
One of many predominant hindrances to getting worth from our information is that we have now to get information right into a kind that’s prepared for evaluation. It sounds easy, however it not often is. Take into account the hoops we have now to leap by way of when working with semi-structured information, like JSON, in relational databases resembling PostgreSQL and MySQL.
JSON in Relational Databases
Previously, when it got here to working with JSON information, we’ve had to decide on between instruments and platforms that labored effectively with JSON or instruments that supplied good assist for analytics. JSON is an efficient match for doc databases, resembling MongoDB. It’s not such an important match for relational databases (though a quantity have carried out JSON capabilities and kinds, which we are going to talk about under).
In software program engineering phrases, that is what’s often called a excessive impedance mismatch. Relational databases are effectively suited to constantly structured information with the identical attributes showing again and again, row after row. JSON, alternatively, is effectively suited to capturing information that varies content material and construction, and has grow to be an especially widespread format for information trade.
Now, take into account what we have now to do to load JSON information right into a relational database. Step one is knowing the schema of the JSON information. This begins with figuring out all attributes within the file and figuring out their information sort. Some information sorts, like integers and strings, will map neatly from JSON to relational database information sorts.
Different information sorts require extra thought. Dates, for instance, might have to be reformatted or forged right into a date or datetime information sort.
Advanced information sorts, like arrays and lists, don’t map on to native, relational information buildings, so extra effort is required to take care of this example.
Technique 1: Mapping JSON to a Desk Construction
We might map JSON right into a desk construction, utilizing the database’s built-in JSON capabilities. For instance, assume a desk known as company_regions maintains tuples together with an id, a area, and a nation. One might insert a JSON construction utilizing the built-in json_populate_record perform in PostgreSQL, as within the instance:
INSERT INTO company_regions
SELECT *
FROM json_populate_record(NULL::company_regions,
'{"region_id":"10","company_regions":"British Columbia","nation":"Canada"}')
The benefit of this method is that we get the complete advantages of relational databases, like the flexibility to question with SQL, with equal efficiency to querying structured information. The first drawback is that we have now to take a position further time to create extraction, transformation, and cargo (ETL) scripts to load this information—that’s time that we might be analyzing information, as a substitute of remodeling it. Additionally, complicated information, like arrays and nesting, and surprising information, resembling a a mixture of string and integer sorts for a specific attribute, will trigger issues for the ETL pipeline and database.
Technique 2: Storing JSON in a Desk Column
An alternative choice is to retailer the JSON in a desk column. This characteristic is on the market in some relational database programs—PostgreSQL and MySQL assist columns of JSON sort.
In PostgreSQL for instance, if a desk known as company_divisions has a column known as division_info and saved JSON within the type of {"division_id": 10, "division_name":"Monetary Administration", "division_lead":"CFO"}, one might question the desk utilizing the ->> operator. For instance:
SELECT
division_info->>'division_id' AS id,
division_info->>'division_name' AS identify,
division_info->>'division_lead' AS lead
FROM
company_divisions
If wanted, we will additionally create indexes on information in JSON columns to hurry up queries inside PostgreSQL.
This method has the benefit of requiring much less ETL code to remodel and cargo the information, however we lose a number of the benefits of a relational mannequin. We will nonetheless use SQL, however querying and analyzing the information within the JSON column might be much less performant, on account of lack of statistics and fewer environment friendly indexing, than if we had remodeled it right into a desk construction with native sorts.
A Higher Various: Commonplace SQL on Absolutely Listed JSON
There’s a extra pure technique to obtain SQL analytics on JSON. As a substitute of making an attempt to map information that naturally suits JSON into relational tables, we will use SQL to question JSON information immediately.
Rockset indexes JSON information as is and supplies finish customers with a SQL interface for querying information to energy apps and dashboards.
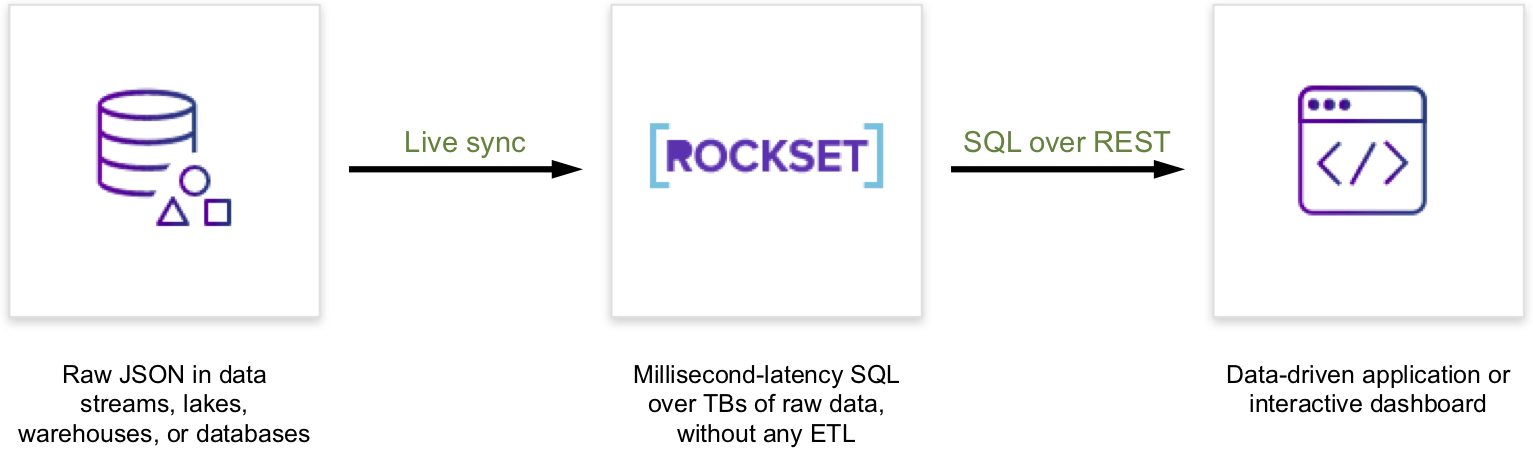
It repeatedly indexes new information because it arrives in information sources, so there aren’t any prolonged intervals of time the place the information queried is out of sync with information sources. One other profit is that since Rockset doesn’t want a hard and fast schema, customers can proceed to ingest and index from information sources even when their schemas change.
The efficiencies gained are evident: we get to depart behind cumbersome ETL code, reduce our information pipeline, and leverage mechanically generated indexes over all our information for higher question efficiency.

{kind=link}