
Rockset is a real-time indexing database within the cloud for serving low-latency, high-concurrency queries at scale. It’s notably well-suited for serving the real-time analytical queries that energy apps, similar to personalization or suggestion engines, location search, and so forth.
On this weblog publish, we present how Rockset’s Sensible Schema characteristic lets builders use real-time SQL queries to extract significant insights from uncooked semi-structured information ingested with no predefined schema.

Challenges with Semi-Structured Knowledge
Interrogating underlying information to border questions on it’s moderately difficult in the event you do not perceive the form of the info.
That is notably true given the character of real-world information. Builders usually discover themselves working with information units which might be messy, with no mounted schema. For instance, they’ll usually embrace closely nested JSON information with a number of deeply nested arrays and objects, with combined information varieties and sparse fields.
As well as, chances are you’ll have to constantly sync new information or pull information from totally different information sources over time. Because of this, the form of the underlying information will change constantly.
Issues with Present Knowledge Programs
Many of the present information programs fail to deal with these ache factors with out introducing extra preprocessing steps which might be, in themselves, painful.
In SQL-based programs, the info is strongly and statically typed. All of the values in the identical column should be of the identical kind, and, basically, the info should comply with a set schema that can’t be simply modified. Ingesting semi-structured information into SQL information programs shouldn’t be a simple process, particularly early on when the info mannequin remains to be evolving. Because of this, organizations often should construct hard-to-maintain ETL pipelines to feed semi-structured information into their SQL programs.
In NoSQL programs, information is strongly typed however dynamically so. The identical subject can maintain values of various varieties throughout paperwork. NoSQL programs are designed to simplify information writes, requiring no schema and little or no upfront information transformation.
Nonetheless, whereas schemaless or schema-unaware NoSQL programs make it easy to ingest semi-structured information into the system with out ETL pipelines, with no identified information mannequin, studying information out in a significant manner is extra sophisticated. They’re additionally not as highly effective at analytical queries as SQL programs on account of their lack of ability to carry out advanced joins and aggregations. Thus, with its inflexible information typing and schemas, SQL continues to be a robust and common question language for real-time analytical queries.
Rockset Offers Knowledge and Question Flexibility
At Rockset, we have now constructed an SQL database that’s dynamically typed however schema-aware. On this manner, our prospects profit from the perfect of each data-system approaches: the flexibleness of NoSQL with out sacrificing any of the analytical powers of SQL.
To permit advanced information to be written as simply as attainable, Rockset helps schemaless ingestion of your uncooked semi-structured information. The schema doesn’t have to be identified or outlined forward of time, and no clunky ETL pipelines are required. Rockset then lets you question this uncooked information utilizing SQL—together with advanced analytical queries—by supporting quick joins and aggregations out of the field.
In different phrases, Rockset doesn’t require a schema however is nonetheless schema-aware, coupling the flexibleness of schemaless ingest at write time with the flexibility to deduce the schema at learn time.
Sensible Schema: Idea and Structure
Rockset routinely and constantly infers the schema primarily based on the precise fields and kinds current within the ingested information. Notice that Rockset generates the schema primarily based on the complete information set, not only a pattern of the info. Sensible Schema evolves to suit new fields and kinds as new semi-structured information is schemalessly ingested.

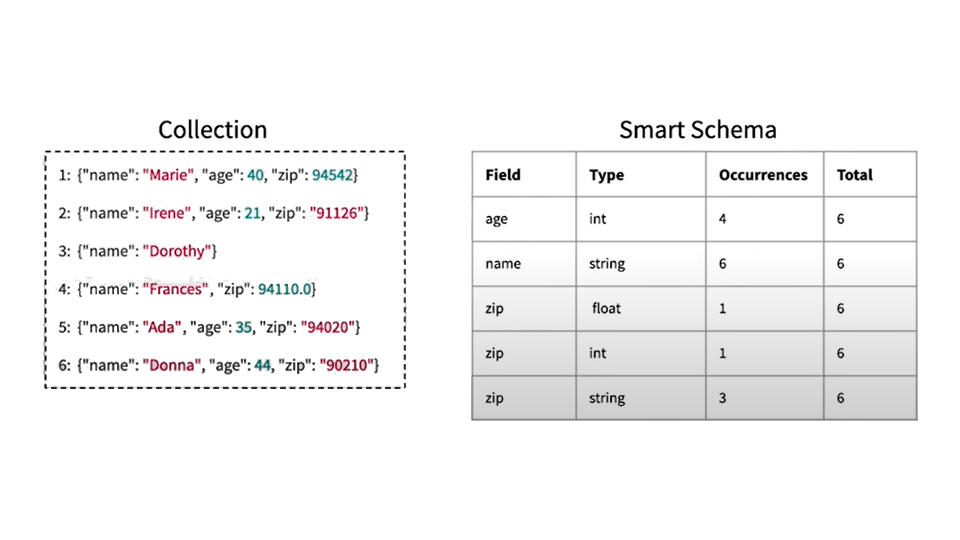
Determine 1: Instance of Sensible Schema generated for a group
Determine 1 reveals on the left a group of paperwork which have the fields “identify,” “age,” and “zip.” On this assortment, there are each lacking fields and fields with combined varieties. On the suitable, you see the Sensible Schema that will be constructed and maintained for this assortment. For every subject, you could have all of its corresponding varieties, the occurrences of every subject kind, and the full variety of paperwork within the assortment. This helps us perceive precisely what fields are current within the information set, what varieties they’re, and the way dense or sparse they could be.
For instance, “zip” has a combined information kind: It’s a string in three out of the six paperwork within the assortment, a float in a single, and an integer in a single. Additionally it is lacking in one of many paperwork. Equally “age” happens 4 instances as an integer and is lacking in two of the paperwork.
So even with out upfront information of this assortment’s schema, Sensible Schema supplies an excellent abstract of how the info is formed and what you possibly can count on from the gathering.
Sensible Schema in Motion: Film Suggestions
This demo reveals how the info from two ingested JSON information units (commons.movie_ratings and commons.films) might be navigated and used to assemble SQL queries for a film suggestion engine.
Understanding Form of the Knowledge
Step one is to make use of the Sensible Schemas to know the form of the info units, which had been ingested as semi-structured information, with out specifying a schema.

Determine 2: Sensible Schema for an ingested assortment
The routinely generated schema will seem on the left. Determine 2 offers a partial view of the checklist of fields that belong to the movie_ratings assortment, and while you hover over a subject, you see the distribution of its underlying subject varieties and the sphere’s total incidence inside the assortment.
The movieId subject, for instance, is at all times a string, and it happens in 100% of the paperwork within the assortment. The score subject, however, is of combined varieties: 78% int and 22% float:

If you happen to run the next question:
DESCRIBE movie-ratings;
you will notice the schema for the movie_ratings assortment as a desk within the Outcomes panel as proven in Determine 3.

Determine 3: Sensible Schema desk for movie_ratings
Equally, within the films assortment, we have now a listing of fields, similar to genres, which is an array kind with nested objects, every of which has id, which is of kind int, and identify, which is of kind string.

So, you possibly can consider the films and the movie_ratings collections as dimension and reality collections, and now that we perceive tips on how to discover the form of the info at a excessive stage, let’s begin developing SQL queries.
Setting up SQL Queries
Let’s begin by getting a listing from the movie_ratings assortment of the movieId of the highest 5 films in descending order of their common score. To do that, we use the SQL Editor within the Rockset Console to jot down a easy aggregation question as follows:

If you wish to guarantee that the common score relies on an inexpensive variety of reviewers, you possibly can add a further predicate utilizing the HAVING clause, the place the score rely should be equal to or higher than 5.

Whenever you run the question, right here is the end result:

If you wish to checklist the highest 5 films by identify as a substitute of ID, you merely be a part of the movie_ratings assortment with the films assortment and extract the sphere title from the output of that be a part of. To do that, we copy the earlier question and alter it with an INNER JOIN on the gathering films (alias mv)and replace the qualifying fields (circled beneath) accordingly:

Now while you run the question, you get a listing of film titles as a substitute of IDs:

And eventually, as an example you additionally need to checklist the names of the genres that these films belong to. The sector genres is an array of nested objects. With a purpose to extract the sphere genres.identify, you must flatten the array, i.e., unnest it. Copying (and formatting) the identical question, you utilize UNNEST to flatten the genres array from the films assortment (mv.genres), giving it an alias g after which extracting the style identify (g.identify) within the GROUP BY clause:

And if you wish to checklist the highest 5 films in a selected style, you do it just by including a WHERE clause below g.identify (within the instance proven beneath, Thriller):

Now you’ll get the highest 5 films within the style Thriller, as proven beneath:

And That’s Not All…
If you’d like your software to provide film suggestions primarily based on user-specified genres, rankings, and different such fields, this may be achieved by Rockset’s Question Lambdas characteristic, which helps you to parameterize queries that may then be invoked by your software from a devoted REST endpoint.
Try our video the place we speak about all Sensible Schema, and tell us what you assume.
Embedded content material: https://www.youtube.com/watch?v=2fjO2qSRduc

{kind=link}