

Current advances have expanded the applicability of language fashions (LM) to downstream duties. On one hand, present language fashions which are correctly prompted, through chain-of-thought, exhibit emergent capabilities that perform self-conditioned reasoning traces to derive solutions from questions, excelling at numerous arithmetic, commonsense, and symbolic reasoning duties. Nonetheless, with chain-of-thought prompting, a mannequin is just not grounded within the exterior world and makes use of its personal inside representations to generate reasoning traces, limiting its capacity to reactively discover and motive or replace its information. Then again, current work makes use of pre-trained language fashions for planning and appearing in numerous interactive environments (e.g., textual content video games, net navigation, embodied duties, robotics), with a concentrate on mapping textual content contexts to textual content actions through the language mannequin’s inside information. Nonetheless, they don’t motive abstractly about high-level targets or keep a working reminiscence to assist appearing over lengthy horizons.
In “ReAct: Synergizing Reasoning and Performing in Language Fashions”, we suggest a common paradigm that mixes reasoning and appearing advances to allow language fashions to resolve numerous language reasoning and resolution making duties. We exhibit that the Purpose+Act (ReAct) paradigm systematically outperforms reasoning and appearing solely paradigms, when prompting greater language fashions and fine-tuning smaller language fashions. The tight integration of reasoning and appearing additionally presents human-aligned task-solving trajectories that enhance interpretability, diagnosability, and controllability..
Mannequin Overview
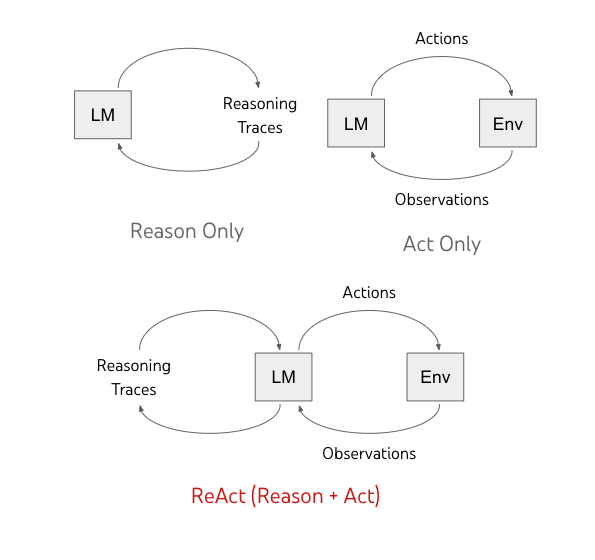
ReAct permits language fashions to generate each verbal reasoning traces and textual content actions in an interleaved method. Whereas actions result in remark suggestions from an exterior surroundings (“Env” within the determine under), reasoning traces don’t have an effect on the exterior surroundings. As an alternative, they have an effect on the inner state of the mannequin by reasoning over the context and updating it with helpful data to assist future reasoning and appearing.
 |
| Earlier strategies immediate language fashions (LM) to both generate self-conditioned reasoning traces or task-specific actions. We suggest ReAct, a brand new paradigm that mixes reasoning and appearing advances in language fashions. |
ReAct Prompting
We concentrate on the setup the place a frozen language mannequin, PaLM-540B, is prompted with few-shot in-context examples to generate each domain-specific actions (e.g., “search” in query answering, and “go to” in room navigation), and free-form language reasoning traces (e.g., “Now I must discover a cup, and put it on the desk”) for activity fixing.
For duties the place reasoning is of major significance, we alternate the era of reasoning traces and actions in order that the task-solving trajectory consists of a number of reasoning-action-observation steps. In distinction, for resolution making duties that probably contain numerous actions, reasoning traces solely want to look sparsely in essentially the most related positions of a trajectory, so we write prompts with sparse reasoning and let the language mannequin determine the asynchronous prevalence of reasoning traces and actions for itself.
As proven under, there are numerous kinds of helpful reasoning traces, e.g., decomposing activity targets to create motion plans, injecting commonsense information related to activity fixing, extracting vital components from observations, monitoring activity progress whereas sustaining plan execution, dealing with exceptions by adjusting motion plans, and so forth.
The synergy between reasoning and appearing permits the mannequin to carry out dynamic reasoning to create, keep, and modify high-level plans for appearing (motive to behave), whereas additionally interacting with the exterior environments (e.g., Wikipedia) to include further data into reasoning (act to motive).
ReAct Effective-tuning
We additionally discover fine-tuning smaller language fashions utilizing ReAct-format trajectories. To cut back the necessity for large-scale human annotation, we use the ReAct prompted PaLM-540B mannequin to generate trajectories, and use trajectories with activity success to fine-tune smaller language fashions (PaLM-8/62B).
 |
| Comparability of 4 prompting strategies, (a) Commonplace, (b) Chain of thought (CoT, Purpose Solely), (c) Act-only, and (d) ReAct, fixing a HotpotQA query. In-context examples are omitted, and solely the duty trajectory is proven. ReAct is ready to retrieve data to assist reasoning, whereas additionally utilizing reasoning to focus on what to retrieve subsequent, demonstrating a synergy of reasoning and appearing. |
Outcomes
We conduct empirical evaluations of ReAct and state-of-the-art baselines throughout 4 completely different benchmarks: query answering (HotPotQA), truth verification (Fever), text-based sport (ALFWorld), and net web page navigation (WebShop). For HotPotQA and Fever, with entry to a Wikipedia API with which the mannequin can work together, ReAct outperforms vanilla motion era fashions whereas being aggressive with chain of thought reasoning (CoT) efficiency. The strategy with the most effective outcomes is a mix of ReAct and CoT that makes use of each inside information and externally obtained data throughout reasoning.
| HotpotQA (precise match, 6-shot) | FEVER (accuracy, 3-shot) | |
| Commonplace | 28.7 | 57.1 |
| Purpose-only (CoT) | 29.4 | 56.3 |
| Act-only | 25.7 | 58.9 |
| ReAct | 27.4 | 60.9 |
| Finest ReAct + CoT Methodology | 35.1 | 64.6 |
| Supervised SoTA | 67.5 (utilizing ~140k samples) | 89.5 (utilizing ~90k samples) |
| PaLM-540B prompting outcomes on HotpotQA and Fever. |
On ALFWorld and WebShop, ReAct with each one-shot and two-shot prompting outperforms imitation and reinforcement studying strategies skilled with ~105 activity cases, with an absolute enchancment of 34% and 10% in success charges, respectively, over present baselines.
| AlfWorld (2-shot) | WebShop (1-shot) | |
| Act-only | 45 | 30.1 |
| ReAct | 71 | 40 |
| Imitation Studying Baselines | 37 (utilizing ~100k samples) | 29.1 (utilizing ~90k samples) |
| PaLM-540B prompting activity success fee outcomes on AlfWorld and WebShop. |
 |
| Scaling outcomes for prompting and fine-tuning on HotPotQA with ReAct and completely different baselines. ReAct constantly achieves finest fine-tuning performances. |
 |
 |
| A comparability of the ReAct (high) and CoT (backside) reasoning trajectories on an instance from Fever (remark for ReAct is omitted to scale back house). On this case ReAct supplied the proper reply, and it may be seen that the reasoning trajectory of ReAct is extra grounded on information and information, in distinction to CoT’s hallucination conduct. |
We additionally discover human-in-the-loop interactions with ReAct by permitting a human inspector to edit ReAct’s reasoning traces. We exhibit that by merely changing a hallucinating sentence with inspector hints, ReAct can change its conduct to align with inspector edits and efficiently full a activity. Fixing duties turns into considerably simpler when utilizing ReAct because it solely requires the handbook modifying of some ideas, which permits new types of human-machine collaboration.
 |
| A human-in-the-loop conduct correction instance with ReAct on AlfWorld. (a) ReAct trajectory fails because of a hallucinating reasoning hint (Act 17). (b) A human inspector edits two reasoning traces (Act 17, 23), ReAct then produces fascinating reasoning traces and actions to finish the duty. |
Conclusion
We current ReAct, a easy but efficient methodology for synergizing reasoning and appearing in language fashions. By means of numerous experiments that concentrate on multi-hop question-answering, truth checking, and interactive decision-making duties, we present that ReAct results in superior efficiency with interpretable resolution traces.
ReAct demonstrates the feasibility of collectively modeling thought, actions and suggestions from the surroundings inside a language mannequin, making it a flexible agent that’s able to fixing duties that require interactions with the surroundings. We plan to additional lengthen this line of analysis and leverage the robust potential of the language mannequin for tackling broader embodied duties, through approaches like huge multitask coaching and coupling ReAct with equally robust reward fashions.
Acknowledgements
We wish to thank Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran and Karthik Narasimhan for his or her nice contribution on this work. We might additionally wish to thank Google’s Mind group and the Princeton NLP Group for his or her joint assist and suggestions, together with challenge scoping, advising and insightful discussions.

{kind=link}