
StoryFire is a social platform for content material creators to share and monetize their tales and movies. Utilizing Rockset to index information from their transactional MongoDB system, StoryFire powers advanced aggregation and be part of queries for his or her social and leaderboard options.
By transferring read-intensive providers off MongoDB to Rockset, StoryFire is ready to remedy two onerous challenges: efficiency and scale. The efficiency requirement is to serve low-latency queries in order that front-end purposes really feel snappy and responsive. The scaling problem introduces necessities for prime concurrency, the place serving elevated Queries Per Second (QPS) is crucial.
On this case research, we discover how StoryFire has simplified and scaled their real-time utility structure to future proof for big progress in consumer exercise. We discover one specific question “scorching spot” and present how Rockset can be utilized to dump computationally costly queries for unpredictable workloads.
Consumer Progress Brings Efficiency Challenges
Providing better assist for content material creators and elevated alternative for monetization, StoryFire is having fun with important progress in consumer exercise as customers migrate from different platforms to develop their follower exercise. These influencer migrations result in important spikes in website exercise the place concurrency turns into necessary in addition to sustaining a responsive utility.
The StoryFire expertise is implicitly actual time and information pushed in that customers count on to-the-second accuracy, throughout all gadgets. One in all these key options is for a consumer to have the ability to see what number of of their Tales have been seen during the last 90 days; a not unusual metric for any comparable analytics consumer dashboard. Question complexity smart, that is comparatively easy (with SQL JOINs) however excessive concurrency at the side of low latency is the problem.
Recognized as being a possible scorching spot for efficiency degradation as platform utilization will increase, the execution time can fluctuate relying upon the exercise of the consumer. Consequently, this kind of question is right to dump from MongoDB, the first transactional database, to Rockset, the place it may be scaled independently and with out doubtlessly ravenous assets from different crucial processes.
Rockset as a Pace Layer for MongoDB
Rockset could be considered a totally managed, click-and-connect “pace layer” for serving and scaling any information set. Generally, when Rockset is launched, many points of the general structure could be simplified; be it decreasing or eliminating ETL pipelines for transformations and denormalization, in addition to an total discount in complexity because of zero setup, administration and efficiency tuning.
MongoDB for Transactions
StoryFire chosen MongoDB hosted on the MongoDB Atlas cloud as their main transactional database, having fun with the advantages of each a scalable NoSQL doc retailer together with the consistency required for his or her transactional wants. Utilizing MongoDB Atlas permits StoryFire to make use of MongoDB as a cloud service, with out the necessity to construct and self-manage their very own cluster.
Rockset Integration
As famous, Rockset connects to different information sources and mechanically retains the information synchronized in actual time. Within the case of MongoDB, Rockset connects to the Change Knowledge Seize (CDC) stream from MongoDB Atlas. It is a zero-code integration and could be accomplished in a couple of minutes.
As soon as the preliminary connection has been made, Rockset will look at the information sizes inside Mongo and mechanically ramp up ingest assets for the preliminary “bulk load.” As soon as full, Rockset will then scale the ingest assets again down and proceed consuming any ongoing adjustments. One of many key architectural advantages right here is that Rockset collections could be synchronized with MongoDB collections individually and therefore solely the information wanted for the use case want be synchronized. This aligns effectively with a microservices structure.
Software Integration
Rockset permits customers to avoid wasting, model and publish SQL queries by way of HTTP in order that these assets could be quickly applied in front-end purposes and accessed by any programming language that helps HTTP. These RESTful assets are known as Question Lambdas. Question Lambdas additionally enable parameters to be handed at request time. On this instance, the StoryFire consumer interface lets customers look again over 30, 60 and 90 days, in addition to in fact the question must be particular for a person hostID. These are very best candidates for parameters. You possibly can learn extra about Question Lambdas right here.
Digital Situations
The ultimate function of word is the power to scale Rockset’s compute assets, with out downtime inside a minute or two. We time period the compute assets allotted to an account digital situations which include a set variety of vCPUs and related reminiscence. With altering occasion varieties being a zero-downtime operation, its very simple for patrons like StoryFire to set a value/efficiency ratio they’re pleased with and likewise, alter based mostly on altering wants.
Setting up Queries on Consumer Exercise
StoryFire information is organized into a number of collections. The Consumer assortment defines all of the customers and their ids. The Occasion assortment captures each new story printed and the EventViews assortment data a brand new entry each time a consumer views a narrative.
The question in query entails a JOIN between two collections: Occasions and EventViews the place an Occasion can have many EventViews. As with many different analytical workloads, the objective right here is to combination some metric throughout a selected subset of data and consider the development over time.
SELECT
SUM(v."rely"),
DATE(v.timestamp) AS day,
FROM
EventViews v
INNER JOIN Occasions s ON v.fbId = s.fbId
WHERE
s.hostID = '[user specific id]'
AND
s.hasVideo = true
AND v.timestamp > CURRENT_TIMESTAMP() - DAYS(90)
group by
day
order by
day DESC;
This yields a end result set like the next:

Rockset mechanically generates Row, Column, and Inverted indexes, and based mostly on the actual predicates in query, the optimizer takes probably the most environment friendly path of execution. For instance if the hostId predicate matched many tens of millions of rows the column index could be chosen as a result of it’s extremely optimized for big vary scans. Nevertheless if solely a small fraction of the rows matched the predicate, we might use the inverted index to rapidly establish these rows in a matter of milliseconds. This automated indexing reduces the operational burden that DBAs usually shoulder sustaining indexes, and it permits builders and analysts to write down SQL with out worrying about sluggish, unindexed queries losing their time or stalling their purposes.
Fixing for Efficiency and Scale
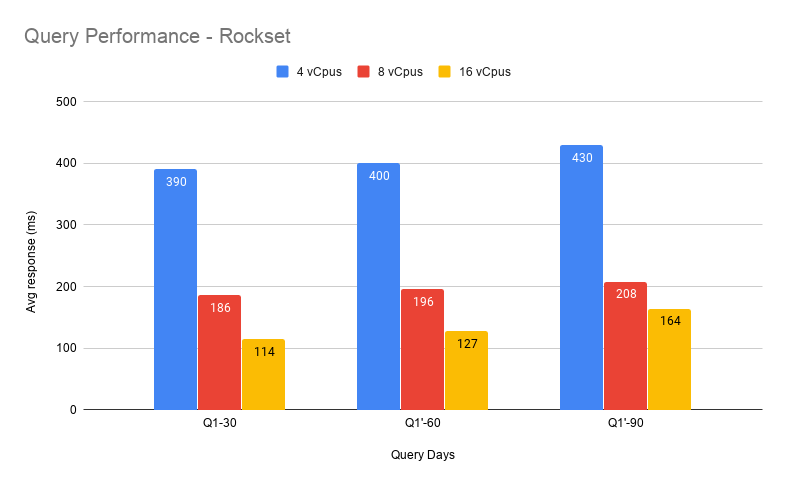
The SQL question was examined for Rockset and the historic days worth was examined at 30, 60 and 90.
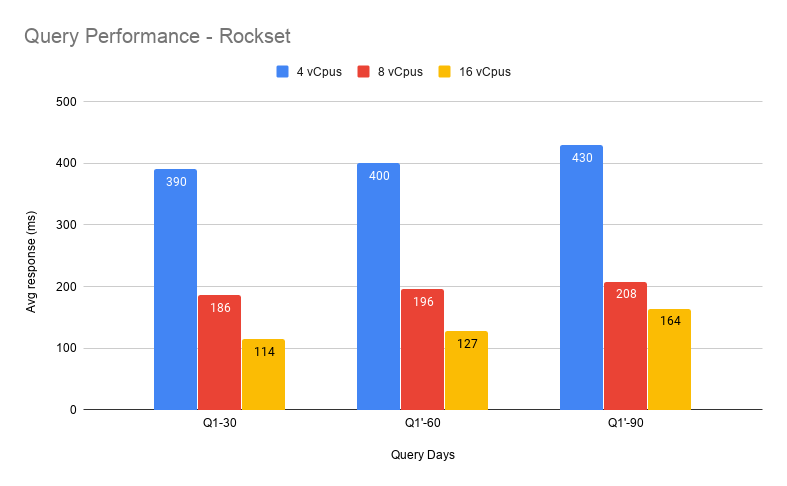
We will see right here that because the vary of information to be queried will increase (variety of days), the Rockset efficiency stays roughly comparable. Whereas response time for this question goes up in proportion to information measurement when querying MongoDB straight, Rockset’s question response time doesn’t enhance materially even once we go from 30 to 90 days of information. This demonstrates the ability and effectivity of the Converged Indexes together with the question optimizer. It’s value noting that within the take a look at question, a consumer ID was used that had a number of hundred be part of IDs and therefore was comparatively costly to run. The identical question for customers with decrease information volumes will execute in double digit ms vary.
General, the outcomes reveal the scaling functionality of Rockset. Because the compute is elevated, the efficiency will increase proportionally. Given it is a zero downtime and quick operation, it’s simple to scale up and down as wanted.
From an architectural perspective, an costly question was moved on to Rockset the place it may well make the most of large parallel execution in addition to providing the power to scale up and down compute assets as wanted. Lowering the advanced learn burden from a transactional system like Mongo permits efficiency to stay constant for the core transactional workloads.
We’re excited to accomplice with StoryFire on their scaling journey.

Different MongoDB assets:

{kind=link}