

Amazon Redshift is a totally managed, petabyte-scale knowledge warehouse service within the cloud. Tens of hundreds of consumers use Amazon Redshift to course of exabytes of information daily to energy their analytics workloads.
Amazon Redshift has added many options to boost analytical processing like ROLLUP, CUBE and GROUPING SETS, which have been demonstrated within the publish Simplify On-line Analytical Processing (OLAP) queries in Amazon Redshift utilizing new SQL constructs comparable to ROLLUP, CUBE, and GROUPING SETS. Amazon Redshift has just lately added many SQL instructions and expressions. On this publish, we speak about two new SQL options, the MERGE command and QUALIFY clause, which simplify knowledge ingestion and knowledge filtering.
One acquainted job in most downstream purposes is change knowledge seize (CDC) and making use of it to its goal tables. This job requires inspecting the supply knowledge to find out whether it is an replace or an insert to present goal knowledge. With out the MERGE command, you wanted to check the brand new dataset towards the present dataset utilizing a enterprise key. When that didn’t match, you inserted new rows within the present dataset; in any other case, you up to date present dataset rows with new dataset values.
The MERGE command conditionally merges rows from a supply desk right into a goal desk. Historically, this might solely be achieved by utilizing a number of insert, replace, or delete statements individually. When utilizing a number of statements to replace or insert knowledge, there’s a danger of inconsistencies between the totally different operations. Merge operation reduces this danger by making certain that each one operations are carried out collectively in a single transaction.

The QUALIFY clause filters the outcomes of a beforehand computed window perform in line with consumer‑specified search circumstances. You should use the clause to use filtering circumstances to the results of a window perform with out utilizing a subquery. That is just like the HAVING clause, which applies a situation to additional filter rows from a WHERE clause. The distinction between QUALIFY and HAVING is that filtered outcomes from the QUALIFY clause could possibly be based mostly on the results of operating window capabilities on the info. You should use each the QUALIFY and HAVING clauses in a single question.

On this publish, we show how you can use the MERGE command to implement CDC and how you can use QUALIFY to simplify validation of these modifications.
Resolution overview
On this use case, we’ve an information warehouse, during which we’ve a buyer dimension desk that should at all times get the newest knowledge from the supply system. This knowledge should additionally mirror the preliminary creation time and final replace time for auditing and monitoring functions.
A easy approach to resolve that is to override the client dimension absolutely daily; nevertheless, that received’t obtain the replace monitoring, which is an audit mandate, and it won’t be possible to do for larger tables.
You may load pattern knowledge from Amazon S3 by following the instruction right here. Utilizing the present buyer desk underneath sample_data_dev.tpcds, we create a buyer dimension desk and a supply desk that can comprise each updates for present clients and inserts for brand spanking new clients. We use the MERGE command to merge the supply desk knowledge with the goal desk (buyer dimension). We additionally present how you can use the QUALIFY clause to simplify validating the modifications within the goal desk.
To comply with together with the steps on this publish, we suggest downloading the accompanying pocket book, which comprises all of the scripts to run for this publish. To study authoring and operating notebooks, check with Authoring and operating notebooks.
Stipulations
It is best to have the next conditions:
Create and populate the dimension desk
We use the present buyer desk underneath sample_data_dev.tpcds to create a customer_dimension desk. Full the next steps:
- Create a desk utilizing just a few chosen fields, together with the enterprise key, and add a few upkeep fields for insert and replace timestamps:
- Populate the dimension desk:

- Validate the row rely and the contents of the desk:

Simulate buyer desk modifications
Use the next code to simulate modifications made to the desk:

Merge the supply desk into the goal desk
Now you have got a supply desk with some modifications it’s worthwhile to merge with the client dimension desk.
Earlier than the MERGE command, such a job wanted two separate UPDATE and INSERT instructions to implement:
The MERGE command makes use of a extra easy syntax, during which we use the important thing comparability outcome to resolve if we carry out an replace DML operation (when matched) or an insert DML operation (when not matched):

Validate the info modifications within the goal desk
Now we have to validate the info has made it accurately to the goal desk. We are able to first examine the up to date knowledge utilizing the replace timestamp. As a result of this was our first replace, we will look at all rows the place the replace timestamp just isn’t null:
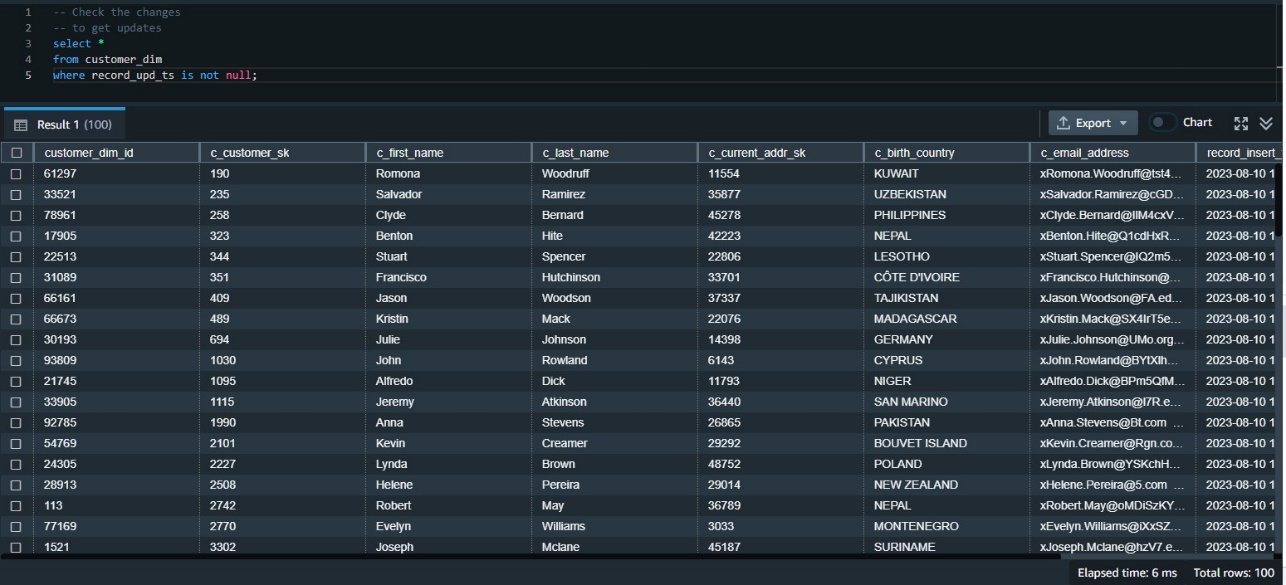
Use QUALIFY to simplify validation of the info modifications
We have to look at the info inserted on this desk most just lately. A technique to do this is to rank the info by its insert timestamp and get these with the primary rank. This requires utilizing the window perform rank() and in addition requires a subquery to get the outcomes.
Earlier than the provision of QUALIFY, we would have liked to construct that utilizing a subquery like the next:
The QUALIFY perform eliminates the necessity for the subquery, as within the following code snippet:
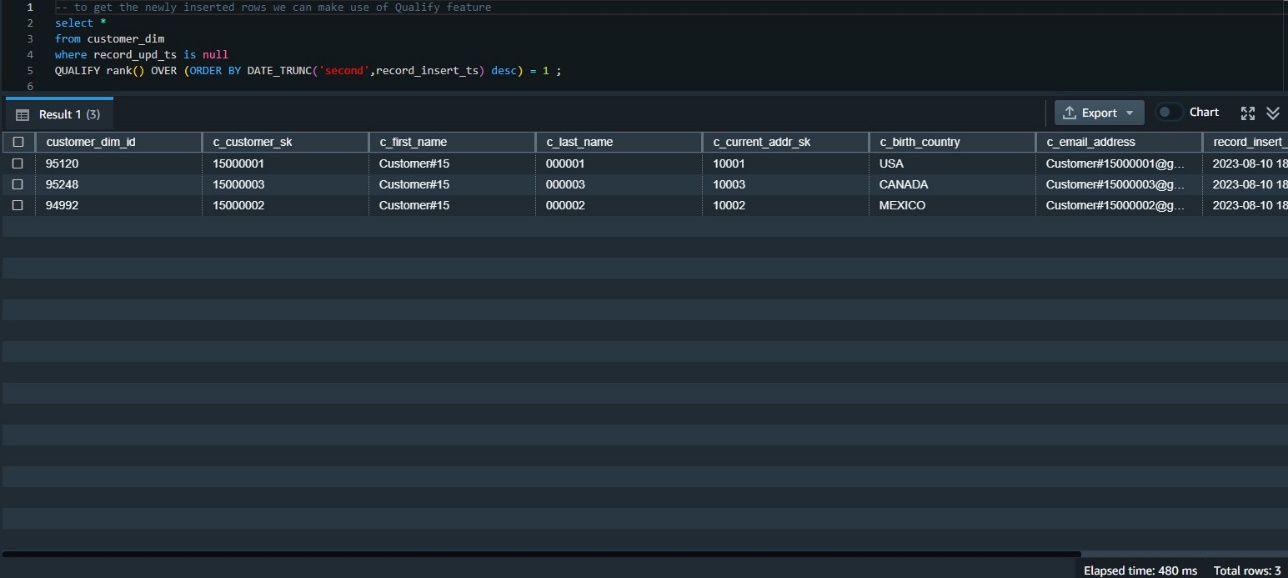
Validate all knowledge modifications
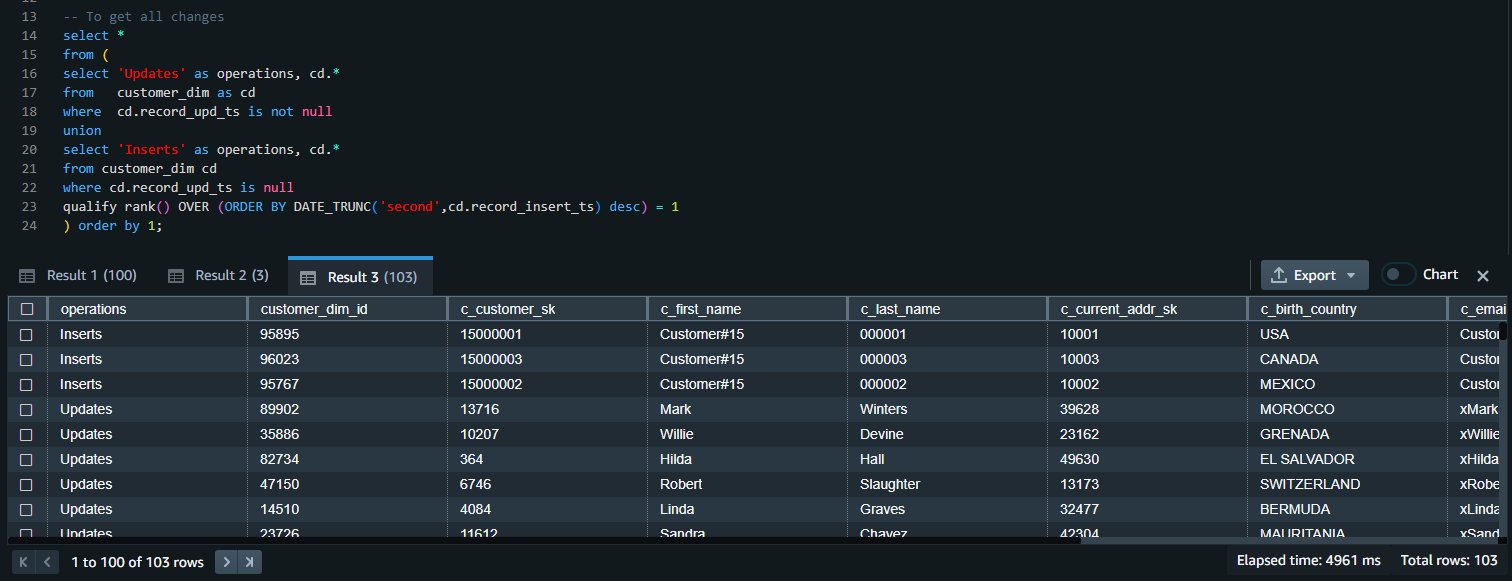
We are able to union the outcomes of each queries to get all of the inserts and replace modifications:
Clear up
To scrub up the sources used within the publish, delete the Redshift provisioned cluster or Redshift Serverless workgroup and namespace you created for this publish (this may also drop all of the objects created).
For those who used an present Redshift provisioned cluster or Redshift Serverless workgroup and namespace, use the next code to drop these objects:
Conclusion
When utilizing a number of statements to replace or insert knowledge, there’s a danger of inconsistencies between the totally different operations. The MERGE operation reduces this danger by making certain that each one operations are carried out collectively in a single transaction. For Amazon Redshift clients who’re migrating from different knowledge warehouse programs or who frequently must ingest fast-changing knowledge into their Redshift warehouse, the MERGE command is an easy approach to conditionally insert, replace, and delete knowledge from goal tables based mostly on present and new supply knowledge.
In most analytic queries that use window capabilities, it’s possible you’ll want to make use of these window capabilities in your WHERE clause as properly. Nonetheless, this isn’t permitted, and to take action, it’s a must to construct a subquery that comprises the required window perform after which use the leads to the mum or dad question within the WHERE clause. Utilizing the QUALIFY clause eliminates the necessity for a subquery and subsequently simplifies the SQL assertion and makes it more easy to jot down and skim.
We encourage you to start out utilizing these new options and provides us your suggestions. For extra particulars, check with MERGE and QUALIFY clause.
In regards to the authors
 Yanzhu Ji is a Product Supervisor within the Amazon Redshift workforce. She has expertise in product imaginative and prescient and technique in industry-leading knowledge merchandise and platforms. She has excellent ability in constructing substantial software program merchandise utilizing net improvement, system design, database, and distributed programming strategies. In her private life, Yanzhu likes portray, images, and taking part in tennis.
Yanzhu Ji is a Product Supervisor within the Amazon Redshift workforce. She has expertise in product imaginative and prescient and technique in industry-leading knowledge merchandise and platforms. She has excellent ability in constructing substantial software program merchandise utilizing net improvement, system design, database, and distributed programming strategies. In her private life, Yanzhu likes portray, images, and taking part in tennis.
 Ahmed Shehata is a Senior Analytics Specialist Options Architect at AWS based mostly on Toronto. He has greater than twenty years of expertise serving to clients modernize their knowledge platforms. Ahmed is captivated with serving to clients construct environment friendly, performant, and scalable analytic options.
Ahmed Shehata is a Senior Analytics Specialist Options Architect at AWS based mostly on Toronto. He has greater than twenty years of expertise serving to clients modernize their knowledge platforms. Ahmed is captivated with serving to clients construct environment friendly, performant, and scalable analytic options.
 Ranjan Burman is an Analytics Specialist Options Architect at AWS. He makes a speciality of Amazon Redshift and helps clients construct scalable analytical options. He has greater than 16 years of expertise in several database and knowledge warehousing applied sciences. He’s captivated with automating and fixing buyer issues with cloud options.
Ranjan Burman is an Analytics Specialist Options Architect at AWS. He makes a speciality of Amazon Redshift and helps clients construct scalable analytical options. He has greater than 16 years of expertise in several database and knowledge warehousing applied sciences. He’s captivated with automating and fixing buyer issues with cloud options.

{kind=link}