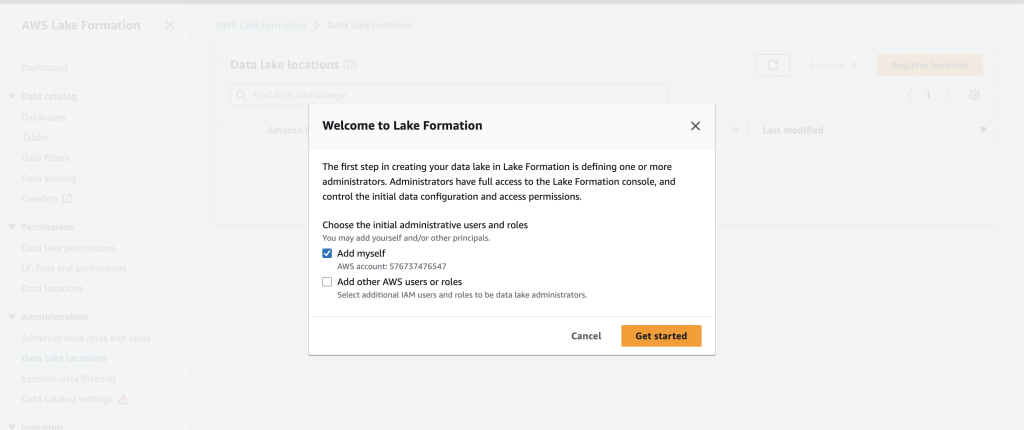
Determine 2 – Add your self because the Lake Formation administrator
In any other case, you’ll be able to select Administrative roles and duties within the left navigation bar and select Handle Directors so as to add your self. It is best to see your IAM username beneath Information lake directors with Full entry when performed.
Choose Information catalog settings within the left navigation bar and ensure the 2 IAM entry management containers will not be chosen, as proven in Determine 3. You need Lake Formation, not IAM, to manage entry to new databases.
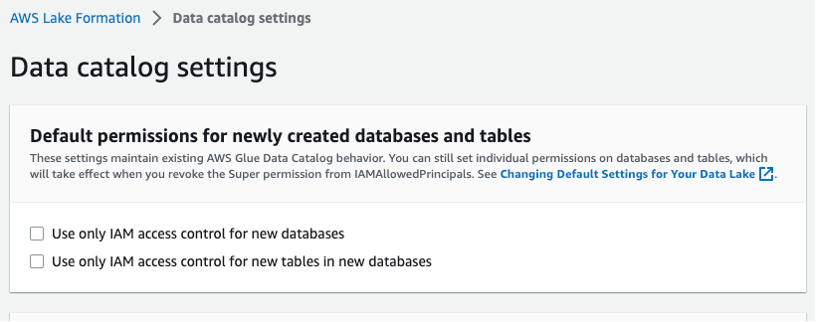
Determine 3 – Lake Formation knowledge catalog settings
Deploy the answer
To create the answer in your AWS surroundings, launch the next AWS CloudFormation stack: ![]()
The next sources shall be launched by means of the CloudFormation template:
- Amazon VPC and networking elements (subnets, safety teams, and NAT gateway)
- IAM roles
- Lake Formation encapsulating S3 bucket, AWS Glue crawler, and AWS Glue database
- Lambda features
- Cognito consumer pool
- AWS AppSync GraphQL API
- EventBridge guidelines
After the required sources have been deployed from the CloudFormation stack, it’s essential to create two Lambda features and add the dataset to Amazon S3. Lake Formation will govern the information lake that’s saved within the S3 bucket.
Create the Lambda features
Each time a brand new file is positioned within the designated S3 bucket, an EventBridge rule is invoked, which launches a Lambda operate to provoke the AWS Glue crawler. The crawler updates the AWS Glue Information Catalog to replicate any adjustments to the schema.
When the appliance makes a question for knowledge by means of the GraphQL API, a request handler Lambda operate is invoked to course of the question and return the outcomes.
To create these two Lambda features, proceed as follows.
- Sign up to the Lambda console.
- Choose the request handler Lambda operate named
dl-dev-crawlerLambdaFunction. - Discover the crawler Lambda operate file in your
lambdas/crawler-lambdafolder within the git repo that you just cloned to your native machine. - Copy and paste the code in that file to the Code part of the
dl-dev-crawlerLambdaFunctionin your Lambda console. Then select Deploy to deploy the operate.
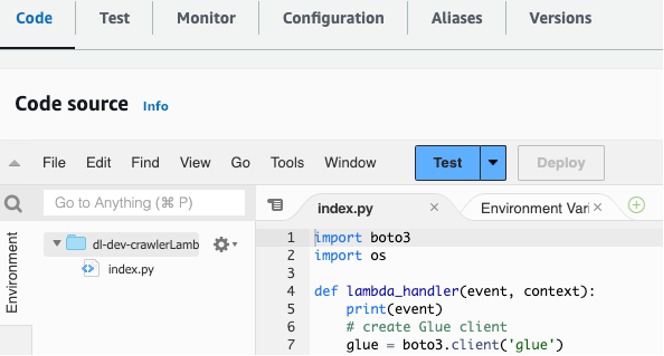
Determine 4 – Copy and paste code into the Lambda operate
- Repeat steps 2 by means of 4 for the request handler operate named
dl-dev-requestHandlerLambdaFunctionutilizing the code inlambdas/request-handler-lambda.
Create a layer for the request handler Lambda
You now should add some extra library code wanted by the request handler Lambda operate.
- Choose Layers within the left menu and select Create layer.
- Enter a reputation corresponding to
appsync-lambda-layer. - Obtain this package deal layer ZIP file to your native machine.
- Add the ZIP file utilizing the Add button on the Create layer web page.
- Select Python 3.7 because the runtime for the layer.
- Select Create.
- Choose Features on the left menu and choose the
dl-dev-requestHandlerLambda operate. - Scroll all the way down to the Layers part and select Add a layer.
- Choose the Customized layers choice after which choose the layer you created above.
- Click on Add.
Add the information to Amazon S3
Navigate to the foundation listing of the cloned git repository and run the next instructions to add the pattern dataset. Change the bucket_name placeholder with the S3 bucket provisioned utilizing the CloudFormation template. You will get the bucket identify from the CloudFormation console by going to the Outputs tab with key datalakes3bucketName as proven in picture beneath.
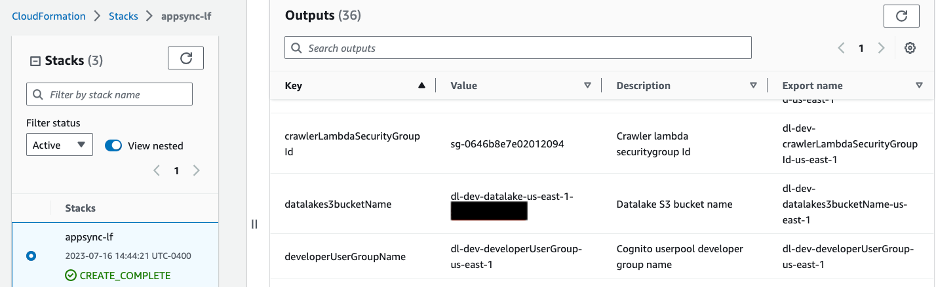
Determine 5 – S3 bucket identify proven in CloudFormation Outputs tab
Enter the next instructions in your mission folder in your native machine to add the dataset to the S3 bucket.
Now let’s check out the deployed artifacts.
Information lake
The S3 bucket holds pattern knowledge for 2 entities: corporations and their respective house owners. The bucket is registered with Lake Formation, as proven in Determine 6. This permits Lake Formation to create and handle knowledge catalogs and handle permissions on the information.

Determine 6 – Lake Formation console exhibiting knowledge lake location
A database is created to carry the schema of knowledge current in Amazon S3. An AWS Glue crawler is used to replace any change in schema within the S3 bucket. This crawler is granted permission to CREATE, ALTER, and DROP tables within the database utilizing Lake Formation.
Apply knowledge lake entry controls
Two IAM roles are created, dl-us-east-1-developer and dl-us-east-1-business-analyst, every assigned to a distinct Cognito consumer group. Every function is assigned completely different authorizations by means of Lake Formation. The Developer function positive aspects entry to each column within the knowledge lake, whereas the Enterprise Analyst function is simply granted entry to the non-personally identifiable data (PII) columns.
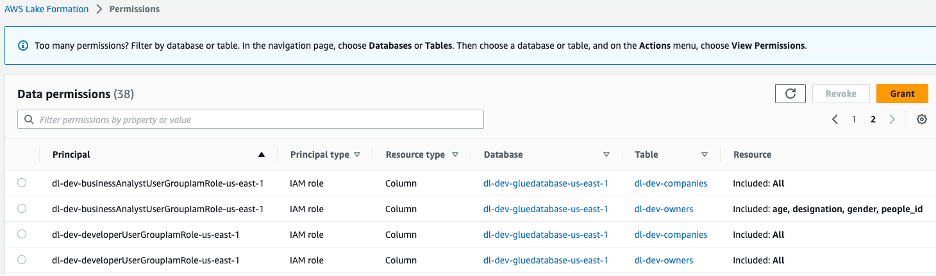
Determine 7 –Lake Formation console knowledge lake permissions assigned to group roles
GraphQL schema
The GraphQL API is viewable from the AWS AppSync console. The Firms sort consists of a number of attributes describing the house owners of the businesses.
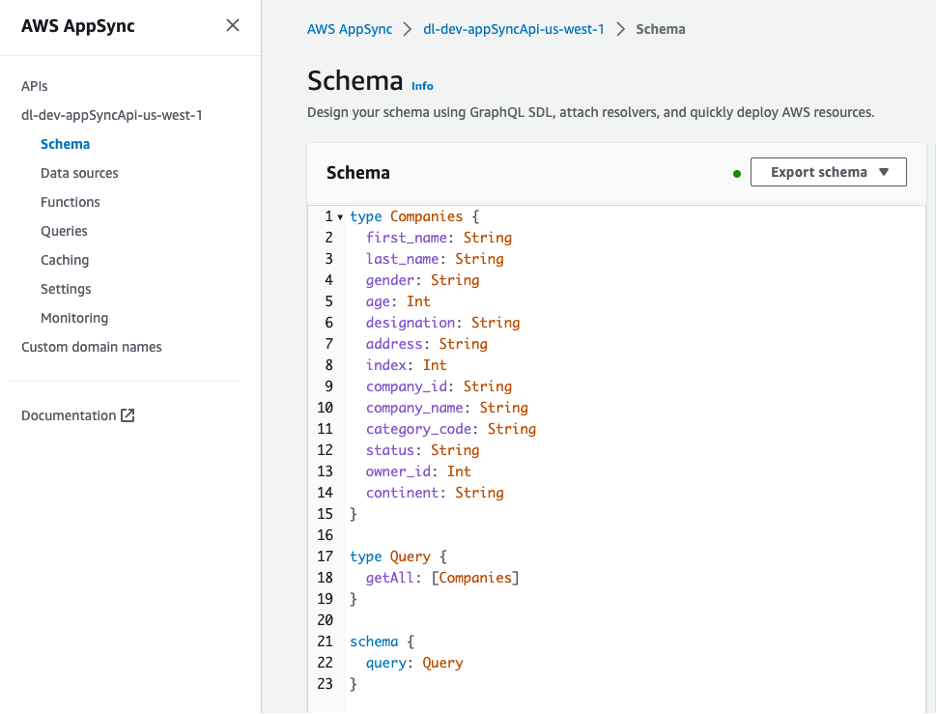
Determine 8 – Schema for GraphQL API
The info supply for the GraphQL API is a Lambda operate, which handles the requests.
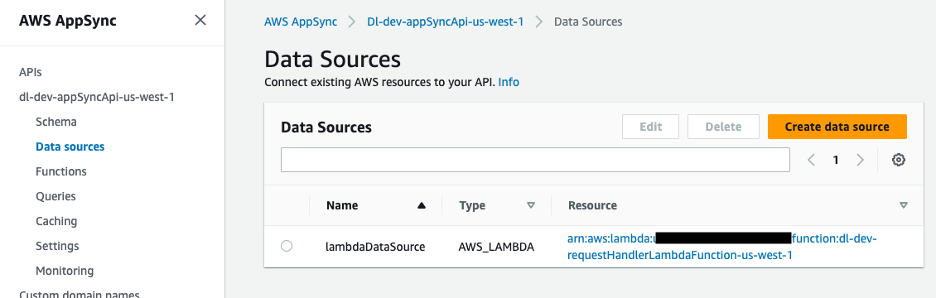
Determine 9 – AWS AppSync knowledge supply mapped to Lambda operate
Dealing with the GraphQL API requests
The GraphQL API request handler Lambda operate retrieves the Cognito consumer pool ID from the surroundings variables. Utilizing the boto3 library, you create a Cognito consumer and use the get_group technique to acquire the IAM function related to the Cognito consumer group.
You utilize a helper operate within the Lambda operate to acquire the function.
Utilizing the AWS Safety Token Service (AWS STS) by means of a boto3 consumer, you’ll be able to assume the IAM function and acquire the momentary credentials you’ll want to run the Athena question.
We move the momentary credentials as parameters when creating our Boto3 Amazon Athena consumer.
athena_client = boto3.consumer('athena', aws_access_key_id=access_key, aws_secret_access_key=secret_key, aws_session_token=session_token)The consumer and question are handed into our Athena question helper operate which executes the question and returns a question id. With the question id, we’re capable of learn the outcomes from S3 and bundle it as a Python dictionary to be returned within the response.
Enabling client-side entry to the information lake
On the consumer aspect, AWS Amplify is configured with an Amazon Cognito consumer pool for authentication. We’ll navigate to the Amazon Cognito console to view the consumer pool and teams that had been created.
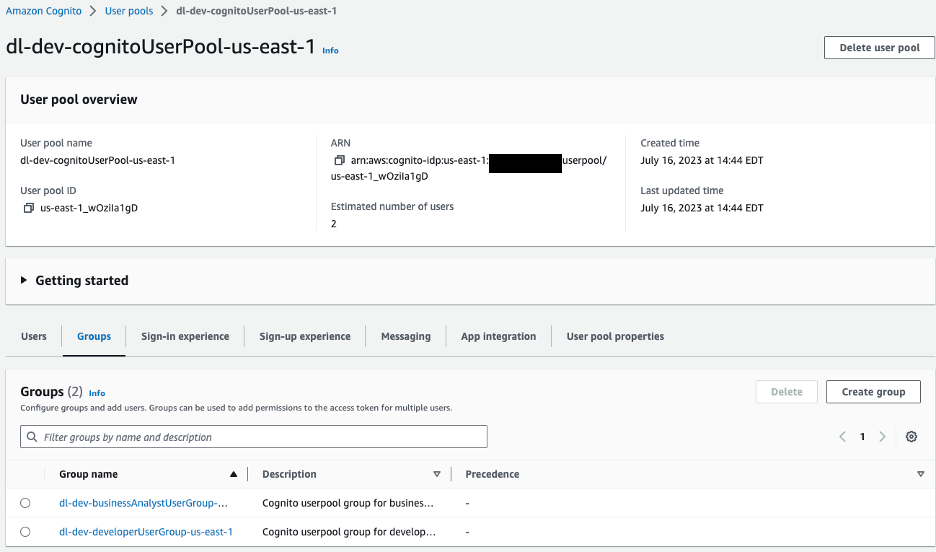
Determine 10 –Amazon Cognito Person swimming pools
For our pattern software we have now two teams in our consumer pool:
dl-dev-businessAnalystUserGroup– Enterprise analysts with restricted permissions.dl-dev-developerUserGroup– Builders with full permissions.
Should you discover these teams, you’ll see an IAM function related to every. That is the IAM function that’s assigned to the consumer once they authenticate. Athena assumes this function when querying the information lake.
Should you view the permissions for this IAM function, you’ll discover that it doesn’t embrace entry controls beneath the desk stage. You want the extra layer of governance offered by Lake Formation so as to add fine-grained entry management.
After the consumer is verified and authenticated by Cognito, Amplify makes use of entry tokens to invoke the AWS AppSync GraphQL API and fetch the information. Based mostly on the consumer’s group, a Lambda operate assumes the corresponding Cognito consumer group function. Utilizing the assumed function, an Athena question is run and the end result returned to the consumer.
Create take a look at customers
Create two customers, one for dev and one for enterprise analyst, and add them to consumer teams.
- Navigate to Cognito and choose the consumer pool,
dl-dev-cognitoUserPool, that’s created. - Select Create consumer and supply the main points to create a brand new enterprise analyst consumer. The username could be biz-analyst. Depart the e-mail deal with clean, and enter a password.
- Choose the Customers tab and choose the consumer you simply created.
- Add this consumer to the enterprise analyst group by selecting the Add consumer to group button.
- Observe the identical steps to create one other consumer with the username developer and add the consumer to the builders group.
Take a look at the answer
To check your answer, launch the React software in your native machine.
- Within the cloned mission listing, navigate to the
react-applisting. - Set up the mission dependencies.
- Set up the Amplify CLI:
- Create a brand new file referred to as
.envby operating the next instructions. Then use a textual content editor to replace the surroundings variable values within the file.
Use the Outputs tab of your CloudFormation console stack to get the required values from the keys as follows:
REACT_APP_APPSYNC_URL |
appsyncApiEndpoint |
REACT_APP_CLIENT_ID |
cognitoUserPoolClientId |
REACT_APP_USER_POOL_ID |
cognitoUserPoolId |
- Add the previous variables to your surroundings.
- Generate the code wanted to work together with the API utilizing Amplify CodeGen. Within the Outputs tab of your Cloudformation console, discover your AWS Appsync API ID subsequent to the
appsyncApiIdkey.
Settle for all of the default choices for the above command by urgent Enter at every immediate.
- Begin the appliance.
You may verify that the appliance is operating by visiting http://localhost:3000 and signing in because the developer consumer you created earlier.
Now that you’ve the appliance operating, let’s check out how every function is served from the corporations endpoint.
First, signal is because the developer function, which has entry to all of the fields, and make the API request to the businesses endpoint. Observe which fields you have got entry to.
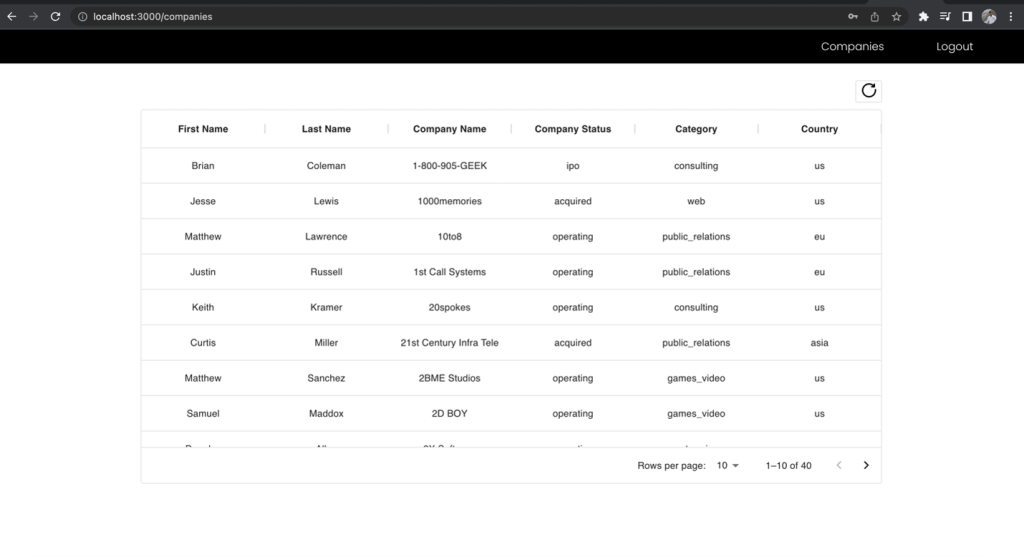
Determine 11 –The outcomes for developer function
Now, register because the enterprise analyst consumer and make the request to the identical endpoint and evaluate the included fields.
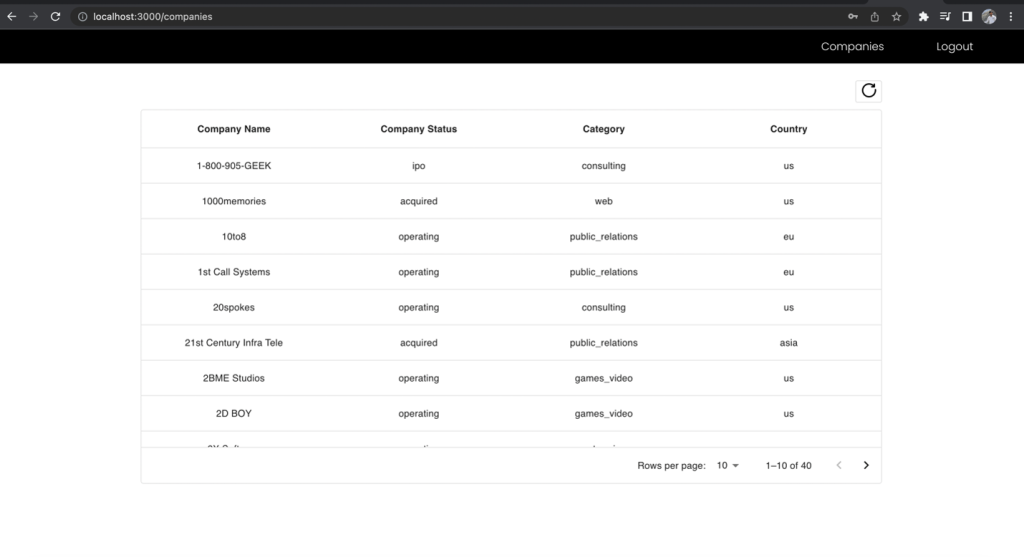
Determine 12 –The outcomes for Enterprise Analyst function
The First Title and Final Title columns of the businesses checklist is excluded within the enterprise analyst view although you made the request to the identical endpoint. This demonstrates the facility of utilizing one unified GraphQL endpoint along with a number of Cognito consumer group IAM roles mapped to Lake Formation permissions to handle role-based entry to your knowledge.
Cleansing up
After you’re performed testing the answer, clear up the next sources to keep away from incurring future fees:
- Empty the S3 buckets created by the CloudFormation template.
- Delete the CloudFormation stack to take away the S3 buckets and different sources.
Conclusion
On this publish, we confirmed you the way to securely serve knowledge in a knowledge lake to authenticated customers of a React software primarily based on their role-based entry privileges. To perform this, you used GraphQL APIs in AWS AppSync, fine-grained entry controls from Lake Formation, and Cognito for authenticating customers by group and mapping them to IAM roles. You additionally used Athena to question the information.
For associated studying on this subject, see Visualizing large knowledge with AWS AppSync, Amazon Athena, and AWS Amplify and Design a knowledge mesh structure utilizing AWS Lake Formation and AWS Glue.
Will you implement this method for serving knowledge out of your knowledge lake? Tell us within the feedback!
Concerning the Authors
 Rana Dutt is a Principal Options Architect at Amazon Internet Companies. He has a background in architecting scalable software program platforms for monetary companies, healthcare, and telecom corporations, and is enthusiastic about serving to clients construct on AWS.
Rana Dutt is a Principal Options Architect at Amazon Internet Companies. He has a background in architecting scalable software program platforms for monetary companies, healthcare, and telecom corporations, and is enthusiastic about serving to clients construct on AWS.
 Ranjith Rayaprolu is a Senior Options Architect at AWS working with clients within the Pacific Northwest. He helps clients design and function Properly-Architected options in AWS that deal with their enterprise issues and speed up the adoption of AWS companies. He focuses on AWS safety and networking applied sciences to develop options within the cloud throughout completely different business verticals. Ranjith lives within the Seattle space and loves outside actions.
Ranjith Rayaprolu is a Senior Options Architect at AWS working with clients within the Pacific Northwest. He helps clients design and function Properly-Architected options in AWS that deal with their enterprise issues and speed up the adoption of AWS companies. He focuses on AWS safety and networking applied sciences to develop options within the cloud throughout completely different business verticals. Ranjith lives within the Seattle space and loves outside actions.
 Justin Leto is a Sr. Options Architect at Amazon Internet Companies with specialization in databases, large knowledge analytics, and machine studying. His ardour helps clients obtain higher cloud adoption. In his spare time, he enjoys offshore crusing and enjoying jazz piano. He lives in New York Metropolis together with his spouse and child daughter.
Justin Leto is a Sr. Options Architect at Amazon Internet Companies with specialization in databases, large knowledge analytics, and machine studying. His ardour helps clients obtain higher cloud adoption. In his spare time, he enjoys offshore crusing and enjoying jazz piano. He lives in New York Metropolis together with his spouse and child daughter.

{kind=link}