
Sponsored Content material by TileDB
 At present we’re formally saying that TileDB helps vector search. TileDB is an array database, and its important energy is that it could morph into virtually any information modality and software, delivering unprecedented efficiency and assuaging the information infrastructure in a corporation. A vector is solely a 1D array, subsequently, TileDB is essentially the most pure database alternative for delivering wonderful vector search performance.
At present we’re formally saying that TileDB helps vector search. TileDB is an array database, and its important energy is that it could morph into virtually any information modality and software, delivering unprecedented efficiency and assuaging the information infrastructure in a corporation. A vector is solely a 1D array, subsequently, TileDB is essentially the most pure database alternative for delivering wonderful vector search performance.
We spent a few years constructing a robust array-based engine, which allowed us to fairly shortly improve our database with vector search capabilities. Right here is why you need to care:
- TileDB is greater than 8x sooner than FAISS (particularly for algorithm IVF_FLAT based mostly on k-means), some of the well-liked vector search libraries
- TileDB works on any storage backend, together with scalable and cheap cloud object shops
- TileDB has a totally serverless, massively distributed compute infrastructure and may deal with billions of vectors and tens of hundreds of queries per second
- TileDB is a single, unified resolution that manages the vector embeddings together with the uncooked authentic information (e.g., photographs, textual content information, and so forth), the ML embedding fashions, and all the opposite information modalities in your software (tables, genomics, level clouds, and so forth).
- You may get loads of worth from TileDB as a vector database both from our open-source providing (MIT License), or our enterprise-grade business product.
TileDB’s core array expertise lies within the open-source (MIT License) library TileDB-Embedded, however we developed the vector-search-specific parts within the library TileDB-Vector-Search, which can be open-source beneath MIT License. Just like the core library, TileDB-Vector-Search is inbuilt C++, and affords a Python API. As well as, TileDB is creating TileDB Cloud, a business product that provides serverless, distributed computing, safe governance, and different interesting options.
In vector search, there’s a set of N vectors every of size L, a number of question vectors, and a distance perform used to check the vectors. In TileDB, we retailer the vector dataset in a NxL matrix, i.e., a 2D array. TileDB natively shops arrays and, thus, ingestion, all updates with versioning and time touring, and studying (aka slicing) are already dealt with by TileDB Embedded — we actually didn’t must construct any additional code for that.
The extra issues we needed to construct had been:
- Indexes for quick (approximate) similarity search
- The quick (approximate) similarity search itself
- APIs which might be extra acquainted to people utilizing vector databases
We developed all of the above in an open-source bundle known as TileDB-Vector-Search, which is constructed on high of TileDB Embedded. At the moment, this bundle helps:
- A C++ and Python API
- FLAT (brute-force) and IVF_FLAT algorithms (all others are beneath growth)
- Euclidean distance (different metrics are beneath growth)
FLAT is easy and barely used for giant datasets, however we included it for completeness. IVF_FLAT relies on Ok-means clustering and offers very quick, approximate similarity search. The determine beneath exhibits the arrays that comprise the “vector search asset”, which is represented in TileDB with a “group” (consider this as a digital folder). The determine additionally exhibits the IVF_FLAT question course of at a excessive degree.
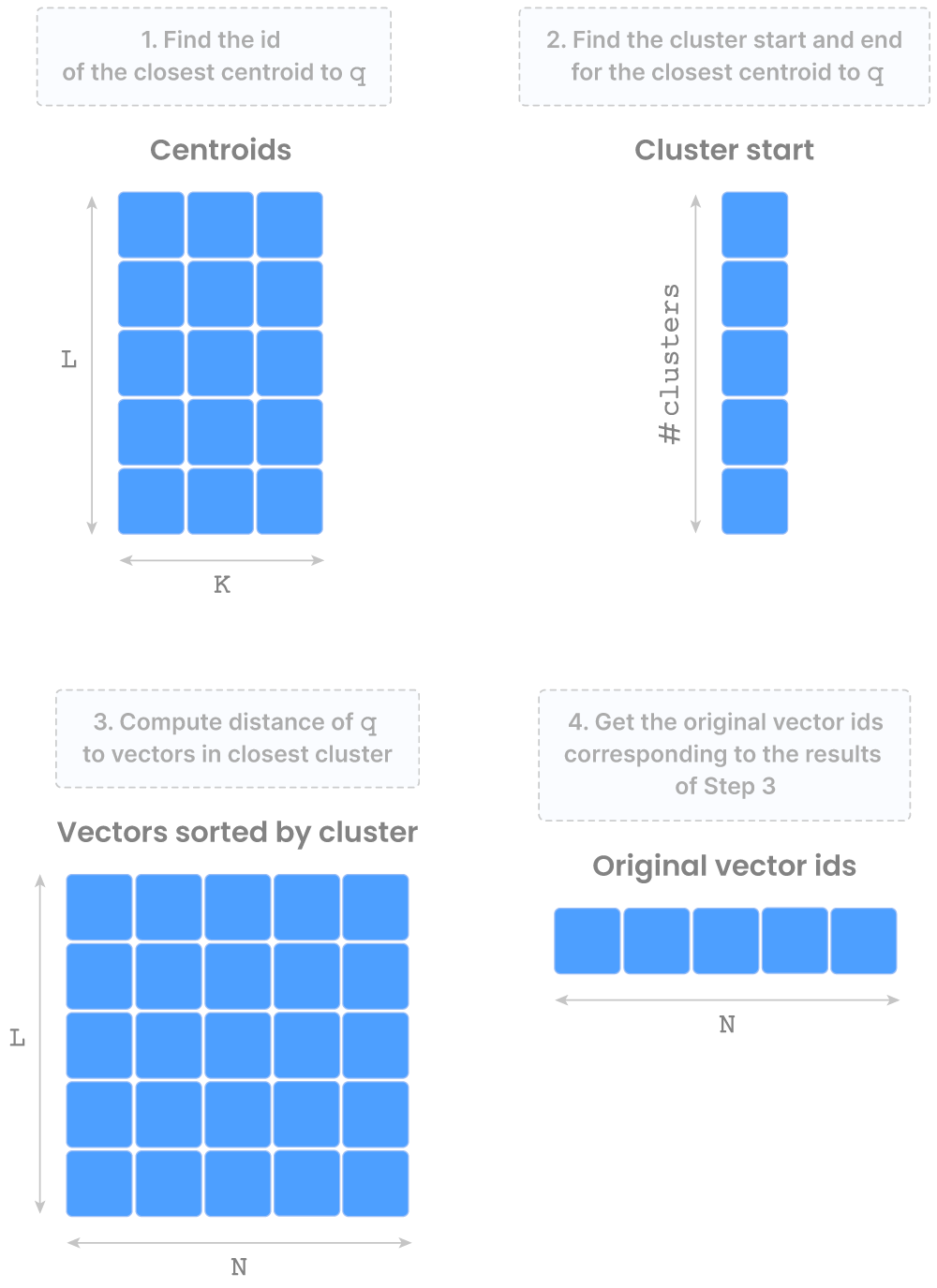
A couple of cool info:
- This implementation works within the following modes:
- Single-server, in-memory: As a result of manner we retailer and course of arrays in RAM, our IVF_FLAT efficiency is spectacular; as much as 8x sooner than FAISS, serving over 60k queries per second based mostly on SIFT 10M, and a couple of.7k queries per second on SIFT 1B.
- Single-server, out-of-core: TileDB has native, tremendous environment friendly out-of-core assist, so our vector search implementation on this mode inherited the excessive efficiency.
- Serverless, cloud retailer: Resulting from the truth that we architected TileDB from the bottom as much as be serverless and work flawlessly on cloud object shops, our vector search implementation delivers very good efficiency even on this setting, offering unprecedented scalability to billions of vectors whereas minimizing operational prices.
- TileDB helps batching of queries, i.e., it could dispatch a whole bunch of hundreds of queries collectively in a bundle. We provide a really optimized implementation of batching, which amortizes some mounted, widespread prices throughout all queries, considerably rising the queries per second (QPS).
- The “serverless, cloud retailer” mode can leverage the TileDB Cloud distributed, serverless computing infrastructure to parallelize throughout each queries in a batch, in addition to inside a single question. This offers unprecedented scalability, QPS and real-time response instances even in excessive querying eventualities.
- Concerning the “multi-server, in-memory” mode, we’re gathering some extra suggestions from customers. Though it’s simple to construct (and you may most likely construct it yourselves leveraging simply TileDB’s single-server, in-memory mode), we hypothesize that it’s overkill for the customers from an operational standpoint, particularly within the presence of the extra scalable and cheap choices of “single-server, out-of-core” and “serverless, cloud retailer”. Please ship us a be aware after you check out these different modes if they don’t present enough efficiency on your use case.
We’re extraordinarily excited in regards to the vector search area and the potential of Generative AI. However regardless of its highly effective vector search capabilities, TileDB is greater than a vector database.
TileDB is an array database. Arrays are a really versatile information construction that may have any variety of dimensions, retailer any kind of information inside every of its parts (known as cells), and might be dense (when all cells will need to have a worth) or sparse (when the vast majority of the cells are empty). The sky’s the restrict in terms of what sort of information and purposes arrays can seize. You’ll be able to learn all about arrays and their purposes in my weblog Why Arrays as a Common Knowledge Mannequin. And for those who suppose that an array database is one more area of interest, specialised database, that weblog additionally demonstrates how arrays subsume tables. In different phrases, arrays should not specialised, however as a substitute they’re common, treating tables as a particular case of arrays.
TileDB envisions to retailer, handle and analyze all of your information alongside your vector embeddings, together with the uncooked authentic information you generate your vectors from, in addition to some other information your group would possibly require a robust database for. Storing a number of information modalities in a single system (1) lowers your licensing prices, (2) simplifies your infrastructure and reduces information engineering, (3) eliminates the information silos enabling a extra sane, holistic governance method over all of your information and code belongings.
As LLMs have gotten increasingly more highly effective leveraging a number of information modalities, TileDB is the pure alternative for internally utilizing LLMs to realize unprecedented insights in your numerous information, leveraging pure language as an API! Think about extracting instantaneous worth from all your information, with out serious about code syntax in several programming languages, understanding the underlying peculiarities of the totally different information sources, or worrying about safety and governance.
Keep tuned for extra updates on how we’re redefining the “database”!
You will discover extra detailed details about TileDB’s vector search capabilities in weblog Why TileDB as a Vector Database, and get kickstarted with weblog TileDB 101: Vector Search. I additionally suggest watching our latest webinar Bridging Analytics, LLMs and information merchandise in a single database, which I co-hosted with Sanjeev Mohan.
To study extra in regards to the TileDB-Vector-Search library, try the github repo and docs. We’ve a really lengthy backlog on vector search, so search for extra articles on our detailed benchmarks, inner engineering mechanics, and LLM integrations.
Be at liberty to contact us together with your suggestions and ideas, comply with us on LinkedIn and Twitter, be a part of our Slack group, or learn extra about TileDB on our web site and weblog.

{kind=link}