


A grand imaginative and prescient in robotic studying, going again to the SHRDLU experiments within the late Nineteen Sixties, is that of useful robots that inhabit human areas and comply with all kinds of pure language instructions. Over the previous few years, there have been important advances within the utility of machine studying (ML) for instruction following, each in simulation and in actual world programs. Latest Palm-SayCan work has produced robots that leverage language fashions to plan long-horizon behaviors and motive about summary targets. Code as Insurance policies has proven that code-generating language fashions mixed with pre-trained notion programs can produce language conditioned insurance policies for zero shot robotic manipulation. Regardless of this progress, an vital lacking property of present “language in, actions out” robotic studying programs is actual time interplay with people.
Ideally, robots of the long run would react in actual time to any related process a person may describe in pure language. Significantly in open human environments, it might be vital for finish customers to customise robotic conduct as it’s taking place, providing fast corrections (“cease, transfer your arm up a bit”) or specifying constraints (“nudge that slowly to the appropriate”). Moreover, real-time language may make it simpler for individuals and robots to collaborate on advanced, long-horizon duties, with individuals iteratively and interactively guiding robotic manipulation with occasional language suggestions.
 |
| The challenges of open-vocabulary language following. To be efficiently guided by way of a protracted horizon process like “put all of the blocks in a vertical line”, a robotic should reply exactly to all kinds of instructions, together with small corrective behaviors like “nudge the crimson circle proper a bit”. |
Nonetheless, getting robots to comply with open vocabulary language poses a big problem from a ML perspective. This can be a setting with an inherently giant variety of duties, together with many small corrective behaviors. Current multitask studying setups make use of curated imitation studying datasets or advanced reinforcement studying (RL) reward capabilities to drive the educational of every process, and this important per-task effort is tough to scale past a small predefined set. Thus, a essential open query within the open vocabulary setting is: how can we scale the gathering of robotic knowledge to incorporate not dozens, however tons of of 1000’s of behaviors in an setting, and the way can we join all these behaviors to the pure language an finish person may really present?
In Interactive Language, we current a big scale imitation studying framework for producing real-time, open vocabulary language-conditionable robots. After coaching with our strategy, we discover that an particular person coverage is succesful of addressing over 87,000 distinctive directions (an order of magnitude bigger than prior works), with an estimated common success price of 93.5%. We’re additionally excited to announce the discharge of Language-Desk, the biggest accessible language-annotated robotic dataset, which we hope will drive additional analysis targeted on real-time language-controllable robots.
| Guiding robots with actual time language. |
Actual Time Language-Controllable Robots
Key to our strategy is a scalable recipe for creating giant, numerous language-conditioned robotic demonstration datasets. In contrast to prior setups that outline all the abilities up entrance after which accumulate curated demonstrations for every ability, we constantly accumulate knowledge throughout a number of robots with out scene resets or any low-level ability segmentation. All knowledge, together with failure knowledge (e.g., knocking blocks off a desk), goes by way of a hindsight language relabeling course of to be paired with textual content. Right here, annotators watch lengthy robotic movies to establish as many behaviors as attainable, marking when every started and ended, and use freeform pure language to explain every section. Importantly, in distinction to prior instruction following setups, all abilities used for coaching emerge backside up from the information itself relatively than being decided upfront by researchers.
Our studying strategy and structure are deliberately easy. Our robotic coverage is a cross-attention transformer, mapping 5hz video and textual content to 5hz robotic actions, utilizing a normal supervised studying behavioral cloning goal with no auxiliary losses. At check time, new spoken instructions could be despatched to the coverage (by way of speech-to-text) at any time as much as 5hz.
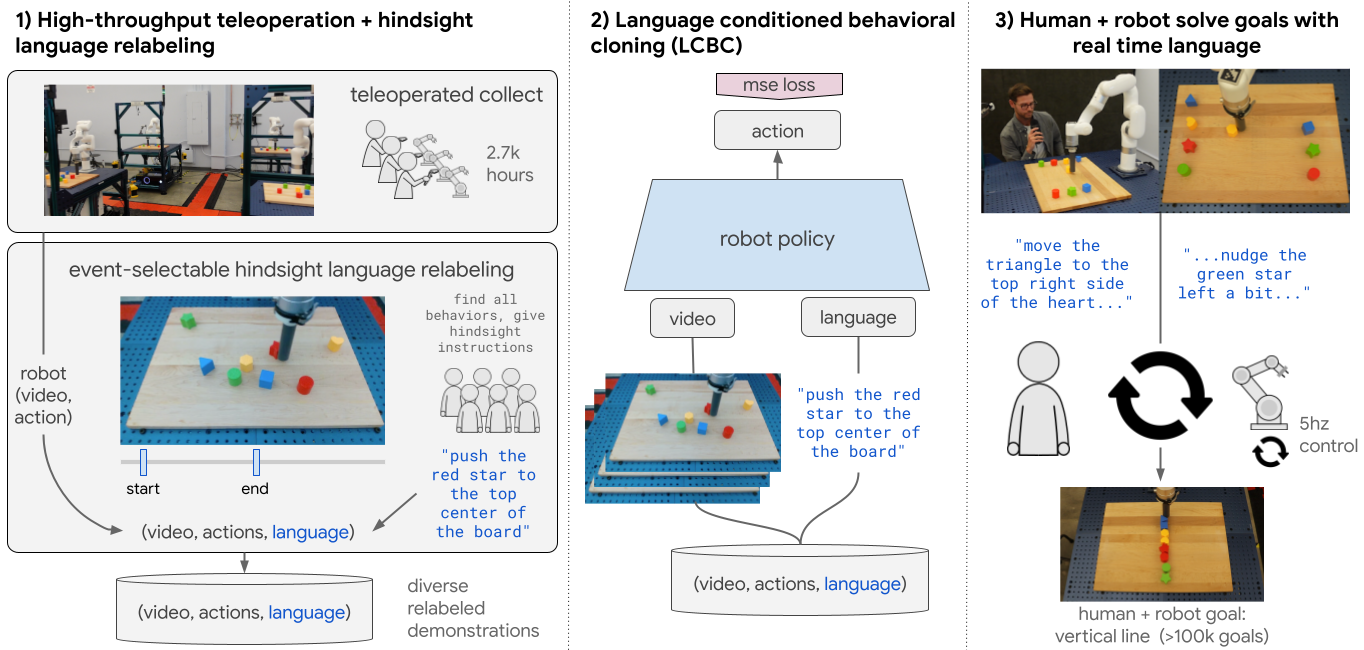 |
| Interactive Language: an imitation studying system for producing actual time language-controllable robots. |
Open Supply Launch: Language-Desk Dataset and Benchmark
This annotation course of allowed us to gather the Language-Desk dataset, which incorporates over 440k actual and 180k simulated demonstrations of the robotic performing a language command, together with the sequence of actions the robotic took throughout the demonstration. That is the biggest language-conditioned robotic demonstration dataset of its variety, by an order of magnitude. Language-Desk comes with a simulated imitation studying benchmark that we use to carry out mannequin choice, which can be utilized to judge new instruction following architectures or approaches.
| Dataset | # Trajectories (ok) | # Distinctive (ok) | Bodily Actions | Actual | Out there |
| Episodic Demonstrations | |||||
| BC-Z | 25 |
0.1 |
✓ | ✓ | ✓ |
| SayCan | 68 |
0.5 |
✓ | ✓ | ❌ |
| Playhouse | 1,097 |
779 |
❌ | ❌ | ❌ |
| Hindsight Language Labeling | |||||
| BLOCKS | 30 |
n/a | ❌ | ❌ | ✓ |
| LangLFP | 10 |
n/a | ✓ | ❌ | ❌ |
| LOREL | 6 |
1.7 |
✓ | ✓ | ✓ |
| CALVIN | 20 |
0.4 |
✓ | ❌ | ✓ |
| Language-Desk (actual + sim) | 623 (442+181) | 206 (127+79) | ✓ | ✓ | ✓ |
| We evaluate Language-Desk to current robotic datasets, highlighting proportions of simulated (crimson) or actual (blue) robotic knowledge, the variety of trajectories collected, and the variety of distinctive language describable duties. |
Discovered Actual Time Language Behaviors
 |
| Examples of brief horizon directions the robotic is able to following, sampled randomly from the complete set of over 87,000. |
| Brief-Horizon Instruction | Success |
| (87,000 extra…) | … |
| push the blue triangle to the highest left nook | 80.0% |
| separate the crimson star and crimson circle | 100.0% |
| nudge the yellow coronary heart a bit proper | 80.0% |
| place the crimson star above the blue dice | 90.0% |
| level your arm on the blue triangle | 100.0% |
| push the group of blocks left a bit | 100.0% |
| Common over 87k, CI 95% | 93.5% +- 3.42% |
| 95% Confidence interval (CI) on the common success of a person Interactive Language coverage over 87,000 distinctive pure language directions. |
We discover that attention-grabbing new capabilities come up when robots are in a position to comply with actual time language. We present that customers can stroll robots by way of advanced long-horizon sequences utilizing solely pure language to unravel for targets that require a number of minutes of exact, coordinated management (e.g., “make a smiley face out of the blocks with inexperienced eyes” or “place all of the blocks in a vertical line”). As a result of the robotic is educated to comply with open vocabulary language, we see it may well react to a various set of verbal corrections (e.g., “nudge the crimson star barely proper”) which may in any other case be tough to enumerate up entrance.
 |
| Examples of lengthy horizon targets reached underneath actual time human language steerage. |
Lastly, we see that actual time language permits for brand spanking new modes of robotic knowledge assortment. For instance, a single human operator can management 4 robots concurrently utilizing solely spoken language. This has the potential to scale up the gathering of robotic knowledge sooner or later with out requiring undivided human consideration for every robotic.
 |
| One operator controlling a number of robots directly with spoken language. |
Conclusion
Whereas presently restricted to a tabletop with a set set of objects, Interactive Language reveals preliminary proof that enormous scale imitation studying can certainly produce actual time interactable robots that comply with freeform finish person instructions. We open supply Language-Desk, the biggest language conditioned real-world robotic demonstration dataset of its variety and an related simulated benchmark, to spur progress in actual time language management of bodily robots. We imagine the utility of this dataset might not solely be restricted to robotic management, however might present an attention-grabbing start line for learning language- and action-conditioned video prediction, robotic video-conditioned language modeling, or a bunch of different attention-grabbing lively questions within the broader ML context. See our paper and GitHub web page to be taught extra.
Acknowledgements
We wish to thank everybody who supported this analysis. This consists of robotic teleoperators: Alex Luong, Armando Reyes, Elio Prado, Eric Tran, Gavin Gonzalez, Jodexty Therlonge, Joel Magpantay, Rochelle Dela Cruz, Samuel Wan, Sarah Nguyen, Scott Lehrer, Norine Rosales, Tran Pham, Kyle Gajadhar, Reece Mungal, and Nikauleene Andrews; robotic {hardware} help and teleoperation coordination: Sean Snyder, Spencer Goodrich, Cameron Burns, Jorge Aldaco, Jonathan Vela; knowledge operations and infrastructure: Muqthar Mohammad, Mitta Kumar, Arnab Bose, Wayne Gramlich; and the various who helped present language labeling of the datasets. We’d additionally prefer to thank Pierre Sermanet, Debidatta Dwibedi, Michael Ryoo, Brian Ichter and Vincent Vanhoucke for his or her invaluable recommendation and help.

{kind=link}