
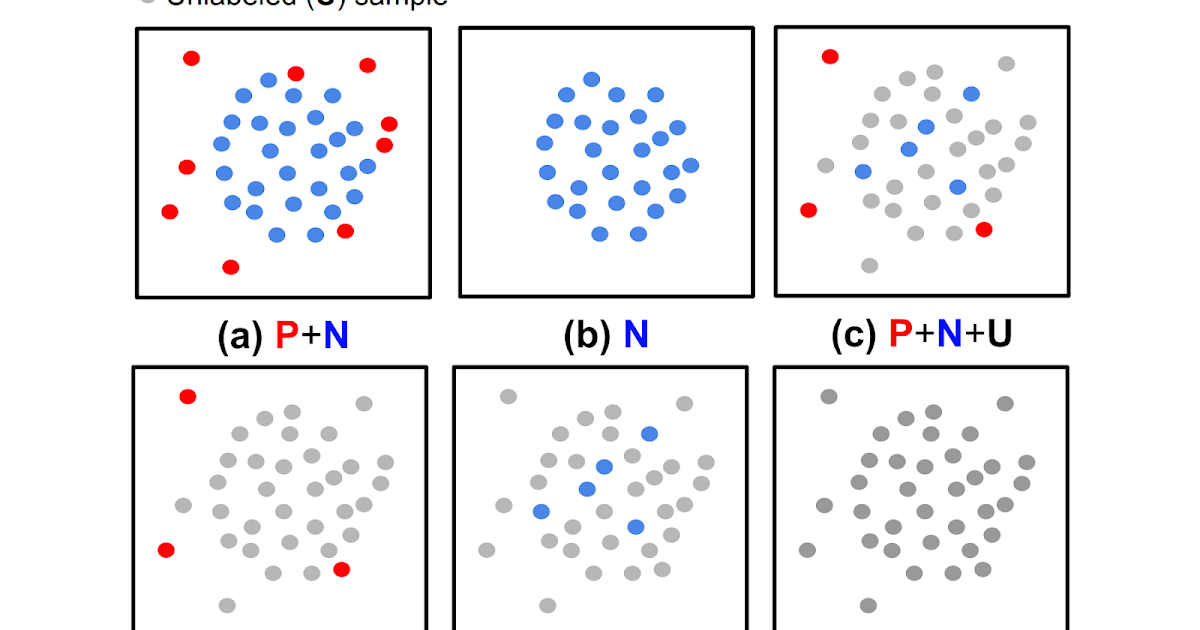

Anomaly detection (AD), the duty of distinguishing anomalies from regular knowledge, performs a significant position in lots of real-world purposes, equivalent to detecting defective merchandise from imaginative and prescient sensors in manufacturing, fraudulent behaviors in monetary transactions, or community safety threats. Relying on the supply of the kind of knowledge — unfavourable (regular) vs. optimistic (anomalous) and the supply of their labels — the duty of AD entails totally different challenges.
 |
| (a) Absolutely supervised anomaly detection, (b) normal-only anomaly detection, (c, d, e) semi-supervised anomaly detection, (f) unsupervised anomaly detection. |
Whereas most earlier works had been proven to be efficient for circumstances with fully-labeled knowledge (both (a) or (b) within the above determine), such settings are much less frequent in observe as a result of labels are significantly tedious to acquire. In most situations customers have a restricted labeling funds, and typically there aren’t even any labeled samples throughout coaching. Moreover, even when labeled knowledge can be found, there might be biases in the way in which samples are labeled, inflicting distribution variations. Such real-world knowledge challenges restrict the achievable accuracy of prior strategies in detecting anomalies.
This put up covers two of our latest papers on AD, revealed in Transactions on Machine Studying Analysis (TMLR), that deal with the above challenges in unsupervised and semi-supervised settings. Utilizing data-centric approaches, we present state-of-the-art ends in each. In “Self-supervised, Refine, Repeat: Enhancing Unsupervised Anomaly Detection”, we suggest a novel unsupervised AD framework that depends on the rules of self-supervised studying with out labels and iterative knowledge refinement based mostly on the settlement of one-class classifier (OCC) outputs. In “SPADE: Semi-supervised Anomaly Detection beneath Distribution Mismatch”, we suggest a novel semi-supervised AD framework that yields strong efficiency even beneath distribution mismatch with restricted labeled samples.
Unsupervised anomaly detection with SRR: Self-supervised, Refine, Repeat
Discovering a choice boundary for a one-class (regular) distribution (i.e., OCC coaching) is difficult in totally unsupervised settings as unlabeled coaching knowledge embrace two lessons (regular and irregular). The problem will get additional exacerbated because the anomaly ratio will get increased for unlabeled knowledge. To assemble a sturdy OCC with unlabeled knowledge, excluding likely-positive (anomalous) samples from the unlabeled knowledge, the method known as knowledge refinement, is vital. The refined knowledge, with a decrease anomaly ratio, are proven to yield superior anomaly detection fashions.
SRR first refines knowledge from an unlabeled dataset, then iteratively trains deep representations utilizing refined knowledge whereas enhancing the refinement of unlabeled knowledge by excluding likely-positive samples. For knowledge refinement, an ensemble of OCCs is employed, every of which is skilled on a disjoint subset of unlabeled coaching knowledge. If there’s consensus amongst all of the OCCs within the ensemble, the information which are predicted to be unfavourable (regular) are included within the refined knowledge. Lastly, the refined coaching knowledge are used to coach the ultimate OCC to generate the anomaly predictions.
 |
| Coaching SRR with an information refinement module (OCCs ensemble), illustration learner, and remaining OCC. (Inexperienced/pink dots signify regular/irregular samples, respectively). |
SRR outcomes
We conduct in depth experiments throughout numerous datasets from totally different domains, together with semantic AD (CIFAR-10, Canine-vs-Cat), real-world manufacturing visible AD (MVTec), and real-world tabular AD benchmarks equivalent to detecting medical (Thyroid) or community safety (KDD 1999) anomalies. We take into account strategies with each shallow (e.g., OC-SVM) and deep (e.g., GOAD, CutPaste) fashions. Because the anomaly ratio of real-world knowledge can range, we consider fashions at totally different anomaly ratios of unlabeled coaching knowledge and present that SRR considerably boosts AD efficiency. For instance, SRR improves greater than 15.0 common precision (AP) with a ten% anomaly ratio in comparison with a state-of-the-art one-class deep mannequin on CIFAR-10. Equally, on MVTec, SRR retains strong efficiency, dropping lower than 1.0 AUC with a ten% anomaly ratio, whereas the finest current OCC drops greater than 6.0 AUC. Lastly, on Thyroid (tabular knowledge), SRR outperforms a state-of-the-art one-class classifier by 22.9 F1 rating with a 2.5% anomaly ratio.
.png) |
| Throughout numerous domains, SRR (blue line) considerably boosts AD efficiency with numerous anomaly ratios in totally unsupervised settings. |
SPADE: Semi-supervised Pseudo-labeler Anomaly Detection with Ensembling
Most semi-supervised studying strategies (e.g., FixMatch, VIME) assume that the labeled and unlabeled knowledge come from the identical distributions. Nevertheless, in observe, distribution mismatch generally happens, with labeled and unlabeled knowledge coming from totally different distributions. One such case is optimistic and unlabeled (PU) or unfavourable and unlabeled (NU) settings, the place the distributions between labeled (both optimistic or unfavourable) and unlabeled (each optimistic and unfavourable) samples are totally different. One other reason for distribution shift is further unlabeled knowledge being gathered after labeling. For instance, manufacturing processes could preserve evolving, inflicting the corresponding defects to alter and the defect varieties at labeling to vary from the defect varieties in unlabeled knowledge. As well as, for purposes like monetary fraud detection and anti-money laundering, new anomalies can seem after the information labeling course of, as felony habits could adapt. Lastly, labelers are extra assured on straightforward samples after they label them; thus, straightforward/troublesome samples usually tend to be included within the labeled/unlabeled knowledge. For instance, with some crowd-sourcing–based mostly labeling, solely the samples with some consensus on the labels (as a measure of confidence) are included within the labeled set.
 |
| Three frequent real-world situations with distribution mismatches (blue field: regular samples, pink field: identified/straightforward anomaly samples, yellow field: new/troublesome anomaly samples). |
Normal semi-supervised studying strategies assume that labeled and unlabeled knowledge come from the identical distribution, so are sub-optimal for semi-supervised AD beneath distribution mismatch. SPADE makes use of an ensemble of OCCs to estimate the pseudo-labels of the unlabeled knowledge — it does this impartial of the given optimistic labeled knowledge, thus lowering the dependency on the labels. That is particularly helpful when there’s a distribution mismatch. As well as, SPADE employs partial matching to robotically choose the vital hyper-parameters for pseudo-labeling with out counting on labeled validation knowledge, a vital functionality given restricted labeled knowledge.
 |
| Block diagram of SPADE with zoom within the detailed block diagram of the proposed pseudo-labelers. |
SPADE outcomes
We conduct in depth experiments to showcase the advantages of SPADE in numerous real-world settings of semi-supervised studying with distribution mismatch. We take into account a number of AD datasets for picture (together with MVTec) and tabular (together with Covertype, Thyroid) knowledge.
SPADE reveals state-of-the-art semi-supervised anomaly detection efficiency throughout a variety of situations: (i) new-types of anomalies, (ii) easy-to-label samples, and (iii) positive-unlabeled examples. As proven under, with new-types of anomalies, SPADE outperforms the state-of-the-art options by 5% AUC on common.
 |
| AD performances with three totally different situations throughout numerous datasets (Covertype, MVTec, Thyroid) when it comes to AUC. Some baselines are solely relevant to some situations. Extra outcomes with different baselines and datasets could be discovered within the paper. |
We additionally consider SPADE on real-world monetary fraud detection datasets: Kaggle bank card fraud and Xente fraud detection. For these, anomalies evolve (i.e., their distributions change over time) and to establish evolving anomalies, we have to preserve labeling for brand new anomalies and retrain the AD mannequin. Nevertheless, labeling can be pricey and time consuming. Even with out further labeling, SPADE can enhance the AD efficiency utilizing each labeled knowledge and newly-gathered unlabeled knowledge.
 |
| AD performances with time-varying distributions utilizing two real-world fraud detection datasets with 10% labeling ratio. Extra baselines could be discovered within the paper. |
As proven above, SPADE constantly outperforms options on each datasets, making the most of the unlabeled knowledge and exhibiting robustness to evolving distributions.
Conclusions
AD has a variety of use circumstances with important significance in real-world purposes, from detecting safety threats in monetary methods to figuring out defective behaviors of producing machines.
One difficult and dear side of constructing an AD system is that anomalies are uncommon and never simply detectable by individuals. To this finish, we have now proposed SRR, a canonical AD framework to allow excessive efficiency AD with out the necessity for guide labels for coaching. SRR could be flexibly built-in with any OCC, and utilized on uncooked knowledge or on trainable representations.
Semi-supervised AD is one other highly-important problem — in lots of situations, the distributions of labeled and unlabeled samples don’t match. SPADE introduces a sturdy pseudo-labeling mechanism utilizing an ensemble of OCCs and a even handed manner of mixing supervised and self-supervised studying. As well as, SPADE introduces an environment friendly method to select vital hyperparameters with out a validation set, a vital part for data-efficient AD.
Total, we reveal that SRR and SPADE constantly outperform the options in numerous situations throughout a number of sorts of datasets.
Acknowledgements
We gratefully acknowledge the contributions of Kihyuk Sohn, Chun-Liang Li, Chen-Yu Lee, Kyle Ziegler, Nate Yoder, and Tomas Pfister.

{kind=link}