
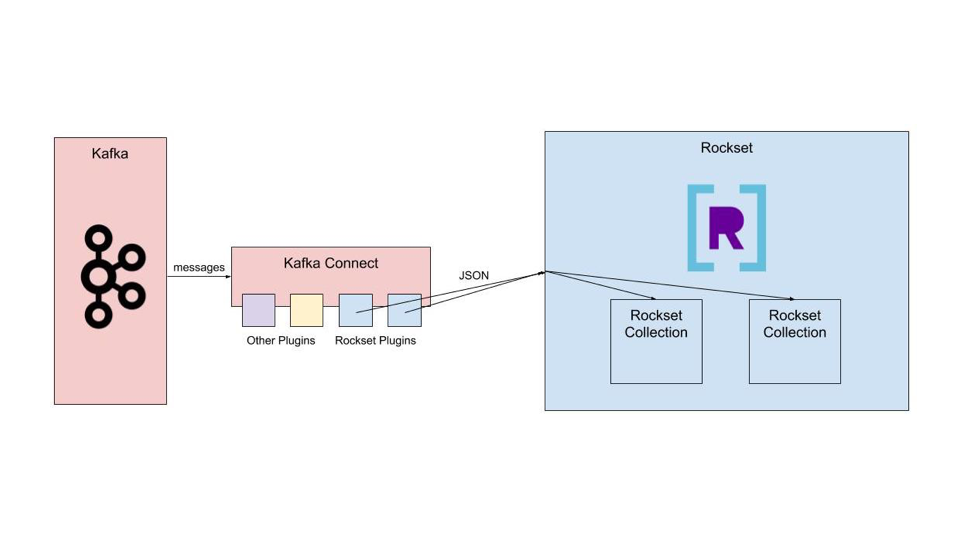
Rockset constantly ingests information streams from Kafka, with out the necessity for a set schema, and serves quick SQL queries on that information. We created the Kafka Join Plugin for Rockset to export information from Kafka and ship it to a set of paperwork in Rockset. Customers can then construct real-time dashboards or information APIs on high of the information in Rockset. This weblog covers how we carried out the plugin.

Implementing a working plugin
What’s Kafka Join and Confluent Hub?
Kafka Join is the first strategy to transmit information between Kafka and one other information storage engine, e.g. S3, Elasticsearch, or a relational database via Kafka Join JDBC, with little or no setup required. It accomplishes this by supporting quite a lot of plugins that transfer information into or out of Kafka to numerous different information engines – the previous are referred to as Kafka Join Supply plugins, the latter Sink plugins. Many information stacks embody a set of Kafka brokers – used as a buffer log, occasion stream, or another use case – and Kafka Join plugins make it very simple so as to add a supply or sink to your Kafka stream.
Confluent, the corporate commercializing Apache Kafka, lists the provenly dependable Kafka Join plugins in Confluent Hub, and integrates these plugins into its Confluent Platform, a product that makes it simple to setup, keep, and monitor Kafka brokers and their related cases. At Rockset, we constructed our Kafka Join Sink plugin to make it simple for patrons with information in Kafka to do real-time analytics, and we listed it in Confluent Hub, as a Gold degree Verified Integration, to assist Confluent’s current person base get actionable insights from their information in a quick and easy method.

Kafka Join will name strategies within the plugin that we implement
Kafka Join runs in a separate occasion out of your Kafka brokers, and every Kafka Join plugin should implement a set of strategies that Kafka Join calls. For sink plugins, it’s going to name the put methodology with a set of messages, and the primary performance of this methodology is often to do some processing of the information after which ship it to the enter channel of the sink information storage engine. In our case, we’ve a Write API, so we remodel the occasions to uncooked JSON and ship them to our API endpoint. The core performance of a Kafka Join plugin is simply that – the Kafka Join platform takes care of the remainder, together with calling the tactic for each occasion within the subjects the person lists and serializing or deserializing the information within the Kafka stream.
The position of the config file – one config for Kafka Join, and one for each plugin
Any person establishing Kafka Join has to change no less than two config recordsdata. The primary is the overall Kafka Join config file – that is the place you set the areas of your Kafka brokers, the trail for the jar recordsdata of the plugins, the serializer and deserializer, and a pair different settings. The serializer and deserializer include the Kafka Join platform and, for a sink plugin, will deserialize the information within the Kafka stream earlier than sending the occasion to plugins, which makes the information processing accomplished within the plugin a lot less complicated.
There’s additionally a config file for every plugin linked to the Kafka Join occasion. Each plugin’s config file has to incorporate settings for the title and sophistication for identification functions, most duties for efficiency tuning, and an inventory of subjects to comply with. Rockset’s additionally consists of the url of the Rockset API server, your Rockset API key, the workspace and assortment in Rockset that the information ought to circulate into, the format of the information, and threads for efficiency tuning. You’ll be able to run a number of Rockset sink plugins on the Kafka Join platform to ship information from completely different subjects in your Kafka stream to completely different Rockset collections.
The plugin sends paperwork from Kafka to our Write API
As soon as the Rockset Kafka Join sink plugin sends the uncooked JSON doc to our Write API, the code path merges with that of regular REST API writes and the server-side structure, which we’ve mentioned in earlier weblog posts, shortly indexes the doc and makes it obtainable for querying.
Itemizing it in Confluent Hub
There are a pair necessities above primary performance which are essential to listing a Kafka Join plugin in Confluent Hub. The subsequent few sections present a tough information for the way you may listing your individual Kafka Join plugin, and illustrate the design choices within the Rockset indexing engine that made satisfying these necessities a straightforward course of.

Supporting Avro with Schema Registry
Kafka offers particular choice to the information serialization format Avro, which approaches the issue of schema adjustments upstream affecting actions downstream by implementing a set schema. This schema is stored within the Schema Registry, a separate occasion. Any schema adjustments have to be accomplished purposefully and in a method that’s backwards or forwards appropriate, relying on the compatibility choices set within the Schema Registry. Due to its set schema, Avro additionally advantages from serializing with out area names, making the message serialization extra environment friendly. Confluent has sturdy assist for Avro serialization, together with a Schema Registry that comes with the Confluent Platform, and Avro assist was essential to listing our Kafka Join plugin in Confluent Hub.
Supporting Avro isn’t too troublesome, because the Kafka Join platform already comes with an Avro serializer and deserializer that may be plugged into the Kafka Join platform utilizing the config file. After the serializer and deserializer do the laborious work, reworking the message to JSON is comparatively easy, and we had been capable of finding examples in open supply Kafka Join plugins. Our personal implementation is right here. The toughest half was understanding how Avro works and simply establishing the config recordsdata and Schema Registry appropriately. Utilizing the Confluent Platform helps a fantastic deal right here, however you continue to must be sure you didn’t miss a config file change – when you attempt deserializing Avro information with a JSON deserializer, nothing will work.
Offset Administration
One other requirement for the Kafka Join plugin is to assist precisely as soon as semantics – that’s, any message despatched from the Kafka stream should seem precisely as soon as within the vacation spot Rockset assortment. The issue right here lies in dealing with errors within the community – if the Kafka Join plugin doesn’t hear a response from our Write API, it’s going to resend the doc, and we could find yourself with repeat paperwork in our pipeline. The best way that is sometimes solved – and the best way we solved it – is by utilizing our distinctive identifier area _id to make sure any duplicates will simply overwrite the unique doc with the identical data. We map the message’s key to our _id area if it’s obtainable, and in any other case use the uniquely figuring out mixture of subject+partition+offset as a default.
Confluent Hub additionally requires Kafka Join sink plugins to respect the proper ordering of the information. This really required no adjustments – each Rockset doc has an _event_time area, and by specifying a area mapping for _event_time when the gathering is created, any Rockset person can guarantee the information is ordered in keeping with their specs.
Config validation
Confluent additionally requires {that a} Kafka Join plugin validates the config file set by the person, with the intention to catch person typos and different errors. The Rockset sink config file incorporates, amongst different issues, the url of our API server to which Write API requests are despatched and the format of the messages within the Kafka stream. If the person offers a worth that isn’t among the many obtainable choices for both of those, the Kafka Join plugin will error out. We’ve got discovered that correctly establishing the config file is among the hardest components of our Kafka integration setup course of, and extra enhancements on this course of and config validation are within the works.
Smaller issues – versioning/packaging, logging, documentation, testing, swish error dealing with
The opposite necessities for itemizing in Confluent Hub – versioning, packaging, logging, documentation, testing, and swish error dealing with – fall beneath the umbrella time period of basic code high quality and value. Confluent requires a selected standardized packaging construction for all its listed Kafka Join plugins that may be constructed utilizing a simple maven plugin. The remainder of these necessities make sure the code is right, the setup course of is obvious, and any errors will be recognized shortly and simply.
Go to our Kafka options web page for extra data on constructing real-time dashboards and APIs on Kafka occasion streams.

{kind=link}