

Right this moment, I’m publishing the Distributed Computing Manifesto, a canonical
doc from the early days of Amazon that reworked the structure
of Amazon’s ecommerce platform. It highlights the challenges we had been
dealing with on the finish of the 20th century, and hints at the place we had been
headed.
On the subject of the ecommerce aspect of Amazon, architectural data
was hardly ever shared with the general public. So, once I was invited by Amazon in
2004 to provide a speak about my distributed programs analysis, I virtually
didn’t go. I used to be pondering: internet servers and a database, how arduous can
that be? However I’m completely satisfied that I did, as a result of what I encountered blew my
thoughts. The size and variety of their operation was not like something I
had ever seen, Amazon’s structure was not less than a decade forward of what
I had encountered at different corporations. It was greater than only a
high-performance web site, we’re speaking about every thing from
high-volume transaction processing to machine studying, safety,
robotics, binning hundreds of thousands of merchandise – something that you could possibly discover
in a distributed programs textbook was taking place at Amazon, and it was
taking place at unbelievable scale. Once they provided me a job, I couldn’t
resist. Now, after virtually 18 years as their CTO, I’m nonetheless blown away
every day by the inventiveness of our engineers and the programs
they’ve constructed.
To invent and simplify
A steady problem when working at unparalleled scale, whenever you
are a long time forward of anybody else, and rising by an order of magnitude
each few years, is that there isn’t a textbook you possibly can depend on, neither is
there any industrial software program you should purchase. It meant that Amazon’s
engineers needed to invent their approach into the longer term. And with each few
orders of magnitude of development the present structure would begin to
present cracks in reliability and efficiency, and engineers would begin to
spend extra time with digital duct tape and WD40 than constructing
new revolutionary merchandise. At every of those inflection factors, engineers
would invent their approach into a brand new architectural construction to be prepared
for the subsequent orders of magnitude development. Architectures that no one had
constructed earlier than.
Over the subsequent 20 years, Amazon would transfer from a monolith to a
service-oriented structure, to microservices, then to microservices
operating over a shared infrastructure platform. All of this was being
completed earlier than phrases like service-oriented structure existed. Alongside
the best way we realized quite a lot of classes about working at web scale.
Throughout my keynote at AWS
re:Invent
in a few weeks, I plan to speak about how the ideas on this doc
began to formed what we see in microservices and occasion pushed
architectures. Additionally, within the coming months, I’ll write a collection of
posts that dive deep into particular sections of the Distributed Computing
Manifesto.
A really temporary historical past of system structure at Amazon
Earlier than we go deep into the weeds of Amazon’s architectural historical past, it
helps to grasp a bit of bit about the place we had been 25 years in the past.
Amazon was transferring at a speedy tempo, constructing and launching merchandise each
few months, improvements that we take with no consideration right now: 1-click shopping for,
self-service ordering, immediate refunds, suggestions, similarities,
search-inside-the-book, associates promoting, and third-party merchandise.
The listing goes on. And these had been simply the customer-facing improvements,
we’re not even scratching the floor of what was taking place behind the
scenes.
Amazon began off with a standard two-tier structure: a
monolithic, stateless software
(Obidos) that was
used to serve pages and a complete battery of databases that grew with
each new set of product classes, merchandise inside these classes,
clients, and nations that Amazon launched in. These databases had been a
shared useful resource, and ultimately grew to become the bottleneck for the tempo that
we needed to innovate.
Again in 1998, a collective of senior Amazon
engineers began to put the groundwork for a radical overhaul of
Amazon’s structure to help the subsequent era of buyer centric
innovation. A core level was separating the presentation layer, enterprise
logic and knowledge, whereas making certain that reliability, scale, efficiency and
safety met an extremely excessive bar and retaining prices underneath management.
Their proposal was referred to as the Distributed Computing Manifesto.
I’m sharing this now to provide you a glimpse at how superior the pondering
of Amazon’s engineering group was within the late nineties. They persistently
invented themselves out of hassle, scaling a monolith into what we
would now name a service-oriented structure, which was essential to
help the speedy innovation that has grow to be synonymous with Amazon. One
of our Management Ideas is to invent and simplify – our
engineers actually stay by that moto.
Issues change…
One factor to bear in mind as you learn this doc is that it
represents the pondering of just about 25 years in the past. We’ve got come a great distance
since — our enterprise necessities have developed and our programs have
modified considerably. You might learn issues that sound unbelievably
easy or widespread, chances are you’ll learn issues that you just disagree with, however within the
late nineties these concepts had been transformative. I hope you take pleasure in studying
it as a lot as I nonetheless do.
The complete textual content of the Distributed Computing Manifesto is obtainable beneath.
You can even view it as a PDF.
Created: Might 24, 1998
Revised: July 10, 1998
Background
It’s clear that we have to create and implement a brand new structure if
Amazon’s processing is to scale to the purpose the place it will possibly help ten
occasions our present order quantity. The query is, what kind ought to the
new structure take and the way will we transfer in direction of realizing it?
Our present two-tier, client-server structure is one that’s
primarily knowledge certain. The purposes that run the enterprise entry
the database straight and have information of the information mannequin embedded in
them. This implies that there’s a very tight coupling between the
purposes and the information mannequin, and knowledge mannequin modifications need to be
accompanied by software modifications even when performance stays the
identical. This method doesn’t scale nicely and makes distributing and
segregating processing based mostly on the place knowledge is situated troublesome since
the purposes are delicate to the interdependent relationships
between knowledge components.
Key Ideas
There are two key ideas within the new structure we’re proposing to
handle the shortcomings of the present system. The primary, is to maneuver
towards a service-based mannequin and the second, is to shift our processing
in order that it extra carefully fashions a workflow method. This paper doesn’t
handle what particular expertise ought to be used to implement the brand new
structure. This could solely be decided when we’ve got decided
that the brand new structure is one thing that can meet our necessities
and we embark on implementing it.
Service-based mannequin
We suggest transferring in direction of a three-tier structure the place presentation
(consumer), enterprise logic and knowledge are separated. This has additionally been
referred to as a service-based structure. The purposes (purchasers) would no
longer be capable to entry the database straight, however solely by way of a
well-defined interface that encapsulates the enterprise logic required to
carry out the operate. Because of this the consumer is not dependent
on the underlying knowledge construction and even the place the information is situated. The
interface between the enterprise logic (within the service) and the database
can change with out impacting the consumer because the consumer interacts with
the service although its personal interface. Equally, the consumer interface
can evolve with out impacting the interplay of the service and the
underlying database.
Providers, together with workflow, should present each
synchronous and asynchronous strategies. Synchronous strategies would seemingly
be utilized to operations for which the response is quick, comparable to
including a buyer or wanting up vendor data. Nevertheless, different
operations which are asynchronous in nature is not going to present quick
response. An instance of that is invoking a service to move a workflow
aspect onto the subsequent processing node within the chain. The requestor does
not count on the outcomes again instantly, simply a sign that the
workflow aspect was efficiently queued. Nevertheless, the requestor could also be
interested by receiving the outcomes of the request again ultimately. To
facilitate this, the service has to offer a mechanism whereby the
requestor can obtain the outcomes of an asynchronous request. There are
a few fashions for this, polling or callback. Within the callback mannequin
the requestor passes the handle of a routine to invoke when the request
accomplished. This method is used mostly when the time between the
request and a reply is comparatively brief. A major drawback of
the callback method is that the requestor might not be energetic when
the request has accomplished making the callback handle invalid. The
polling mannequin, nevertheless, suffers from the overhead required to
periodically verify if a request has accomplished. The polling mannequin is the
one that can seemingly be probably the most helpful for interplay with
asynchronous providers.
There are a number of essential implications that need to be thought of as
we transfer towards a service-based mannequin.
The primary is that we should undertake a way more disciplined method
to software program engineering. Presently a lot of our database entry is advert hoc
with a proliferation of Perl scripts that to a really actual extent run our
enterprise. Transferring to a service-based structure would require that
direct consumer entry to the database be phased out over a interval of
time. With out this, we can’t even hope to understand the advantages of a
three-tier structure, comparable to data-location transparency and the
capacity to evolve the information mannequin, with out negatively impacting purchasers.
The specification, design and growth of providers and their
interfaces just isn’t one thing that ought to happen in a haphazard style. It
needs to be fastidiously coordinated in order that we don’t find yourself with the identical
tangled proliferation we at present have. The underside line is that to
efficiently transfer to a service-based mannequin, we’ve got to undertake higher
software program engineering practices and chart out a course that enables us to
transfer on this path whereas nonetheless offering our “clients” with the
entry to enterprise knowledge on which they rely.
A second implication of a service-based method, which is expounded to
the primary, is the numerous mindset shift that can be required of all
software program builders. Our present mindset is data-centric, and once we
mannequin a enterprise requirement, we achieve this utilizing a data-centric method.
Our options contain making the database desk or column modifications to
implement the answer and we embed the information mannequin throughout the accessing
software. The service-based method would require us to interrupt the
resolution to enterprise necessities into not less than two items. The primary
piece is the modeling of the connection between knowledge components simply as
we all the time have. This consists of the information mannequin and the enterprise guidelines that
can be enforced within the service(s) that work together with the information. Nevertheless,
the second piece is one thing we’ve got by no means completed earlier than, which is
designing the interface between the consumer and the service in order that the
underlying knowledge mannequin just isn’t uncovered to or relied upon by the consumer.
This relates again strongly to the software program engineering points mentioned
above.
Workflow-based Mannequin and Information Domaining
Amazon’s enterprise is nicely suited to a workflow-based processing mannequin.
We have already got an “order pipeline” that’s acted upon by numerous
enterprise processes from the time a buyer order is positioned to the time
it’s shipped out the door. A lot of our processing is already
workflow-oriented, albeit the workflow “components” are static, residing
principally in a single database. An instance of our present workflow
mannequin is the development of customer_orders by way of the system. The
situation attribute on every customer_order dictates the subsequent exercise in
the workflow. Nevertheless, the present database workflow mannequin is not going to
scale nicely as a result of processing is being carried out towards a central
occasion. As the quantity of labor will increase (a bigger variety of orders per
unit time), the quantity of processing towards the central occasion will
enhance to some extent the place it’s not sustainable. An answer to
that is to distribute the workflow processing in order that it may be
offloaded from the central occasion. Implementing this requires that
workflow components like customer_orders would transfer between enterprise
processing (“nodes”) that may very well be situated on separate machines.
As a substitute of processes coming to the information, the information would journey to the
course of. Because of this every workflow aspect would require the entire
data required for the subsequent node within the workflow to behave upon it.
This idea is identical as one utilized in message-oriented middleware
the place items of labor are represented as messages shunted from one node
(enterprise course of) to a different.
A difficulty with workflow is how it’s directed. Does every processing node
have the autonomy to redirect the workflow aspect to the subsequent node
based mostly on embedded enterprise guidelines (autonomous) or ought to there be some
form of workflow coordinator that handles the switch of labor between
nodes (directed)? As an example the distinction, contemplate a node that
performs bank card prices. Does it have the built-in “intelligence”
to refer orders that succeeded to the subsequent processing node within the order
pipeline and shunt those who didn’t another node for exception
processing? Or is the bank card charging node thought of to be a
service that may be invoked from anyplace and which returns its outcomes
to the requestor? On this case, the requestor can be accountable for
coping with failure situations and figuring out what the subsequent node in
the processing is for profitable and failed requests. A serious benefit
of the directed workflow mannequin is its flexibility. The workflow
processing nodes that it strikes work between are interchangeable constructing
blocks that can be utilized in numerous mixtures and for various
functions. Some processing lends itself very nicely to the directed mannequin,
as an example bank card cost processing since it could be invoked in
totally different contexts. On a grander scale, DC processing thought of as a
single logical course of advantages from the directed mannequin. The DC would
settle for buyer orders to course of and return the outcomes (cargo,
exception situations, and so on.) to no matter gave it the work to carry out. On
the opposite hand, sure processes would profit from the autonomous
mannequin if their interplay with adjoining processing is mounted and never
more likely to change. An instance of that is that multi-book shipments all the time
go from picklist to rebin.
The distributed workflow method has a number of benefits. One among these
is {that a} enterprise course of comparable to fulfilling an order can simply be
modeled to enhance scalability. As an illustration, if charging a bank card
turns into a bottleneck, further charging nodes may be added with out
impacting the workflow mannequin. One other benefit is {that a} node alongside the
workflow path doesn’t essentially need to rely upon accessing distant
databases to function on a workflow aspect. Because of this sure
processing can proceed when different items of the workflow system (like
databases) are unavailable, enhancing the general availability of the
system.
Nevertheless, there are some drawbacks to the message-based distributed
workflow mannequin. A database-centric mannequin, the place each course of accesses
the identical central knowledge retailer, permits knowledge modifications to be propagated
shortly and effectively by way of the system. As an illustration, if a buyer
needs to alter the credit-card quantity getting used for his order as a result of
the one he initially specified has expired or was declined, this may be
completed simply and the change can be immediately represented in every single place in
the system. In a message-based workflow mannequin, this turns into extra
sophisticated. The design of the workflow has to accommodate the truth that
a number of the underlying knowledge might change whereas a workflow aspect is
making its approach from one finish of the system to the opposite. Moreover,
with basic queue-based workflow it’s harder to find out the
state of any explicit workflow aspect. To beat this, mechanisms
need to be created that permit state transitions to be recorded for the
profit of outdoor processes with out impacting the supply and
autonomy of the workflow course of. These points make appropriate preliminary
design way more essential than in a monolithic system, and converse again
to the software program engineering practices mentioned elsewhere.
The workflow mannequin applies to knowledge that’s transient in our system and
undergoes well-defined state modifications. Nevertheless, there’s one other class of
knowledge that doesn’t lend itself to a workflow method. This class of
knowledge is basically persistent and doesn’t change with the identical frequency
or predictability as workflow knowledge. In our case this knowledge is describing
clients, distributors and our catalog. It will be significant that this knowledge be
extremely out there and that we preserve the relationships between these
knowledge (comparable to realizing what addresses are related to a buyer).
The thought of making knowledge domains permits us to separate up this class of
knowledge in accordance with its relationship with different knowledge. As an illustration, all
knowledge pertaining to clients would make up one area, all knowledge about
distributors one other and all knowledge about our catalog a 3rd. This enables us
to create providers by which purchasers work together with the varied knowledge
domains and opens up the potential for replicating area knowledge in order that
it’s nearer to its client. An instance of this might be replicating
the client knowledge area to the U.Okay. and Germany in order that buyer
service organizations may function off of an area knowledge retailer and never be
depending on the supply of a single occasion of the information. The
service interfaces to the information can be equivalent however the copy of the
area they entry can be totally different. Creating knowledge domains and the
service interfaces to entry them is a crucial aspect in separating
the consumer from information of the inner construction and site of the
knowledge.
Making use of the Ideas
DC processing lends itself nicely for example of the applying of the
workflow and knowledge domaining ideas mentioned above. Information move by way of
the DC falls into three distinct classes. The primary is that which is
nicely suited to sequential queue processing. An instance of that is the
received_items queue stuffed in by vreceive. The second class is that
knowledge which ought to reside in an information area both due to its
persistence or the requirement that it’s extensively out there. Stock
data (bin_items) falls into this class, as it’s required each
within the DC and by different enterprise capabilities like sourcing and buyer
help. The third class of information suits neither the queuing nor the
domaining mannequin very nicely. This class of information is transient and solely
required regionally (throughout the DC). It isn’t nicely suited to sequential
queue processing, nevertheless, since it’s operated upon in combination. An
instance of that is the information required to generate picklists. A batch of
buyer shipments has to build up in order that picklist has sufficient
data to print out picks in accordance with cargo technique, and so on. As soon as
the picklist processing is completed, the shipments go on to the subsequent cease in
their workflow. The holding areas for this third sort of information are referred to as
aggregation queues since they exhibit the properties of each queues
and database tables.
Monitoring State Modifications
The flexibility for outdoor processes to have the ability to monitor the motion and
change of state of a workflow aspect by way of the system is crucial.
Within the case of DC processing, customer support and different capabilities want
to have the ability to decide the place a buyer order or cargo is within the
pipeline. The mechanism that we suggest utilizing is one the place sure nodes
alongside the workflow insert a row into some centralized database occasion
to point the present state of the workflow aspect being processed.
This sort of data can be helpful not just for monitoring the place
one thing is within the workflow nevertheless it additionally gives essential perception into
the workings and inefficiencies in our order pipeline. The state
data would solely be stored within the manufacturing database whereas the
buyer order is energetic. As soon as fulfilled, the state change data
can be moved to the information warehouse the place it will be used for
historic evaluation.
Making Modifications to In-flight Workflow Parts
Workflow processing creates an information foreign money drawback since workflow
components include the entire data required to maneuver on to the subsequent
workflow node. What if a buyer needs to alter the delivery handle
for an order whereas the order is being processed? Presently, a CS
consultant can change the delivery handle within the customer_order
(supplied it’s earlier than a pending_customer_shipment is created) since
each the order and buyer knowledge are situated centrally. Nevertheless, in a
workflow mannequin the client order can be some other place being processed
by way of numerous levels on the best way to turning into a cargo to a buyer.
To have an effect on a change to an in-flight workflow aspect, there needs to be a
mechanism for propagating attribute modifications. A publish and subscribe
mannequin is one technique for doing this. To implement the P&S mannequin,
workflow-processing nodes would subscribe to obtain notification of
sure occasions or exceptions. Attribute modifications would represent one
class of occasions. To vary the handle for an in-flight order, a message
indicating the order and the modified attribute can be despatched to all
processing nodes that subscribed for that individual occasion.
Moreover, a state change row can be inserted within the monitoring desk
indicating that an attribute change was requested. If one of many nodes
was capable of have an effect on the attribute change it will insert one other row in
the state change desk to point that it had made the change to the
order. This mechanism implies that there can be a everlasting report of
attribute change occasions and whether or not they had been utilized.
One other variation on the P&S mannequin is one the place a workflow coordinator,
as an alternative of a workflow-processing node, impacts modifications to in-flight
workflow components as an alternative of a workflow-processing node. As with the
mechanism described above, the workflow coordinators would subscribe to
obtain notification of occasions or exceptions and apply these to the
relevant workflow components because it processes them.
Making use of modifications to in-flight workflow components synchronously is an
various to the asynchronous propagation of change requests. This has
the advantage of giving the originator of the change request immediate
suggestions about whether or not the change was affected or not. Nevertheless, this
mannequin requires that each one nodes within the workflow be out there to course of
the change synchronously, and ought to be used just for modifications the place it
is appropriate for the request to fail on account of non permanent unavailability.
Workflow and DC Buyer Order Processing
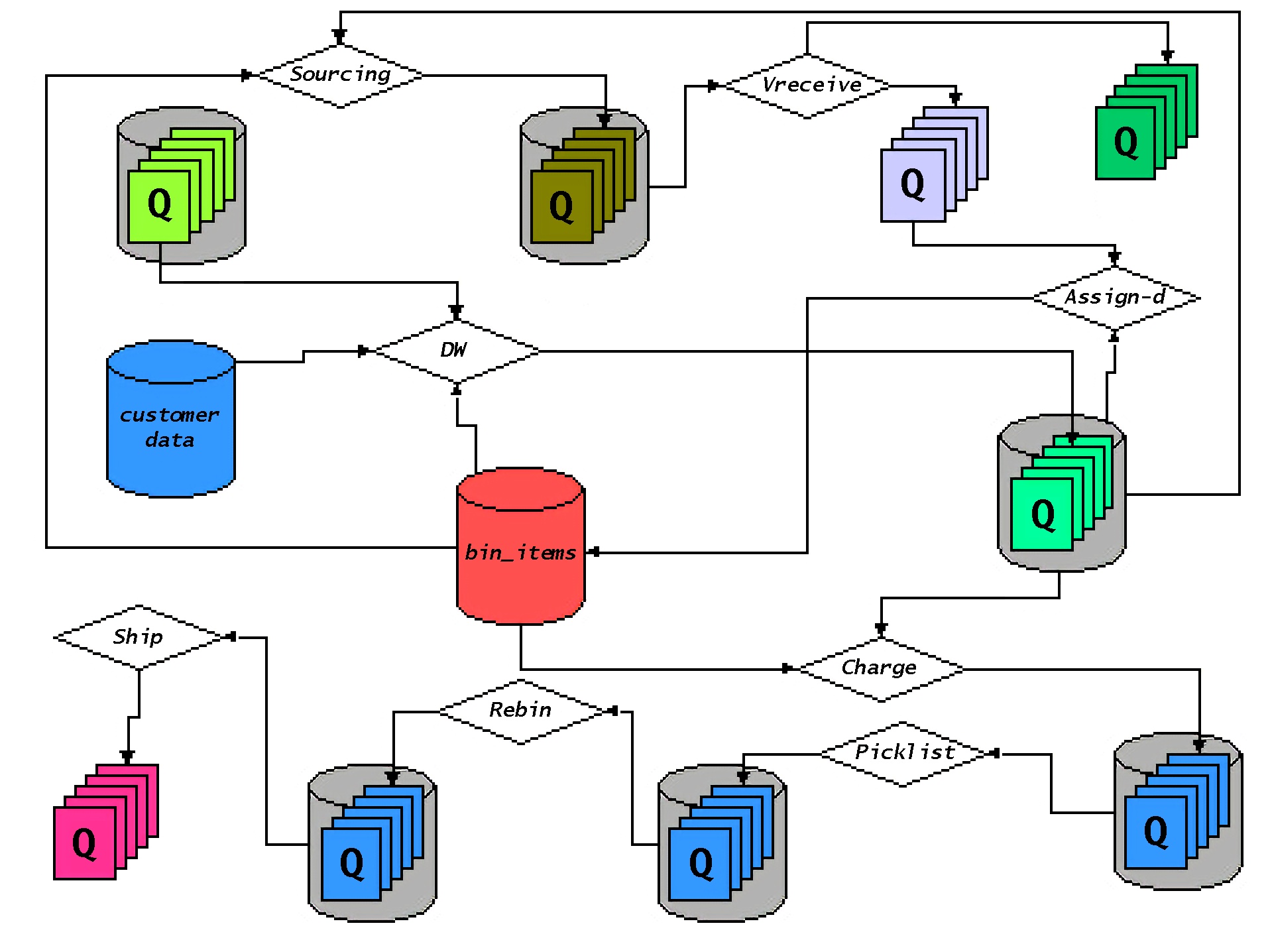
The diagram beneath represents a simplified view of how a buyer
order moved by way of numerous workflow levels within the DC. That is modeled
largely after the best way issues at present work with some modifications to
symbolize how issues will work as the results of DC isolation. On this
image, as an alternative of a buyer order or a buyer cargo remaining in
a static database desk, they’re bodily moved between workflow
processing nodes represented by the diamond-shaped containers. From the
diagram, you possibly can see that DC processing employs knowledge domains (for
buyer and stock data), true queue (for acquired gadgets and
distributor shipments) in addition to aggregation queues (for cost
processing, picklisting, and so on.). Every queue exposes a service interface
by way of which a requestor can insert a workflow aspect to be processed
by the queue’s respective workflow-processing node. As an illustration,
orders which are able to be charged can be inserted into the cost
service’s queue. Cost processing (which can be a number of bodily
processes) would take away orders from the queue for processing and ahead
them on to the subsequent workflow node when completed (or again to the requestor of
the cost service, relying on whether or not the coordinated or autonomous
workflow is used for the cost service).
© 1998, Amazon.com, Inc. or its associates.

{kind=link}