
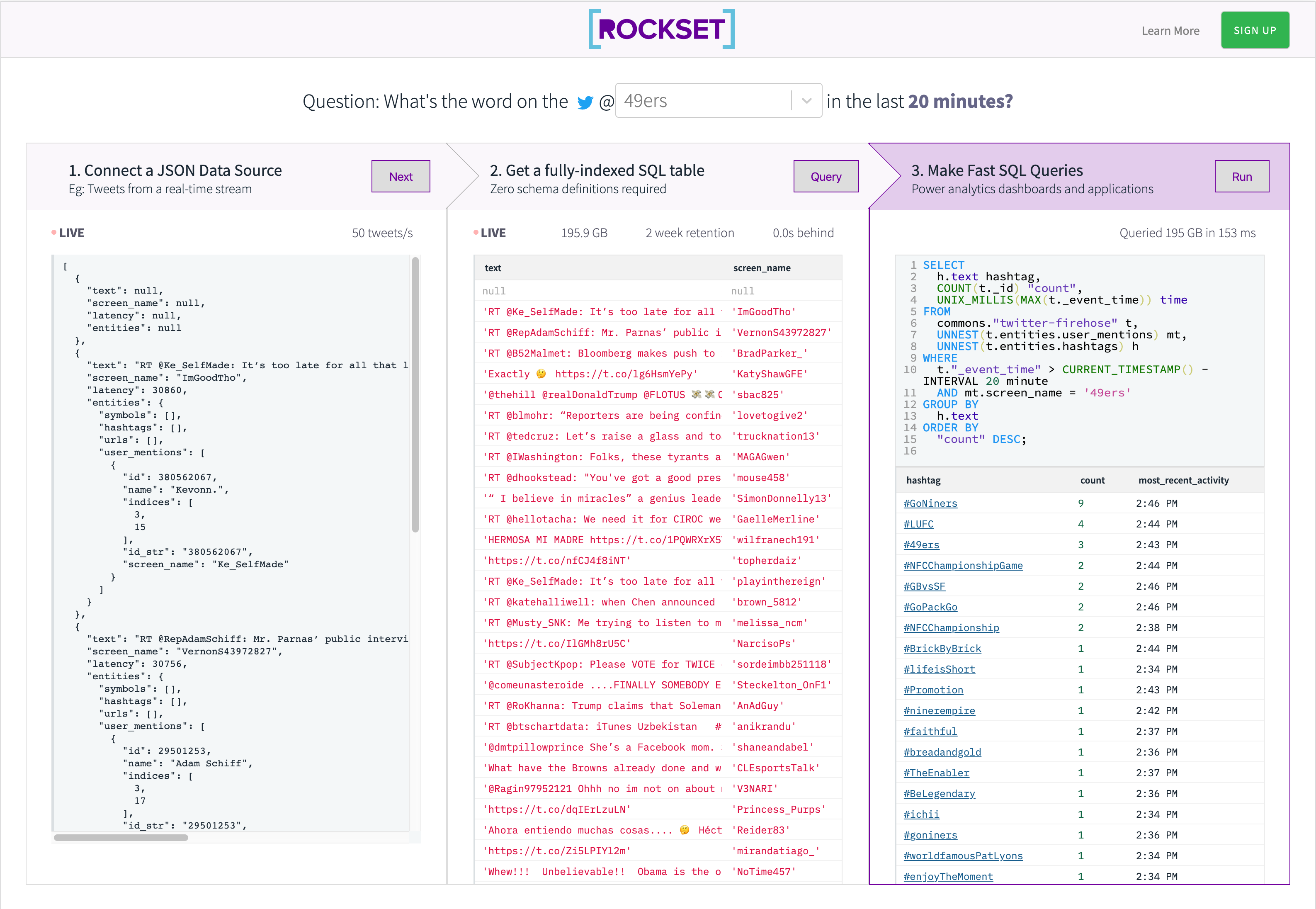
On this weblog we’ll arrange a real-time SQL API on Kafka utilizing AWS Lambda and Rockset.
On the time of writing (in early 2020) the San Francisco 49ers are doing remarkably nicely! To honor their success, we’ll concentrate on answering the next query.
What are the preferred hashtags in tweets that talked about the 49ers within the final 20 minutes?
As a result of Twitter strikes quick, we’ll solely have a look at very current tweets.
We will even present the right way to make the identical API and question work for any of the groups within the NFL.
There are 3 steps to get began.
- Load the Twitter Stream into Rockset.
- Get a quick SQL Desk
- Energy your API
Step 0: Setup
This tutorial assumes you’ve gotten already arrange a Rockset Account, an AWS account (for the lambda), and a Twitter Growth Account (for the twitter stream).
If you have already got knowledge you wish to construct an API on skip to Step 1.
The Kafka arrange directions for the rest of this tutorial are for Confluent Kafka. Observe the instructions under to set it up in the event you don’t have a Kafka set up to experiment with.
Elective: Arrange Confluent Kafka regionally
First you need to arrange Confluent Hub Platform, the Confluent Hub consumer and the Confluent CLI.
# Begin up a neighborhood model of Kafka.
confluent native begin
It’s best to see a number of companies begin.
Navigate to the Kafka UI at http://localhost:9021/ to verify it really works correctly.
Organising the Twitter Connector
Set up Kafka Join Twitter in addition to the Rockset Kafka Connector.
confluent-hub set up jcustenborder/kafka-connect-twitter:0.3.33
confluent-hub set up rockset/kafka-connect-rockset:1.2.1
# restart Kafka in case you are operating regionally
confluent native cease
confluent native begin
Now navigate to the Kafka UI, choose your cluster, and create a subject known as “rockset-kafka”. Then add the Twitter connector to your cluster, and level them each to the subject you simply made. You’ll need to place in your twitter-dev account info for the Twitter Connector. Subscribe to the next matters to see soccer associated outcomes.
49ers Broncos packers Raiders Giants Redskins MiamiDolphins Buccaneers Seahawks Nyjets Ravens Bengals Titans HoustanTexans Dallascowboys Browns Colts AtlantaFalcons Vikings Lions Patriots RamsNFL steelers Jaguars BuffaloBills Chiefs Saints AZCardinals Panthers Eagles ChicagoBears Chargers NFL SportsNews American soccer Draft ESPN
Click on create. It’s best to now see many tweets flowing by the subject “rockset-kafka”.
Troubleshooting: in case you have points, double test your credentials. You may as well test the Kafka logs.
# Regionally
confluent native log join
Step 1: Load the Kafka Stream into Rockset
Organising the Rockset Connector
- Should you haven’t already, set up the Rockset Kafka Connector in your Kafka cluster, and level it to “rockset-kafka”
- Log in to Rockset Console and navigate to the Create Kafka Integration at Handle > Integrations > Kafka.
- Identify your integration, set the content material sort to AVRO, and add a subject known as “rockset-kafka”.
- Observe the Kafka connector set up directions on the Integration Particulars web page that you just land on whenever you end creating the mixing.
- There are additional directions at https://docs.rockset.com/apache-kafka/.
Elective: Native Kafka
If you’re utilizing a neighborhood standalone Kafka, skip to Step 3 of the directions on the set up web page. Set the Schema Registry Occasion to be http://localhost:8081 (which is the default port of the schema-registry service) and click on “Obtain Rockset Sink Connector Properties” to get a properties file that ought to offer you the entire variables it is advisable to arrange to make use of Rockset with Kafka.
Here’s a pattern properties file that ought to look much like yours:
identify=twitter-kafka
connector.class=rockset.RocksetSinkConnector
duties.max=10
matters=rockset-kafka
rockset.activity.threads=5
rockset.apiserver.url=https://api.rs2.usw2.rockset.com
rockset.integration.key=kafka://<secret>@api.rs2.usw2.rockset.com
format=AVRO
key.converter=io.confluent.join.avro.AvroConverter
key.converter.schema.registry.url=http://localhost:8081
worth.converter=io.confluent.join.avro.AvroConverter
worth.converter.schema.registry.url=http://localhost:8081
On the Kafka UI join web page, choose your cluster and click on Add Connector. Choose the RocksetSinkConnector. Lastly, fill in the entire properties from the connect-rockset-sink.properties file you downloaded from the Rockset Console.
As soon as you’re carried out, click on Create. You are actually able to create a Kafka Assortment in Rockset!
Making a Kafka Assortment in Rockset
Navigate to the Rockset Console and go to Collections > Create Assortment > Kafka. Choose the mixing you created within the earlier step and click on Begin.
Identify your assortment, and choose the subject “rockset-kafka”. Look forward to just a few moments and it is best to see paperwork coming into the preview. This implies your connectors are configured appropriately! Go forward and set a retention coverage and create your assortment.
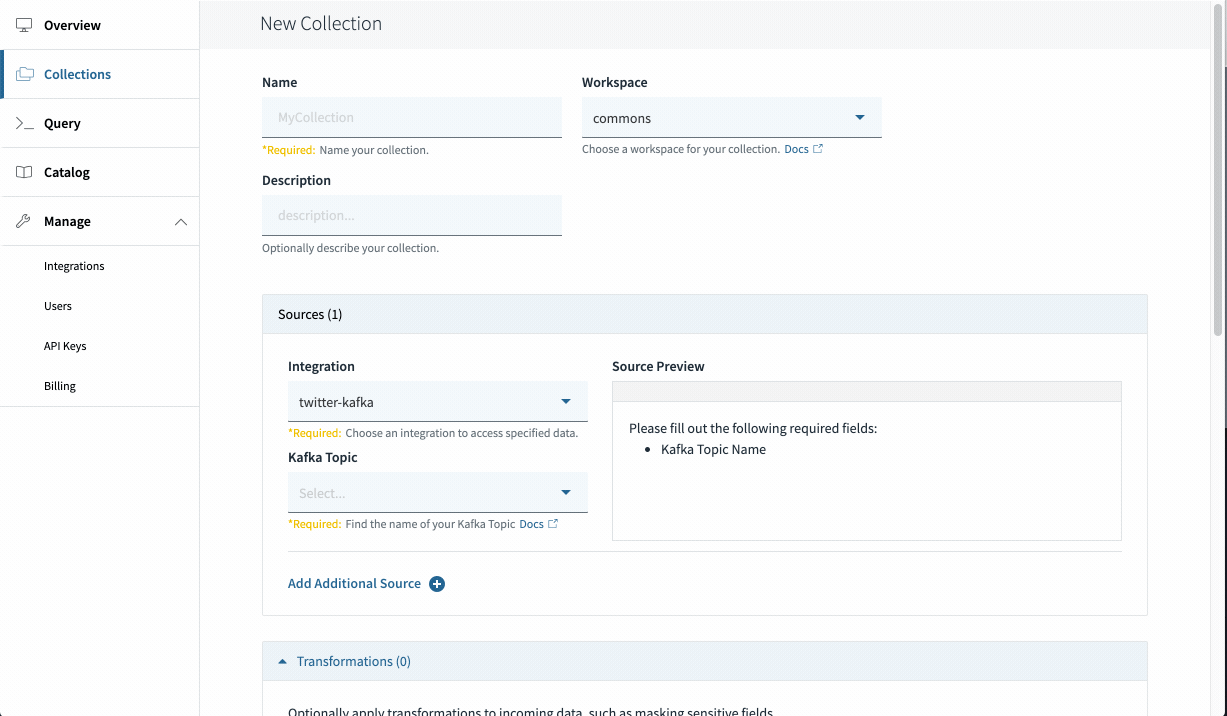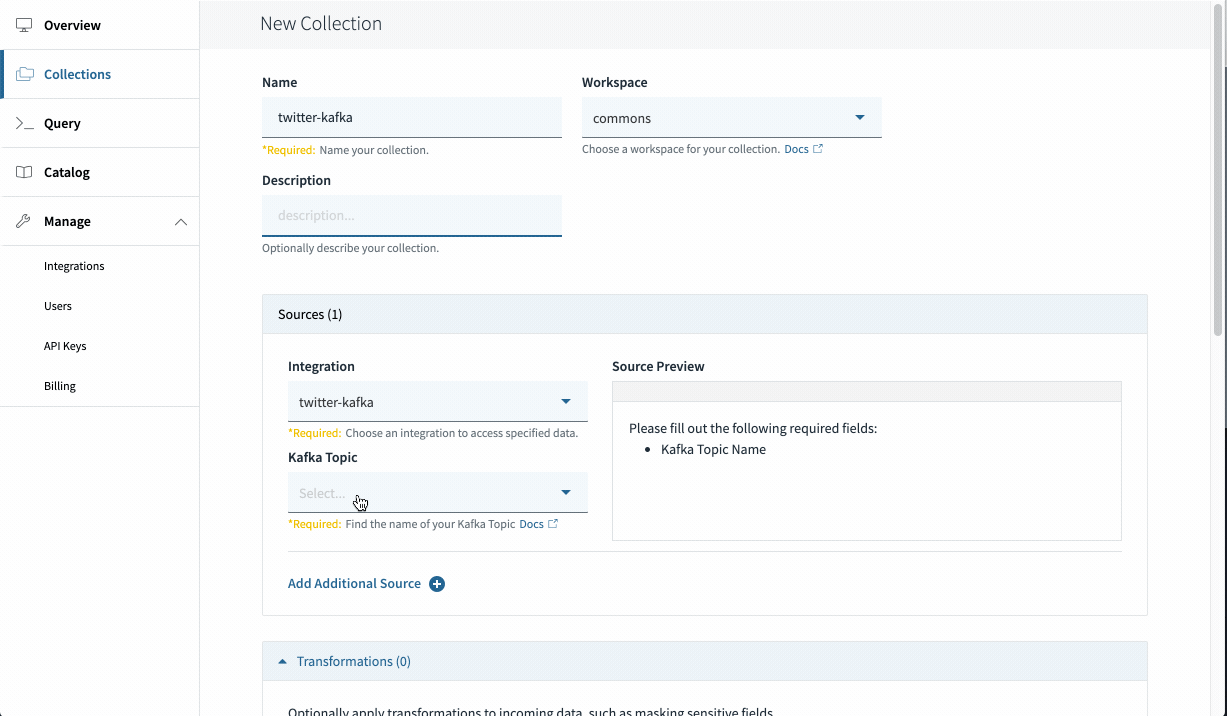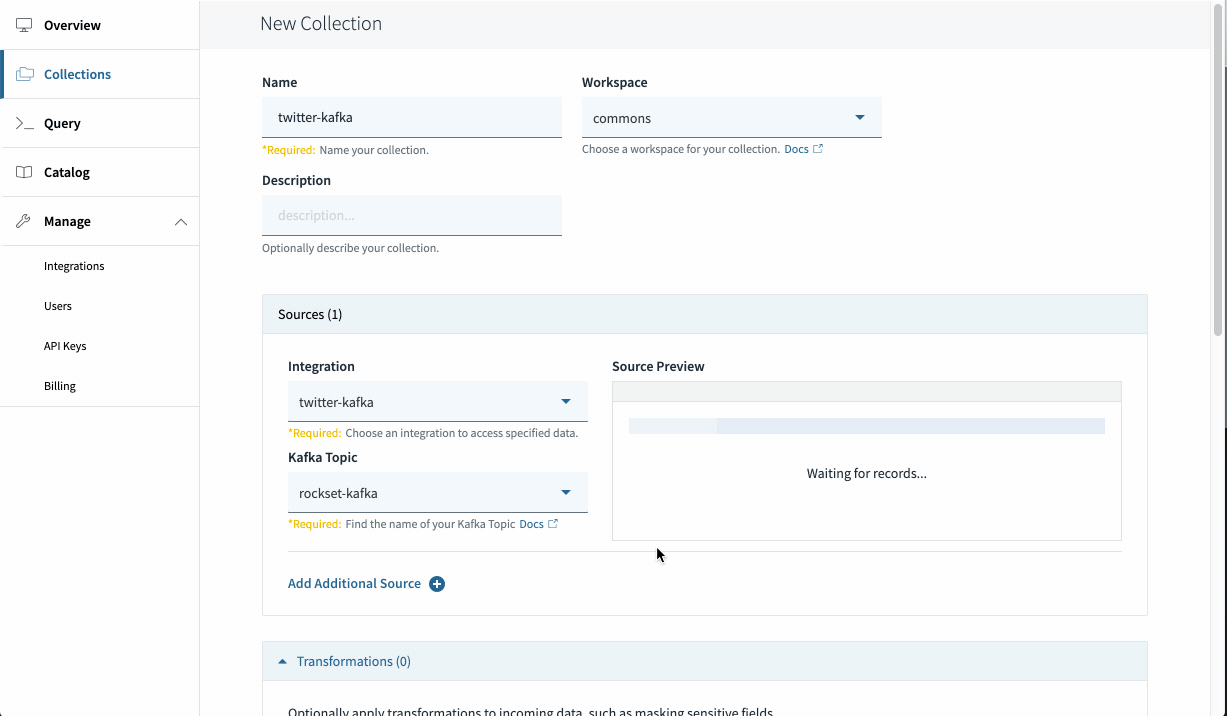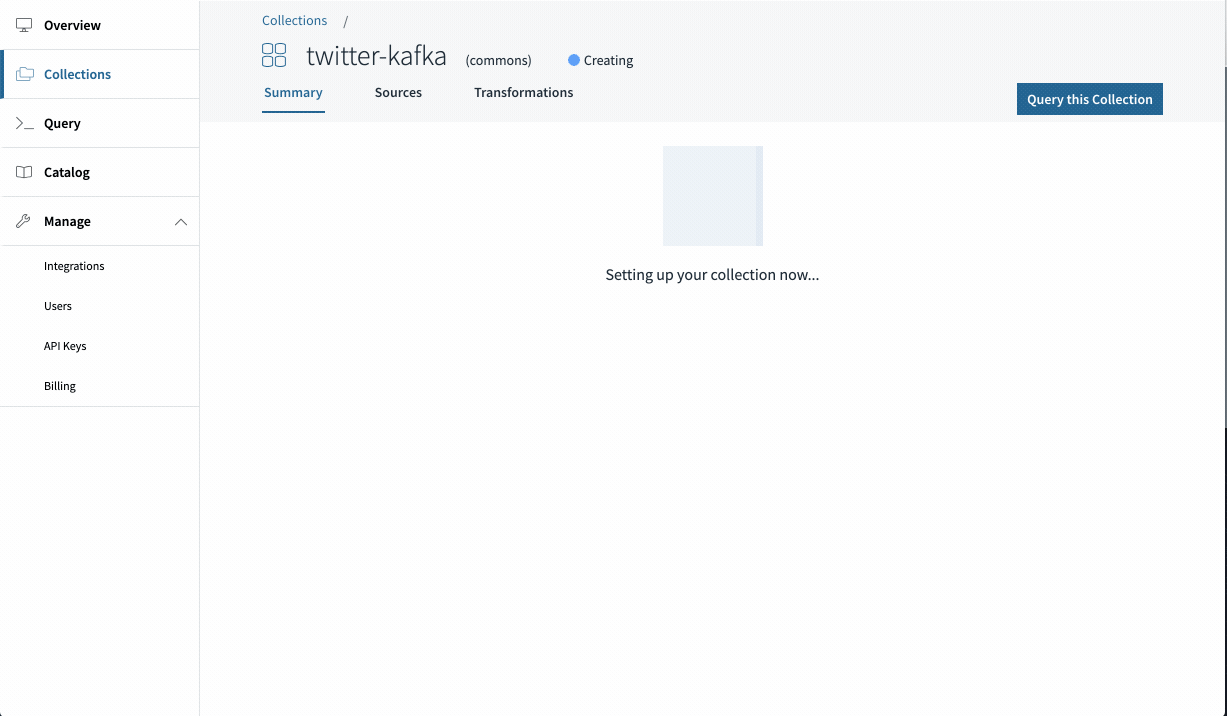
Congratulations! You may have efficiently created a Kafka assortment in Rockset.
Step 2: Get a quick SQL Desk.
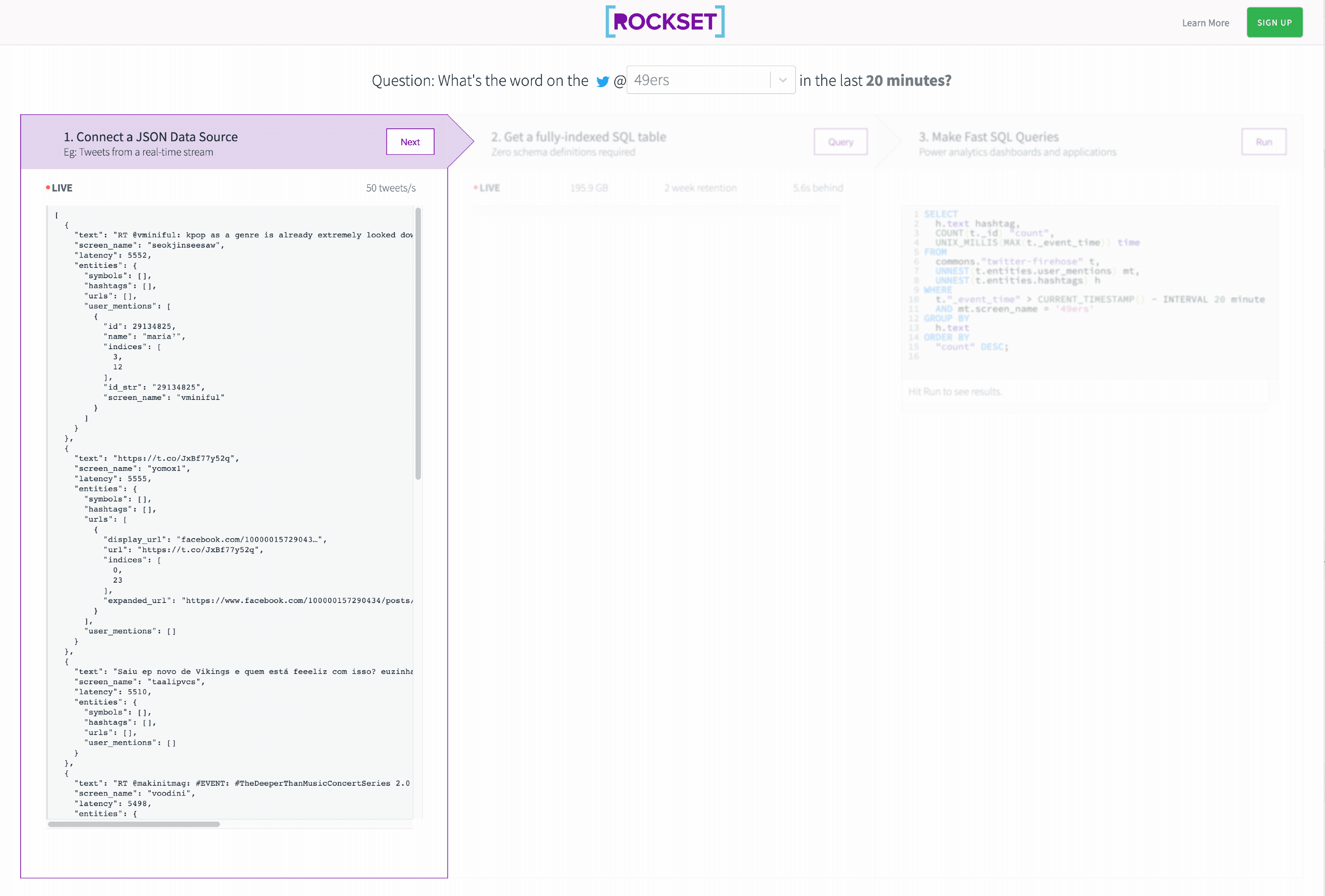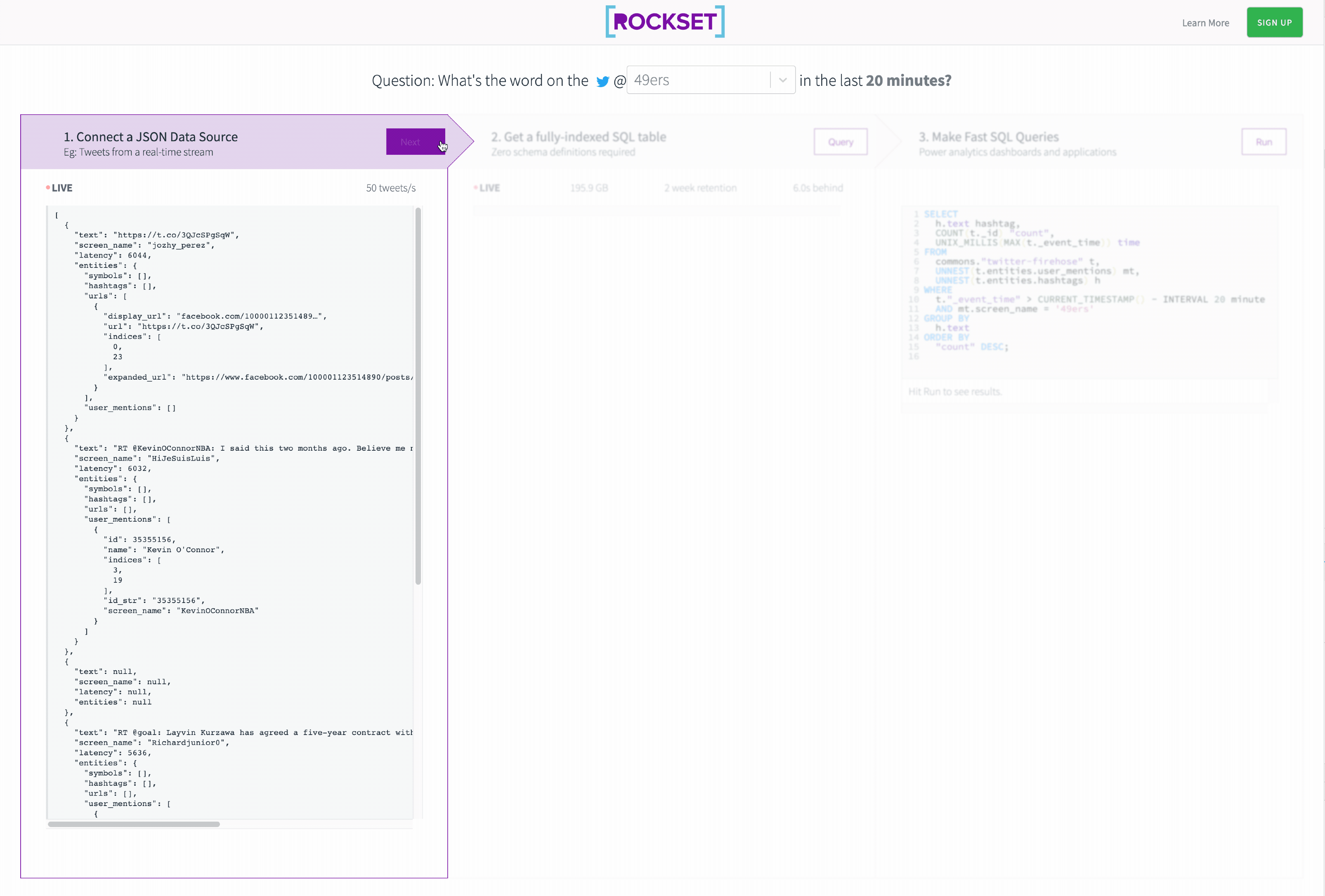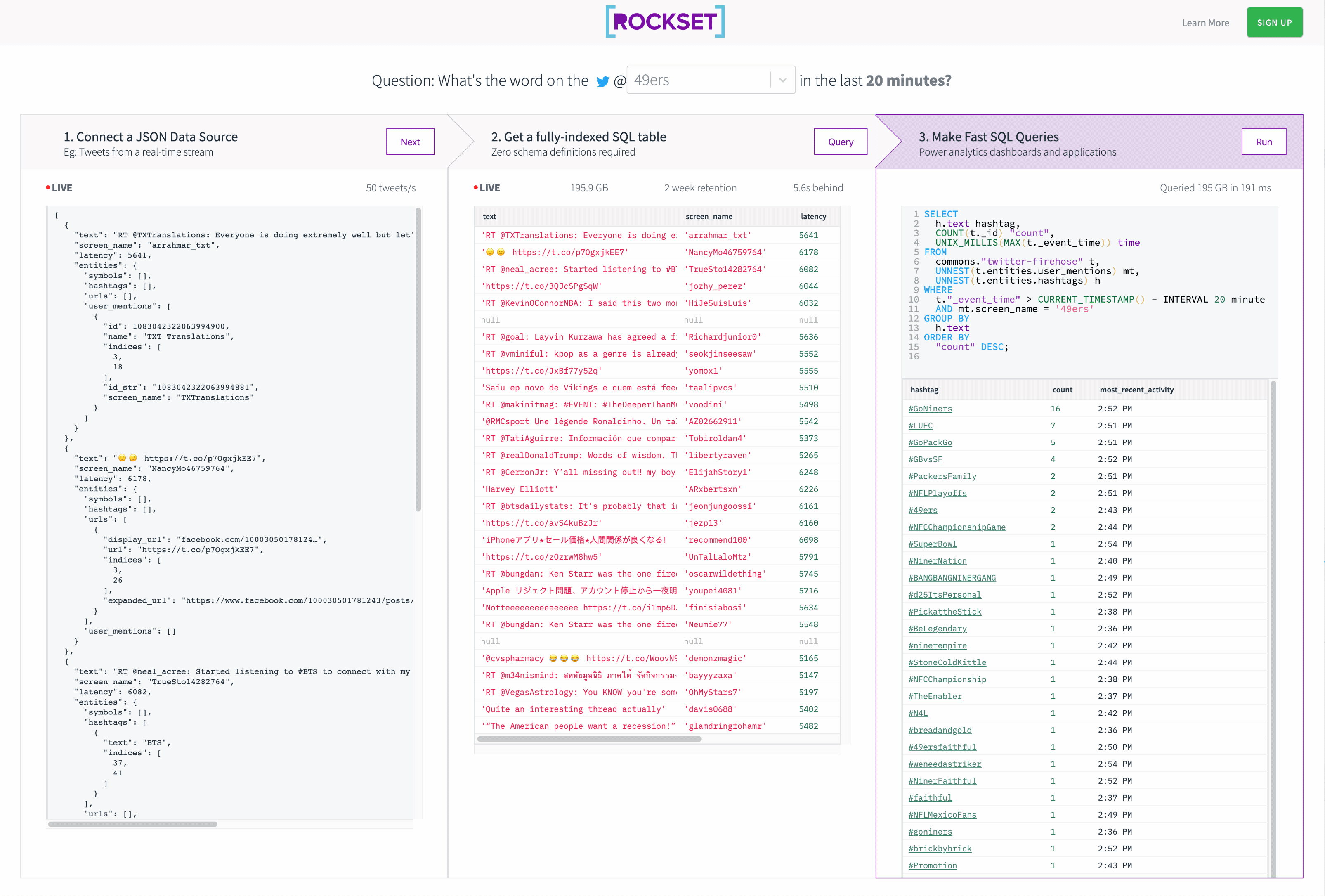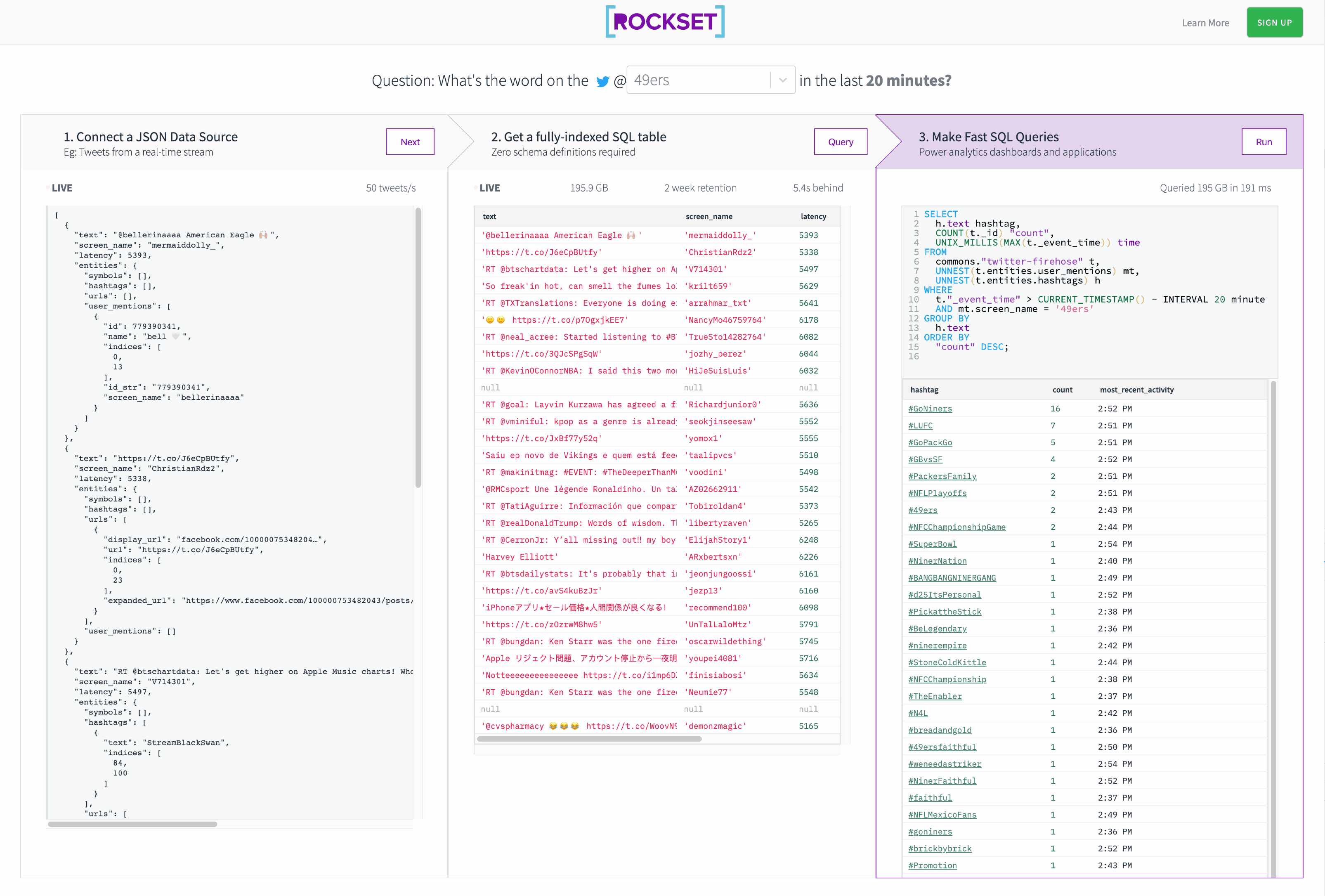
Our driving query is: What are the preferred hashtags in tweets that talked about the 49ers within the final 20 minutes?
Let”s discover the info slightly bit within the Rockset Console and develop our question.
If we glance on the left facet of the console, we see that the twitter knowledge is a stream of big json objects nested in complicated methods. The fields we care about most to reply our driving query are:
- entities.user_mentions (an array of mentions for a specific tweet)
- entities.hashtags (an array of hashtags in a specific tweet)
We additionally care in regards to the following two system fields
_id(distinctive discipline for every tweet)_event_time(time {that a} tweet was ingested into Rockset)
To reply our query, we wish to discover all tweets the place a minimum of one user_mention is @49ers. Then we have to mixture over all hashtags to depend what number of of every one there may be.
However how will we filter and mixture over nested arrays? Enter the UNNEST command. Unnest takes a single row in our desk that accommodates an array (of size n) and multiplies it into n rows that every include a component of the unique array.
We thus wish to unnest mentions and hashtags, and filter by mentions.
SELECT
h.hashtags.textual content hashtag
FROM
commons."twitter-kafka" t,
unnest(t.entities.hashtags hashtags) h,
unnest(t.entities.mentions mentions) mt
WHERE
mt.mentions.screen_name="49ers"
LIMIT 10;
This returns the entire hashtags in tweets mentioning the 49ers. Let’s mixture over the hashtags, calculate a depend, then kind by the depend.
SELECT
h.hashtags.textual content hashtag,
depend(t._id) "depend"
FROM
commons."twitter-kinesis" t,
unnest(t.entities.user_mentions mentions) mt,
unnest(t.entities.hashtags hashtags) h
WHERE
mt.mentions.screen_name="49ers"
GROUP BY
h.hashtags.textual content
ORDER BY
"depend" DESC;
Lastly we filter to solely embody tweets within the final 20 minutes. Moreover, we exchange ’49ers’ with a Rockset Question Parameter. This can allow us to make use of totally different question parameters from the Rockset REST API.
SELECT
h.hashtags.textual content hashtag,
depend(t._id) "depend",
UNIX_MILLIS(MAX(t._event_time)) time
FROM
commons."twitter-kinesis" t,
unnest(t.entities.user_mentions mentions) mt,
unnest(t.entities.hashtags hashtags) h
WHERE
t."_event_time" > CURRENT_TIMESTAMP() - INTERVAL 20 minute
and mt.mentions.screen_name = :crew
GROUP BY
h.hashtags.textual content
ORDER BY
"depend" DESC;
Go 49ers!
Step 3: Energy your API
We will already execute queries over HTTP with Rockset’s REST API. The issue is that utilizing the REST API requires you to move a secret API key. If we’re making a public dashboard, we don’t wish to reveal our API key. We additionally don’t wish to expose our Rockset account to a DOS assault, and management account bills.
The answer is to make use of an AWS Lambda to cover the API key and to set a Reserve Concurrency to restrict the quantity of compute we have now to make use of. Within the following part, we’ll undergo the method of writing a Node.js lambda utilizing the Rockset Node.js API.
Writing a lambda
Writing the lambda is fast and soiled utilizing the rockset-node-client v2. We simply run the question on the question route and move within the question string parameters. This could execute the specified question with the specified parameters. Rockset routinely handles escaping parameters for us, so we don’t want to fret about that.
- Be sure to have nodejs 12.x and npm put in
- In an empty listing, run
npm i rockset - Paste the lambda code under into
index.jswithin the root of the listing
const rocksetConfigure = require("rockset").default;
const APIKEY = course of.env.ROCKSET_APIKEY;
const API_ENDPOINT = "https://api.rs2.usw2.rockset.com";
const consumer = rocksetConfigure(APIKEY, API_ENDPOINT);
const wrapResult = res => ({
statusCode: 200,
headers: {
"Entry-Management-Enable-Origin": "*",
"Entry-Management-Enable-Credentials": true
},
physique: JSON.stringify(res),
isBase64Encoded: false
});
const wrapErr = mes => ({
statusCode: 400,
errorMessage: JSON.stringify(mes),
isBase64Encoded: false
});
const question = `
SELECT
h.hashtags.textual content hashtag,
Depend(t._id) "depend",
UNIX_MILLIS(MAX(t._event_time)) time
FROM
commons."twitter-kinesis" t,
unnest(t.entities.user_mentions mentions) mt,
unnest(t.entities.hashtags hashtags) h
WHERE
t."_event_time" > CURRENT_TIMESTAMP() - INTERVAL 20 minute
and mt.mentions.screen_name = :crew
GROUP BY
h.hashtags.textual content
ORDER BY
"depend" DESC;
`;
exports.handler = async (occasion, context) =>
occasion.queryStringParameters && occasion.queryStringParameters.param
? consumer.queries
.question({
sql: {
question,
parameters: [
{
name: "team",
type: "string",
value: event.queryStringParameters.param
}
]
}
})
.then(wrapResult)
: wrapErr("Want parameters for question");
Nonetheless, we have to package deal the rockset dependency together with the lambda code with the intention to deploy to aws. So as to take action, we zip our entire listing, together with node_modules, and use that to deploy.
Our ultimate listing construction seems like:
├── index.js
├── node_modules
└── package-lock.json
Deploying our lambda to AWS
- First we’ll create a lambda. Go to your AWS console, go to the lambda instrument.
- Click on “Create Perform”, then click on “From Scratch”
- Choose a runtime of Node.js 12.x.
- Add the zip we created within the earlier step.
- Add an surroundings variable known as ROCKSET_APIKEY, and set it to your API key
-
Execute the lambda with the next take a look at json.
{ "queryStringParameters": { "param": "49ers" } } -
It’s best to see a inexperienced run with an output much like the next.
{ "statusCode":200, "headers":{ "Entry-Management-Enable-Origin":"*", "Entry-Management-Enable-Credentials":true }, "physique":"{"outcomes":[{"text":"to-mah-to", ..." . . . } - Finally, make sure to set a Reserve Concurrency to limit costs associated with the lambda.
Congratulations! If the test JSON returned the correct output, you set up your lambda correctly. We can now move on to configuring an API gateway to use this lambda.
Configure an API Gateway
Next we will configure an API Gateway to receive api requests and pass them to our lambda. There are several tutorials that describe this process in detail.
Once you have set up your api, you can send a request directly from your browser, or use codepen. Just modify the lambda URL to be your lambda and you should see some result tweets!
Conclusion
In this tutorial, we created a SQL API on Kafka in 3 easy steps that let us slice the Twitter Streaming API in real time.
See the final result below!

{kind=link}