
In a latest mission, we have been tasked with designing how we might exchange a
Mainframe system with a cloud native software, constructing a roadmap and a
enterprise case to safe funding for the multi-year modernisation effort
required. We have been cautious of the dangers and potential pitfalls of a Huge Design
Up Entrance, so we suggested our consumer to work on a ‘simply sufficient, and simply in
time’ upfront design, with engineering through the first part. Our consumer
favored our strategy and chosen us as their companion.
The system was constructed for a UK-based consumer’s Knowledge Platform and
customer-facing merchandise. This was a really advanced and difficult process given
the dimensions of the Mainframe, which had been constructed over 40 years, with a
number of applied sciences which have considerably modified since they have been
first launched.
Our strategy is predicated on incrementally shifting capabilities from the
mainframe to the cloud, permitting a gradual legacy displacement fairly than a
“Huge Bang” cutover. In an effort to do that we would have liked to establish locations within the
mainframe design the place we may create seams: locations the place we are able to insert new
conduct with the smallest doable adjustments to the mainframe’s code. We are able to
then use these seams to create duplicate capabilities on the cloud, twin run
them with the mainframe to confirm their conduct, after which retire the
mainframe functionality.
Thoughtworks have been concerned for the primary yr of the programme, after which we handed over our work to our consumer
to take it ahead. In that timeframe, we didn’t put our work into manufacturing, nonetheless, we trialled a number of
approaches that may make it easier to get began extra shortly and ease your individual Mainframe modernisation journeys. This
article offers an outline of the context during which we labored, and descriptions the strategy we adopted for
incrementally shifting capabilities off the Mainframe.
Contextual Background
The Mainframe hosted a various vary of
companies essential to the consumer’s enterprise operations. Our programme
particularly centered on the information platform designed for insights on Customers
in UK&I (United Kingdom & Eire). This explicit subsystem on the
Mainframe comprised roughly 7 million traces of code, developed over a
span of 40 years. It offered roughly ~50% of the capabilities of the UK&I
property, however accounted for ~80% of MIPS (Million directions per second)
from a runtime perspective. The system was considerably advanced, the
complexity was additional exacerbated by area duties and issues
unfold throughout a number of layers of the legacy surroundings.
A number of causes drove the consumer’s resolution to transition away from the
Mainframe surroundings, these are the next:
- Adjustments to the system have been sluggish and costly. The enterprise subsequently had
challenges holding tempo with the quickly evolving market, stopping
innovation. - Operational prices related to operating the Mainframe system have been excessive;
the consumer confronted a industrial danger with an imminent value improve from a core
software program vendor. - While our consumer had the required talent units for operating the Mainframe,
it had confirmed to be laborious to seek out new professionals with experience on this tech
stack, because the pool of expert engineers on this area is proscribed. Moreover,
the job market doesn’t provide as many alternatives for Mainframes, thus folks
will not be incentivised to discover ways to develop and function them.
Excessive-level view of Client Subsystem
The next diagram exhibits, from a high-level perspective, the assorted
elements and actors within the Client subsystem.
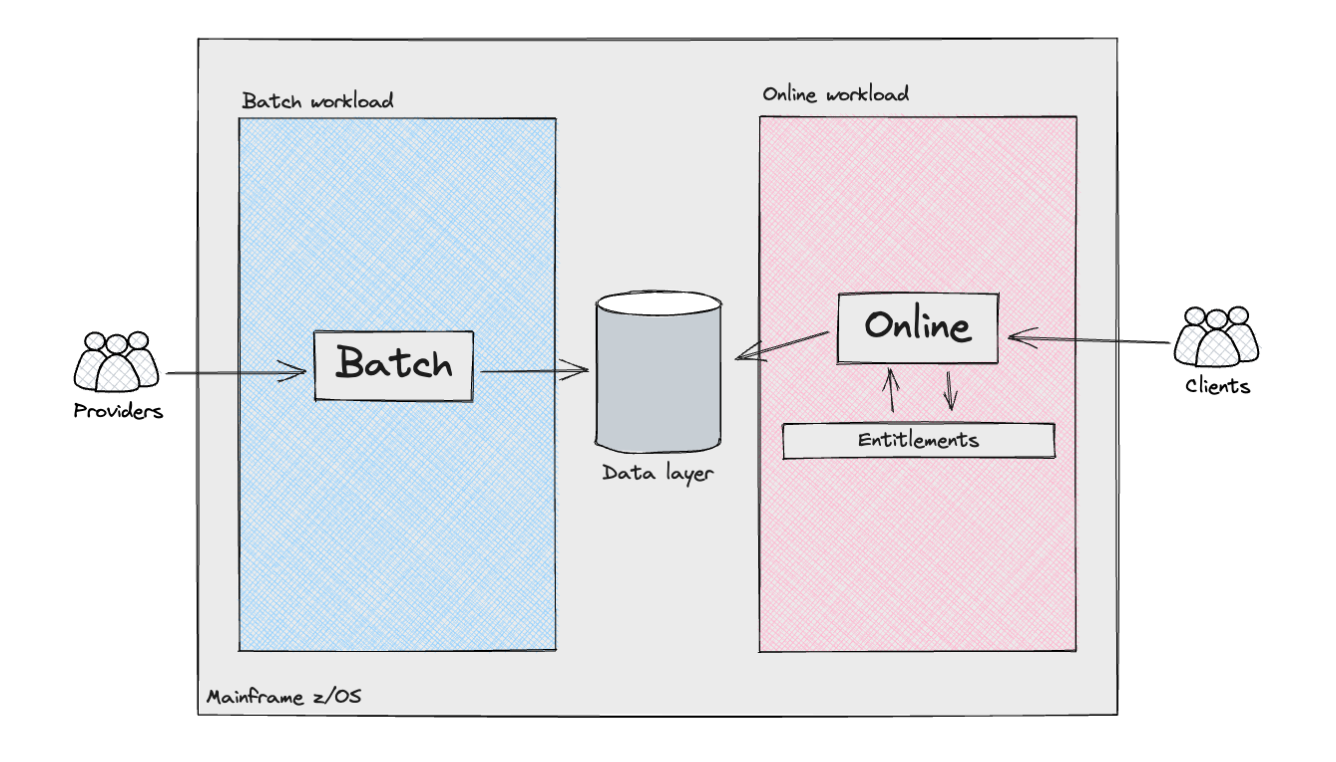
The Mainframe supported two distinct varieties of workloads: batch
processing and, for the product API layers, on-line transactions. The batch
workloads resembled what is often known as an information pipeline. They
concerned the ingestion of semi-structured knowledge from exterior
suppliers/sources, or different inside Mainframe programs, adopted by knowledge
cleaning and modelling to align with the necessities of the Client
Subsystem. These pipelines included varied complexities, together with
the implementation of the Id looking out logic: in the UK,
not like the USA with its social safety quantity, there isn’t a
universally distinctive identifier for residents. Consequently, corporations
working within the UK&I need to make use of customised algorithms to precisely
decide the person identities related to that knowledge.
The net workload additionally offered vital complexities. The
orchestration of API requests was managed by a number of internally developed
frameworks, which decided this system execution circulate by lookups in
datastores, alongside dealing with conditional branches by analysing the
output of the code. We should always not overlook the extent of customisation this
framework utilized for every buyer. For instance, some flows have been
orchestrated with ad-hoc configuration, catering for implementation
particulars or particular wants of the programs interacting with our consumer’s
on-line merchandise. These configurations have been distinctive at first, however they
possible grew to become the norm over time, as our consumer augmented their on-line
choices.
This was applied by means of an Entitlements engine which operated
throughout layers to make sure that prospects accessing merchandise and underlying
knowledge have been authenticated and authorised to retrieve both uncooked or
aggregated knowledge, which might then be uncovered to them by means of an API
response.
Incremental Legacy Displacement: Ideas, Advantages, and
Concerns
Contemplating the scope, dangers, and complexity of the Client Subsystem,
we believed the next ideas can be tightly linked with us
succeeding with the programme:
- Early Threat Discount: With engineering ranging from the
starting, the implementation of a “Fail-Quick” strategy would assist us
establish potential pitfalls and uncertainties early, thus stopping
delays from a programme supply standpoint. These have been: - Final result Parity: The consumer emphasised the significance of
upholding consequence parity between the present legacy system and the
new system (You will need to word that this idea differs from
Characteristic Parity). Within the consumer’s Legacy system, varied
attributes have been generated for every shopper, and given the strict
business laws, sustaining continuity was important to make sure
contractual compliance. We wanted to proactively establish
discrepancies in knowledge early on, promptly deal with or clarify them, and
set up belief and confidence with each our consumer and their
respective prospects at an early stage. - Cross-functional necessities: The Mainframe is a extremely
performant machine, and there have been uncertainties {that a} answer on
the Cloud would fulfill the Cross-functional necessities. - Ship Worth Early: Collaboration with the consumer would
guarantee we may establish a subset of probably the most important Enterprise
Capabilities we may ship early, making certain we may break the system
aside into smaller increments. These represented thin-slices of the
total system. Our aim was to construct upon these slices iteratively and
continuously, serving to us speed up our total studying within the area.
Moreover, working by means of a thin-slice helps cut back the cognitive
load required from the group, thus stopping evaluation paralysis and
making certain worth can be persistently delivered. To realize this, a
platform constructed across the Mainframe that gives higher management over
purchasers’ migration methods performs an important position. Utilizing patterns resembling
Darkish Launching and Canary
Launch would place us within the driver’s seat for a easy
transition to the Cloud. Our aim was to realize a silent migration
course of, the place prospects would seamlessly transition between programs
with none noticeable affect. This might solely be doable by means of
complete comparability testing and steady monitoring of outputs
from each programs.
With the above ideas and necessities in thoughts, we opted for an
Incremental Legacy Displacement strategy together with Twin
Run. Successfully, for every slice of the system we have been rebuilding on the
Cloud, we have been planning to feed each the brand new and as-is system with the
identical inputs and run them in parallel. This enables us to extract each
programs’ outputs and verify if they’re the identical, or a minimum of inside an
acceptable tolerance. On this context, we outlined Incremental Twin
Run as: utilizing a Transitional
Structure to assist slice-by-slice displacement of functionality
away from a legacy surroundings, thereby enabling goal and as-is programs
to run briefly in parallel and ship worth.
We determined to undertake this architectural sample to strike a steadiness
between delivering worth, discovering and managing dangers early on,
making certain consequence parity, and sustaining a easy transition for our
consumer all through the length of the programme.
Incremental Legacy Displacement strategy
To perform the offloading of capabilities to our goal
structure, the group labored carefully with Mainframe SMEs (Topic Matter
Specialists) and our consumer’s engineers. This collaboration facilitated a
simply sufficient understanding of the present as-is panorama, when it comes to each
technical and enterprise capabilities; it helped us design a Transitional
Structure to attach the present Mainframe to the Cloud-based system,
the latter being developed by different supply workstreams within the
programme.
Our strategy started with the decomposition of the
Client subsystem into particular enterprise and technical domains, together with
knowledge load, knowledge retrieval & aggregation, and the product layer
accessible by means of external-facing APIs.
Due to our consumer’s enterprise
objective, we recognised early that we may exploit a significant technical boundary to organise our programme. The
consumer’s workload was largely analytical, processing principally exterior knowledge
to provide perception which was offered on to purchasers. We subsequently noticed an
alternative to separate our transformation programme in two components, one round
knowledge curation, the opposite round knowledge serving and product use circumstances utilizing
knowledge interactions as a seam. This was the primary excessive stage seam recognized.
Following that, we then wanted to additional break down the programme into
smaller increments.
On the information curation facet, we recognized that the information units have been
managed largely independently of one another; that’s, whereas there have been
upstream and downstream dependencies, there was no entanglement of the datasets throughout curation, i.e.
ingested knowledge units had a one to 1 mapping to their enter information.
.
We then collaborated carefully with SMEs to establish the seams
throughout the technical implementation (laid out under) to plan how we may
ship a cloud migration for any given knowledge set, ultimately to the extent
the place they might be delivered in any order (Database Writers Processing Pipeline Seam, Coarse Seam: Batch Pipeline Step Handoff as Seam,
and Most Granular: Knowledge Attribute
Seam). So long as up- and downstream dependencies may alternate knowledge
from the brand new cloud system, these workloads might be modernised
independently of one another.
On the serving and product facet, we discovered that any given product used
80% of the capabilities and knowledge units that our consumer had created. We
wanted to discover a completely different strategy. After investigation of the best way entry
was offered to prospects, we discovered that we may take a “buyer phase”
strategy to ship the work incrementally. This entailed discovering an
preliminary subset of consumers who had bought a smaller proportion of the
capabilities and knowledge, lowering the scope and time wanted to ship the
first increment. Subsequent increments would construct on high of prior work,
enabling additional buyer segments to be reduce over from the as-is to the
goal structure. This required utilizing a special set of seams and
transitional structure, which we focus on in Database Readers and Downstream processing as a Seam.
Successfully, we ran an intensive evaluation of the elements that, from a
enterprise perspective, functioned as a cohesive entire however have been constructed as
distinct parts that might be migrated independently to the Cloud and
laid this out as a programme of sequenced increments.

{kind=link}