
Introduction
Generative AI is at present getting used extensively all around the world. The flexibility of the Massive Language Fashions to grasp the textual content offered and generate a textual content based mostly on that has led to quite a few purposes from Chatbots to Textual content analyzers. However usually these Massive Language Fashions generate textual content as is, in a non-structured method. Typically we would like the output generated by the LLMs to be in a constructions format, let’s say a JSON (JavaScript Object Notation) format. Let’s say we’re analyzing a social media publish utilizing LLM, and we want the output generated by LLM inside the code itself as a JSON/python variable to carry out another job. Reaching this with Immediate Engineering is feasible but it surely takes a lot time tinkering with the prompts. To resolve this, LangChain has launched Output Parses, which may be labored with in changing the LLMs output storage to a structured format.

Studying Goals
- Deciphering the output generated by Massive Language Fashions
- Creating customized Knowledge Constructions with Pydantic
- Understanding Immediate Templates’ significance and producing one formatting the Output of LLM
- Learn to create format directions for LLM output with LangChain
- See how we are able to parse JSON knowledge to a Pydantic Object
This text was printed as part of the Knowledge Science Blogathon.
What’s LangChain and Output Parsing?
LangChain is a Python Library that allows you to construct purposes with Massive Language Fashions inside no time. It helps all kinds of fashions together with OpenAI GPT LLMs, Google’s PaLM, and even the open-source fashions accessible within the Hugging Face like Falcon, Llama, and plenty of extra. With LangChain customising Prompts to the Massive Language Fashions is a breeze and it additionally comes with a vector retailer out of the field, which may retailer the embeddings of inputs and outputs. It thus may be labored with to create purposes that may question any paperwork inside minutes.
LangChain permits Massive Language Fashions to entry info from the web by way of brokers. It additionally presents output parsers, which permit us to construction the information from the output generated by the Massive Language Fashions. LangChain comes with totally different Output Parses like Checklist Parser, Datetime Parser, Enum Parser, and so forth. On this article, we’ll look by way of the JSON parser, which lets us parse the output generated by the LLMs to a JSON format. Under we are able to observe a typical move of how an LLM output is parsed right into a Pydantic Object, thus making a prepared to make use of knowledge in Python variables

Getting Began – Establishing the Mannequin
On this part, we’ll arrange the mannequin with LangChain. We will probably be utilizing PaLM as our Massive Language Mannequin all through this text. We will probably be utilizing Google Colab for our surroundings. You’ll be able to substitute PaLM with some other Massive Language Mannequin. We’ll begin by first importing the modules required.
!pip set up google-generativeai langchain- It will obtain the LangChain library and the google-generativeai library for working with the PaLM mannequin.
- The langchain library is required to create customized prompts and parse the output generated by the big language fashions
- The google-generativeai library will allow us to work together with Google’s PaLM mannequin.
PaLM API Key
To work with the PaLM, we’ll want an API key, which we are able to get by signing up for the MakerSuite web site. Subsequent, we’ll import all our crucial libraries and go within the API Key to instantiate the PaLM mannequin.
import os
import google.generativeai as palm
from langchain.embeddings import GooglePalmEmbeddings
from langchain.llms import GooglePalm
os.environ['GOOGLE_API_KEY']= 'YOUR API KEY'
palm.configure(api_key=os.environ['GOOGLE_API_KEY'])
llm = GooglePalm()
llm.temperature = 0.1
prompts = ["Name 5 planets and line about them"]
llm_result = llm._generate(prompts)
print(llm_result.generations[0][0].textual content)- Right here we first created an occasion of the Google PaLM(Pathways Language Mannequin) and assigned it to the variable llm
- Within the subsequent step, we set the temperature of our mannequin to 0.1, setting it low as a result of we don’t need the mannequin to hallucinate
- Then we created a Immediate as a listing and handed it to the variable prompts
- To go the immediate to the PaLM, we name the ._generate() technique after which go the Immediate listing to it and the outcomes are saved within the variable llm_result
- Lastly, we print the outcome within the final step by calling the .generations and changing it to textual content by calling the .textual content technique
The output for this immediate may be seen beneath
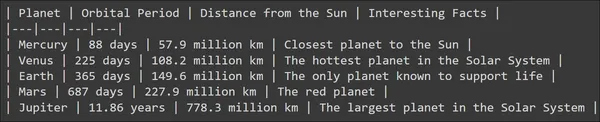
We are able to see that the Massive Language Mannequin has generated a good output and the LLM additionally tried so as to add some construction to it by including some traces. However what if I wish to retailer the data for every mannequin in a variable? What if I wish to retailer the planet title, orbit interval, and distance from the solar, all these individually in a variable? The output generated by the mannequin as is can’t be labored with instantly to realize this. Thus comes the necessity for Output Parses.
Making a Pydantic Output Parser and Immediate Template
On this part, focus on pydantic output parser from langchain. The earlier instance, the output was in an unstructured format. Have a look at how we are able to retailer the data generated by the Massive Language Mannequin in a structured format.
Code Implementation
Let’s begin by trying on the following code:
from pydantic import BaseModel, Area, validator
from langchain.output_parsers import PydanticOutputParser
class PlanetData(BaseModel):
planet: str = Area(description="That is the title of the planet")
orbital_period: float = Area(description="That is the orbital interval
within the variety of earth days")
distance_from_sun: float = Area(description="This can be a float indicating distance
from solar in million kilometers")
interesting_fact: str = Area(description="That is about an fascinating reality of
the planet")- Right here we’re importing the Pydantic Package deal to create a Knowledge Construction. And on this Knowledge Construction, we will probably be storing the output by parsing the output from the LLM.
- Right here we created a Knowledge Construction utilizing Pydantic referred to as PlanetData that shops the next knowledge
- Planet: That is the planet title which we’ll give as enter to the mannequin
- Orbit Interval: This can be a float worth that accommodates the orbital interval in Earth days for a selected planet.
- Distance from Solar: This can be a float indicating the space from a planet to the Solar
- Attention-grabbing Truth: This can be a string that accommodates one fascinating reality in regards to the planet requested
Now, we purpose to question the Massive Language Mannequin for details about a planet and retailer all this knowledge within the PlanetData Knowledge Construction by parsing the LLM output. To parse an LLM output right into a Pydantic Knowledge Construction, LangChain presents a parser referred to as PydanticOutputParser. We go the PlanetData Class to this parser, which may be outlined as follows:
planet_parser = PydanticOutputParser(pydantic_object=PlanetData)We retailer the parser in a variable named planet_parser. The parser object has a way referred to as get_format_instructions() which tells the LLM methods to generate the output. Let’s strive printing it
from pprint import pp
pp(planet_parser.get_format_instructions())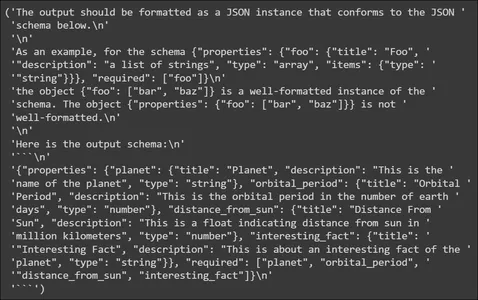
Within the above, we see that the format directions comprise info on methods to format the output generated by the LLM. It tells the LLM to output the information in a JSON schema, so this JSON may be parsed to the Pydantic Knowledge Construction. It additionally offers an instance of an output schema. Subsequent, we’ll create a Immediate Template.
Immediate Template
from langchain import PromptTemplate, LLMChain
template_string = """You're an knowledgeable in terms of answering questions
about planets
You'll be given a planet title and you'll output the title of the planet,
it is orbital interval in days
Additionally it is distance from solar in million kilometers and an fascinating reality
```{planet_name}```
{format_instructions}
"""
planet_prompt = PromptTemplate(
template=template_string,
input_variables=["planet_name"],
partial_variables={"format_instructions": planet_parser
.get_format_instructions()}
)
- In our Immediate Template, we inform, that we’ll be giving a planet title as enter and the LLM has to generate output that features info like Orbit Interval, Distance from Solar, and an fascinating reality in regards to the planet
- Then we assign this template to the PrompTemplate() after which present the enter variable title to the input_variables parameter, in our case it’s the planet_name
- We additionally give in-the-format directions that we’ve got seen earlier than, which inform the LLM methods to generate the output in a JSON format
Let’s strive giving in a planet title and observe how the Immediate seems earlier than being despatched to the Massive Language Mannequin
input_prompt = planet_prompt.format_prompt(planet_name="mercury")
pp(input_prompt.to_string())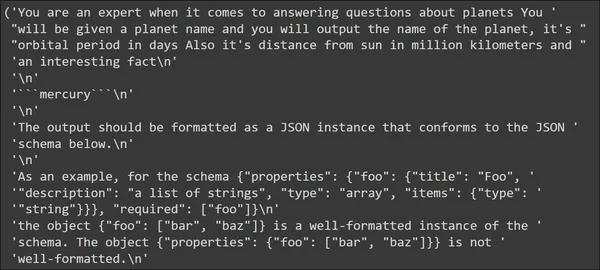
Within the output, we see that the template that we’ve got outlined seems first with the enter “mercury”. Adopted by which can be the format directions. These format directions comprise the directions that the LLM can use to generate JSON knowledge.
Testing the Massive Language Mannequin
On this part, we’ll ship our enter to the LLM and observe the information generated. Within the earlier part, see how will our enter string be, when despatched to the LLM.
input_prompt = planet_prompt.format_prompt(planet_name="mercury")
output = llm(input_prompt.to_string())
pp(output)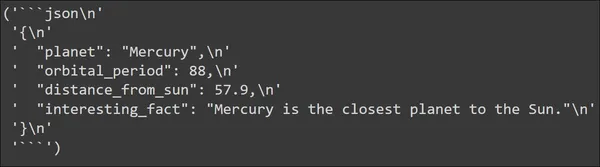
We are able to see the output generated by the Massive Language Mannequin. The output is certainly generated in a JSON format. The JSON knowledge accommodates all of the keys that we’ve got outlined in our PlanetData Knowledge Construction. And every key has a worth which we count on it to have.
Now we’ve got to parse this JSON knowledge to the Knowledge Construction that we’ve got executed. This may be simply executed with the PydanticOutputParser that we’ve got outlined beforehand. Let’s have a look at that code:
parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital interval: ",parsed_output.orbital_period)
print("Distance From the Solar(in Million KM): ",parsed_output.distance_from_sun)
print("Attention-grabbing Truth: ",parsed_output.interesting_fact)Calling within the parse() technique for the planet_parser, will take the output after which parses and converts it to a Pydantic Object, in our case an Object of PlanetData. So the output, i.e. the JSON generated by the Massive Language Mannequin is parsed to the PlannetData Knowledge Construction and we are able to now entry the person knowledge from it. The output for the above will probably be

We see that the key-value pairs from the JSON knowledge have been parsed appropriately to the Pydantic Knowledge. Let’s strive with one other planet and observe the output
input_prompt = planet_prompt.format_prompt(planet_name="venus")
output = llm(input_prompt.to_string())
parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital interval: ",parsed_output.orbital_period)
print("Distance From the Solar: ",parsed_output.distance_from_sun)
print("Attention-grabbing Truth: ",parsed_output.interesting_fact)
We see that for the enter “Venus”, the LLM was capable of generate a JSON because the output and it was efficiently parsed into Pydantic Knowledge. This manner, by way of output parsing, we are able to instantly make the most of the data generated by the Massive Language Fashions
Potential Functions and Use Circumstances
On this part, we’ll undergo some potential real-world purposes/use instances, the place we are able to make use of these output parsing methods. Use Parsing in extraction / after extraction, that’s once we extract any sort of knowledge, we wish to parse it in order that the extracted info may be consumed by different purposes. Among the purposes embody:
- Product Grievance Extraction and Evaluation: When a brand new model involves the market and releases its new merchandise, the very first thing it needs to do is examine how the product is performing, and top-of-the-line methods to judge that is to research social media posts of customers utilizing these merchandise. Output parsers and LLMs allow the extraction of knowledge, akin to model and product names and even complaints from a shopper’s social media posts. These Massive Language Fashions retailer this knowledge in Pythonic variables by way of output parsing, permitting you to put it to use for knowledge visualizations.
- Buyer Assist: When creating chatbots with LLMs for buyer help, one essential job will probably be to extract the data from the client’s chat historical past. This info accommodates key particulars like what issues the customers face with respect to the product/service. You’ll be able to simply extract these particulars utilizing LangChain output parsers as a substitute of making customized code to extract this info
- Job Posting Data: When growing Job search platforms like Certainly, LinkedIn, and so on, we are able to use LLMs to extract particulars from job postings, together with job titles, firm names, years of expertise, and job descriptions. Output parsing can save this info as structured JSON knowledge for job matching and proposals. Parsing this info from LLM output instantly by way of the LangChain Output Parsers removes a lot redundant code wanted to carry out this separate parsing operation.
Conclusion
Massive Language Fashions are nice, as they will actually match into each use case as a consequence of their extraordinary text-generation capabilities. However most frequently they fall quick in terms of really utilizing the output generated, the place we’ve got to spend a considerable period of time parsing the output. On this article, we’ve got taken a glance into this downside and the way we are able to clear up it utilizing the Output Parsers from LangChain, particularly the JSON parser that may parse the JSON knowledge generated from LLM and convert it to a Pydantic Object.
Key Takeaways
Among the key takeaways from this text embody:
- LangChain is a Python Library that may be create purposes with the prevailing Massive Language Fashions.
- LangChain offers Output Parsers that allow us parse the output generated by the Massive Language Fashions.
- Pydantic permits us to outline customized Knowledge Constructions, which can be utilized whereas parsing the output from the LLMs.
- Other than the Pydantic JSON parser, LangChain additionally offers totally different Output Parsers just like the Checklist Parser, Datetime Parser, Enum Parser, and so on.
Regularly Requested Questions
A. JSON, an acronym for JavaScript Object Notation, is a format for structured knowledge. It accommodates knowledge within the type of key-value pairs.
A. Pydantic is a Python library which creates customized knowledge constructions and carry out knowledge validation. It verifies whether or not every bit of knowledge matches the assigned sort, thereby validating the offered knowledge.
A. Do that with Immediate Engineering, the place tinkering with the Immediate may lead us to make the LLM generate JSON knowledge as output. To ease this course of, LangChain has Output Parsers and you should utilize for this job.
A. Output Parsers in LangChain enable us to format the output generated by the Massive Language Fashions in a structured method. This lets us simply entry the data from the Massive Language Fashions for different duties.
A. LangChain comes with totally different output parsers like Pydantic Parser, Checklist Parsr, Enum Parser, Datetime Parser, and so on.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.

{kind=link}