

Right now, we’re excited to announce the final availability of the Databricks SQL Assertion Execution API on AWS and Azure, with help for GCP anticipated to be in Public Preview early subsequent yr. You should utilize the API to hook up with your Databricks SQL warehouse over a REST API to entry and manipulate knowledge managed by the Databricks Lakehouse Platform.
On this weblog, we stroll by means of the API fundamentals, focus on the important thing options newly accessible within the GA launch, and present you easy methods to construct an information utility utilizing the Assertion Execution API with the Databricks Python SDK. You’ll be able to even comply with alongside by working the code in opposition to your Databricks workspace. For a further instance, our earlier weblog confirmed easy methods to leverage your knowledge in a spreadsheet utilizing the Assertion Execution API and JavaScript.
Assertion Execution API, in short
BI purposes are one of many main shoppers of an information warehouse and Databricks SQL supplies a wealthy connectivity ecosystem of drivers, connectors, and native integrations with established BI instruments. Nonetheless, knowledge managed by the Databricks Lakehouse Platform is related for purposes and use circumstances past BI, reminiscent of e-commerce platforms, CRM programs, SaaS purposes, or customized knowledge purposes developed by prospects in-house. Usually, these instruments can not simply join over commonplace database interfaces and drivers; nonetheless, nearly any device and system can talk with a REST API.
The Databricks SQL Assertion Execution API permits you to use commonplace SQL over HTTP to construct integrations with a variety of purposes, applied sciences, and computing units. The API supplies a set of endpoints that let you submit SQL statements to a SQL Warehouse for execution and retrieve outcomes. The picture beneath supplies a high-level overview of a typical knowledge circulation.
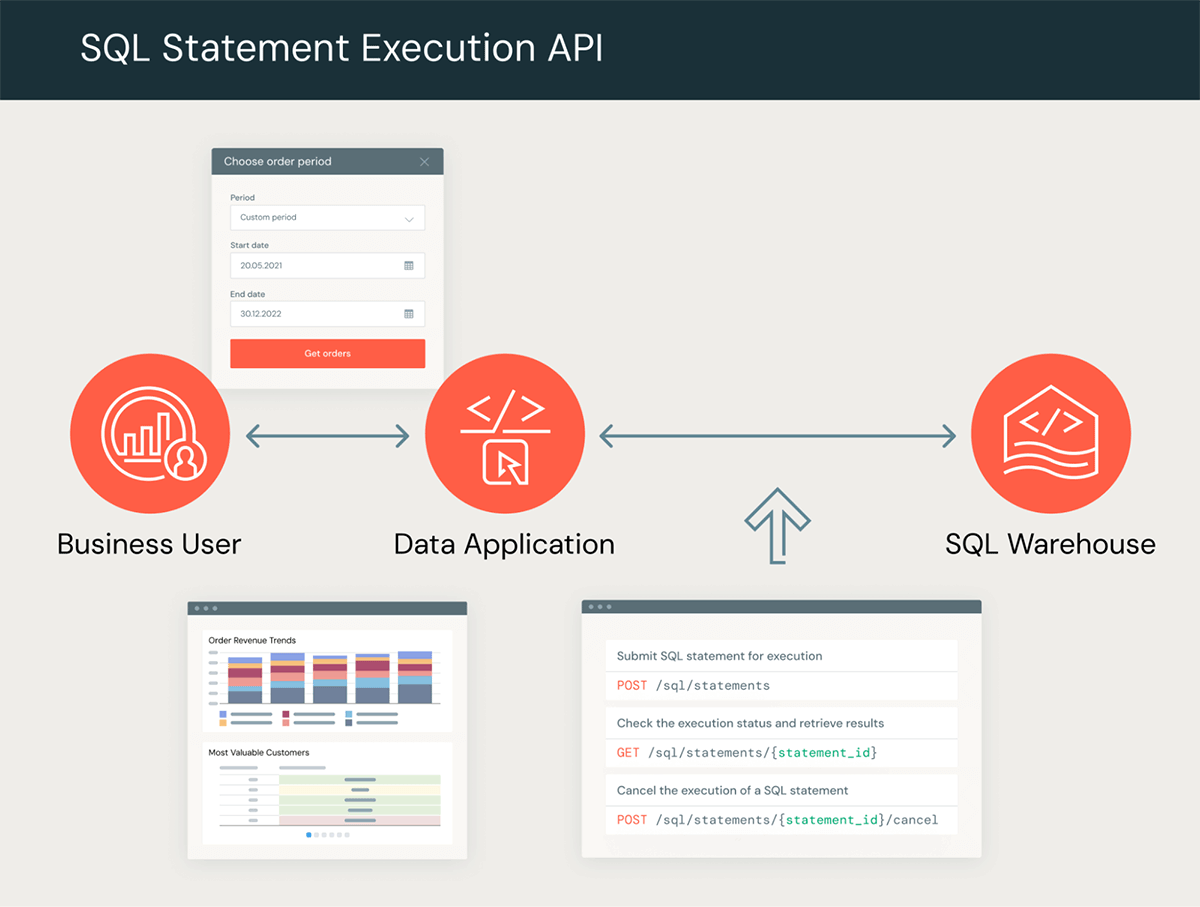
You should utilize the API to construct customized knowledge apps with instruments and languages of your selection. For instance, you may construct internet purposes the place a enterprise person supplies a set of querying standards by means of a person interface and is offered again the outcomes for visualization, obtain, or additional evaluation. You may also use the API to implement special-purpose APIs tailored to your specific use circumstances and microservices, or construct customized connectors in your programming language of selection. One important benefit when utilizing the API for these eventualities is that you don’t want to put in a driver or handle database connections; you merely connect with the server over HTTP and handle asynchronous knowledge exchanges.
New options accessible within the GA launch
Together with the final availability of the API on AWS and Azure, we’re enabling some new options and enhancements.
- Parameterized statements – Safely apply dynamic literal values to your SQL queries with type-safe parameters. Literal values are dealt with individually out of your SQL code, which permits Databricks SQL to interpret the logic of the code independently from user-supplied variables, stopping widespread SQL injection assaults.
- End result retention – Refetch the outcomes for an announcement a number of instances for as much as one hour. Beforehand, outcomes have been not accessible after the final chunk was learn, requiring particular remedy of the final chunk when fetching chunks in parallel.
- A number of outcome codecs – JSON_ARRAY and CSV codecs are actually accessible with the EXTERNAL_LINKS disposition. When you can nonetheless use Arrow for optimum efficiency, JSON and CSV are extra ubiquitously supported by instruments and frameworks, enhancing interoperability.
- Byte and row limits – Apply limits to your outcomes to forestall surprising giant outputs. The API will return a truncation flag at any time when the desired restrict is exceeded.
Within the subsequent part, we’ll go into extra element as we use these new options to construct a customized API on prime of the Assertion Execution API.
Construct your special-purpose API
On the Knowledge+AI Summit this yr, we walked by means of constructing a customized API on prime of the Databricks Lakehouse Platform utilizing this new Assertion Execution API. In case you missed it, we’ll relive that journey now, growing a easy web site and repair backend for a fictional firm referred to as Acme, Inc. You’ll be able to comply with together with the code right here, working the `setup.sh` script as a primary step.
Acme, Inc. is a medium sized enterprise with 100 shops that promote numerous varieties of machine elements. They leverage the Databricks Lakehouse to trace details about every retailer and to course of their gross sales knowledge with a medallion structure. They wish to create an internet utility that enables retailer managers to simply browse their gold gross sales knowledge and retailer data. As well as, they wish to allow retailer managers to insert gross sales that did not undergo a traditional level of sale. To construct this method we’ll create a Python Flask utility that exposes a customized knowledge API and an HTML/JQuery frontend that invokes that API to learn and write knowledge.
Let us take a look at the customized API endpoint to record all shops and the way it maps to the Assertion Execution API within the backend. It’s a easy GET request that takes no arguments. The backend calls into the SQL Warehouse with a static SELECT assertion to learn the `shops` desk.
| Acme Inc’s API Request | Assertion Execution API Request | |
|---|---|---|
| GET /shops | → | POST /sql/statements assertion: “SELECT * FROM shops” wait_timeout: “50s” on_wait_timeout: “CANCEL” |
| Acme Inc’s API Response | Assertion Execution API Response | |
| state: “SUCCEEDED” shops: [ [“123”, “Acme, Inc”, …], [“456”, “Databricks”, …] ] |
← | statement_id: “ID123” standing: { state: “SUCCEEDED” } manifest: { … } outcome: { data_array: [ [“123”, “Acme, Inc”, …], [“456”, “Databricks”, …] ] } |
As Acme solely has 100 shops, we count on a quick question and a small knowledge set within the response. Due to this fact, we have determined to make a synchronous request to Databricks and get rows of retailer knowledge returned inline. To make it synchronous, we set the `wait_timeout` to point we’ll wait as much as 50 seconds for a response and set the `on_wait_timeout` parameter to cancel the question if it takes longer. By trying on the response from Databricks, you may see that the default outcome `disposition` and `format` return the info inline in a JSON array. Acme’s backend service can then repackage that payload to return to the customized API’s caller.
The total backend code for this tradition endpoint may be discovered right here. Within the frontend, we name the customized `/api/1.0/shops` endpoint to get the record of shops and show them by iterating over the JSON array right here. With these two items, Acme has a brand new homepage backed by Databricks SQL!
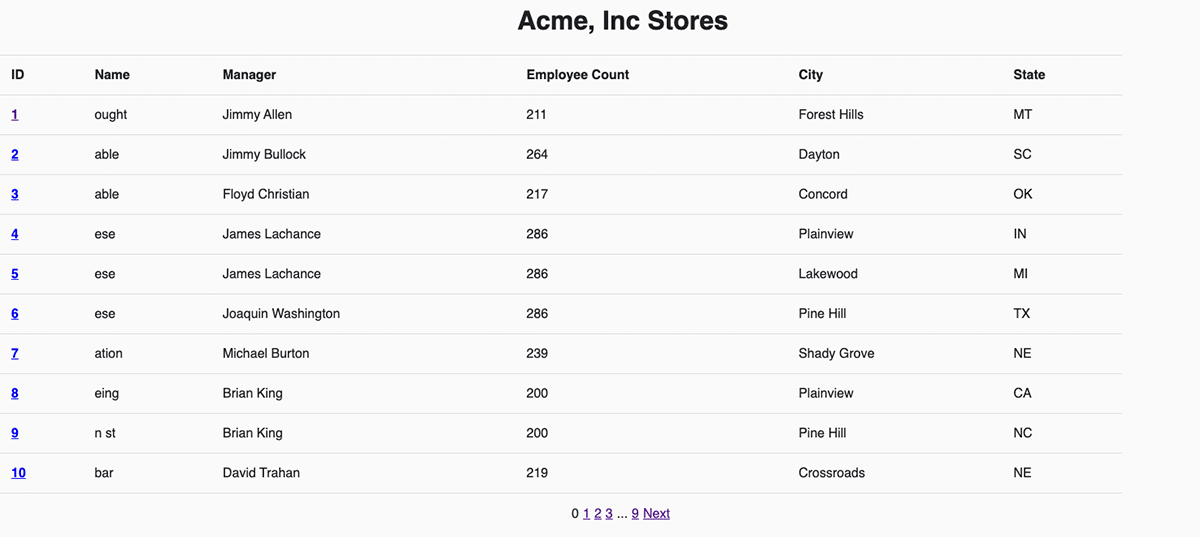
For every retailer, we additionally wish to have a web page that shows the latest gross sales and we would like a retailer supervisor to have the ability to obtain the total set of retailer knowledge. It is value noting that the variety of gross sales transactions per retailer may be fairly giant – many orders of magnitude better than the variety of shops. The necessities for this tradition API endpoint are:
- Restricted output – The caller should be capable of restrict the variety of gross sales returned so they do not need to get all the info on a regular basis.
- Multi-format – The outcomes must be retrievable in a number of codecs in order that they are often simply displayed in an internet web page or downloaded for offline processing in a device like Excel.
- Async – It must be async as it would take a very long time to get the gross sales data for a retailer.
- Environment friendly extracts – For efficiency and stability causes, the massive gross sales knowledge shouldn’t be pulled by means of the backend internet server.
Beneath, you may see how we use the Databricks SDK for Python to invoke the Assertion Execution API to cowl these necessities. The total code is right here.
def execute_list_sales_request(store_id, format, row_limit):
# Use parameters to forestall SQL injection through the shop ID string.
parameters = [
StatementParameterListItem(name='store_id', value=store_id, type="INT")
]
statement_response = w.statement_execution.execute_statement(
assertion = "SELECT * FROM gross sales WHERE store_id = :store_id",
format = Format[format],
disposition = Disposition.EXTERNAL_LINKS,
wait_timeout = "0s",
warehouse_id = warehouse_id,
parameters = parameters,
row_limit = row_limit
)
response = {
'request_id': statement_response.statement_id,
'state': str(statement_response.standing.state.identify)
}
return responseTo fulfill the primary two necessities, we expose `row_limit` and `format` parameters from the customized API and go them to the Assertion Execution API. This may enable callers to restrict the entire variety of rows produced by the question and to select the outcome format (CSV, JSON or Arrow).
To make the customized API asynchronous, we’ll set the Assertion Execution API’s `wait_timeout` parameter to 0 seconds, which implies Databricks will reply instantly with an announcement ID and question state. We’ll bundle that assertion ID as a `request_id` together with the state in a response to the caller. As soon as the shopper will get the request ID and state, they’ll ballot the identical customized API endpoint to examine the standing of the execution. The endpoint forwards the request to Databricks SQL Warehouse through the `get_statement` technique. If the question is profitable, the API will ultimately return a `SUCCEEDED` state together with a `chunk_count`. The chunk depend signifies what number of partitions the outcome was divided into.
To attain environment friendly extracts (4th requirement), we used the EXTERNAL_LINKS disposition. This permits us to get a pre-signed URL for every chunk, which the customized API will return when given a `request_id` and `chunk_index`.
We are able to use this to construct Acme a touchdown web page for every retailer that reveals the latest gross sales by supplying a row restrict of 20 and the JavaScript pleasant JSON_ARRAY outcome format. However we will additionally add a “Obtain” button on the prime of the web page to permit retailer managers to tug historic knowledge for all gross sales. In that case, we do not provide a restrict and leverage the CSV format for simple ingestion into the evaluation device of their selection. As soon as the browser sees the question is profitable and will get the entire chunk depend, it invokes the customized API in parallel to get pre-signed URLs and obtain the CSV knowledge instantly from cloud storage. Beneath the hood, the EXTERNAL_LINKS disposition leverages the Cloud Fetch expertise that has proven a 12x enchancment in extraction throughput over sequential inline reads. Within the instance beneath, we downloaded 500MBs in parallel at ~160Mbps.
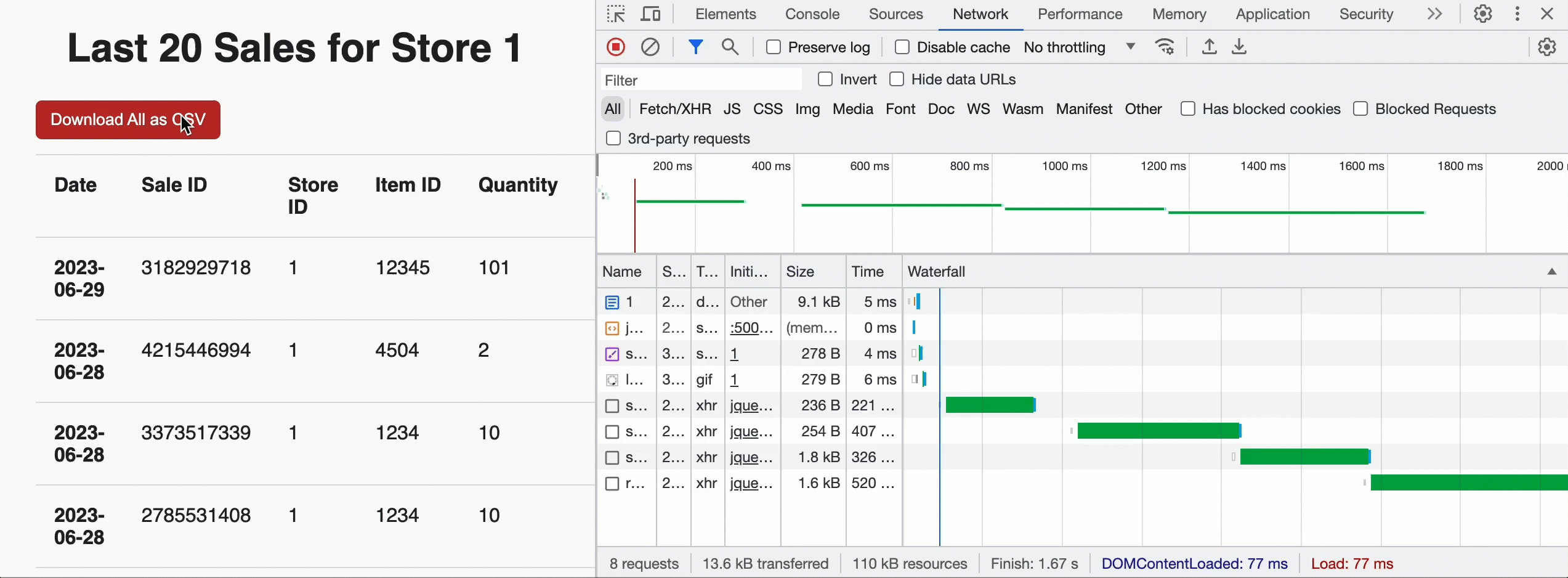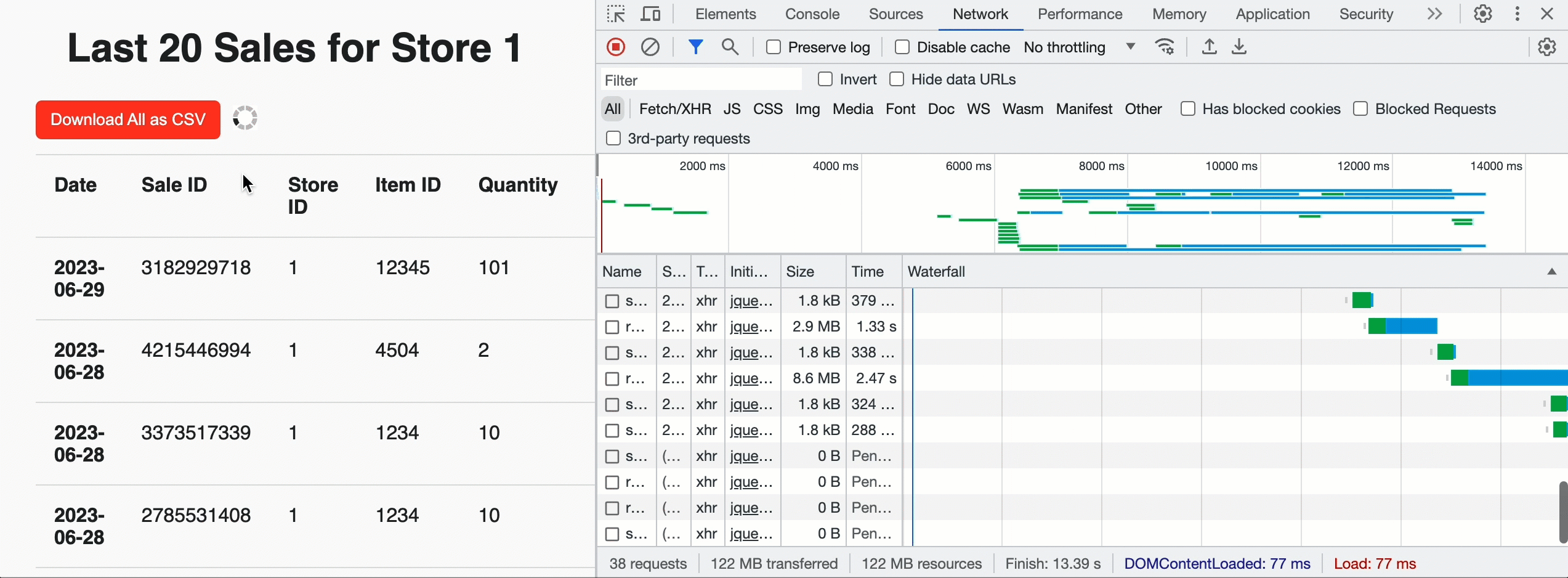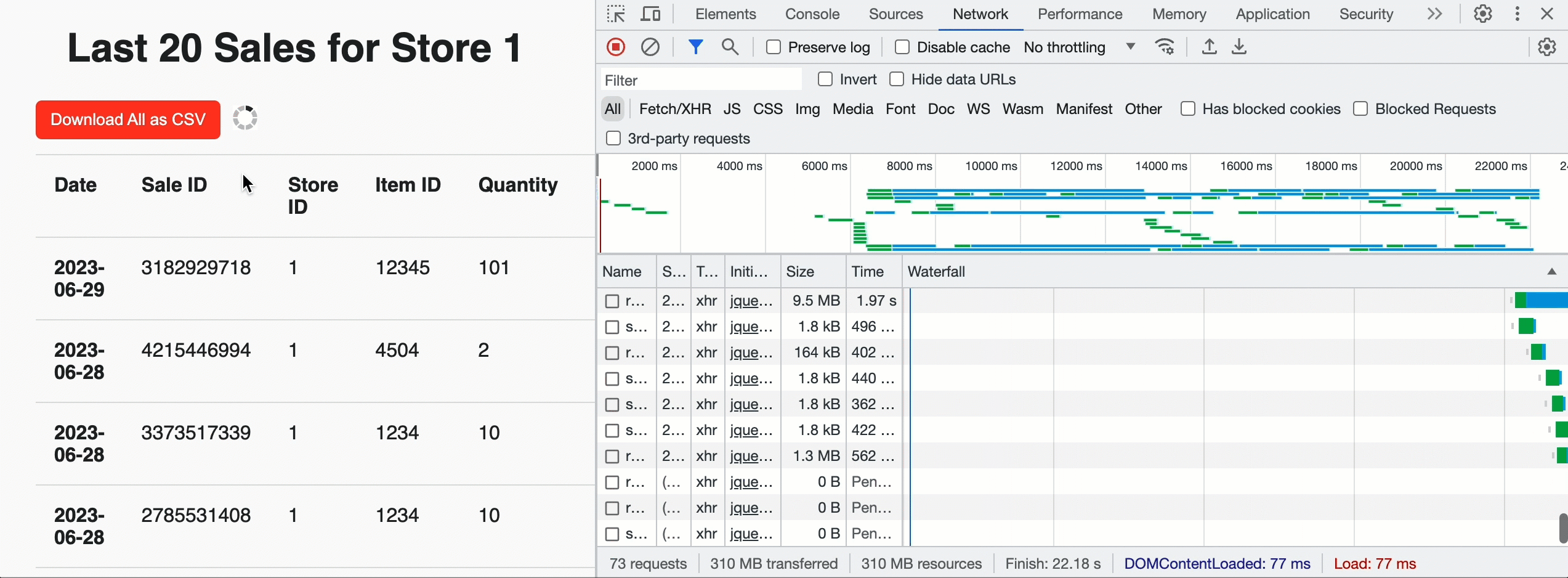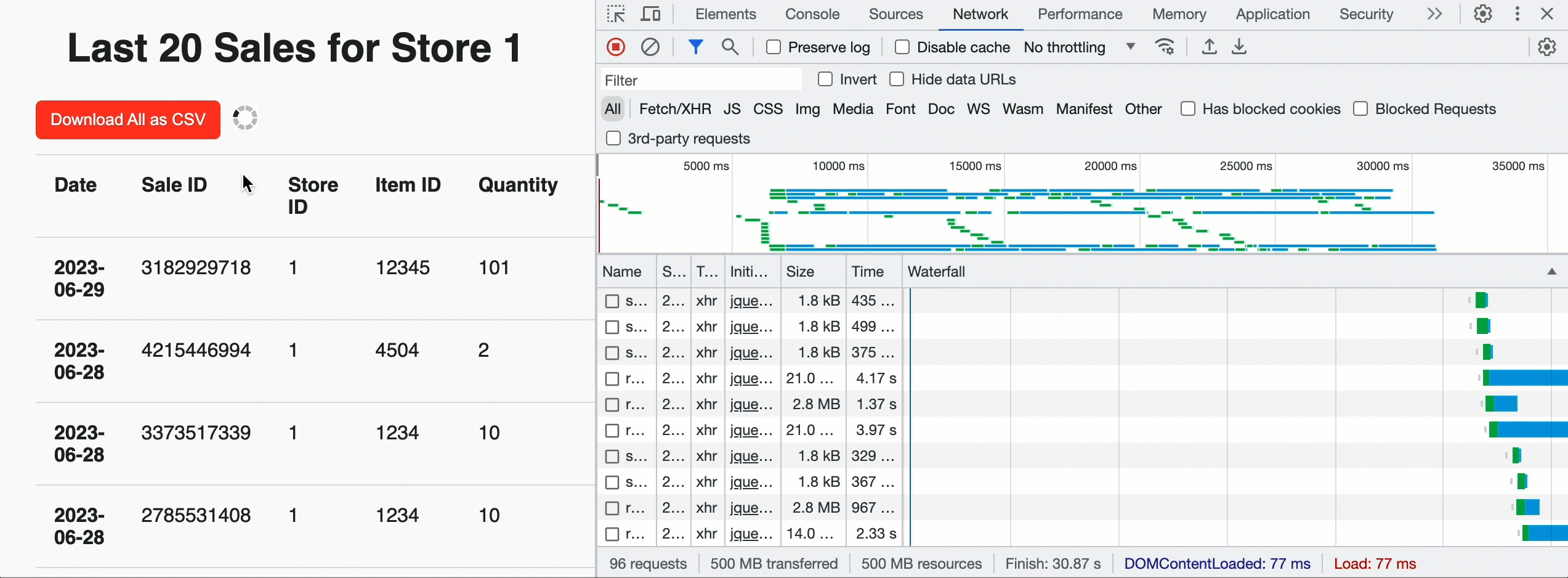
Now that gross sales for a retailer may be seen, the Acme workforce additionally wants to have the ability to insert new gross sales data into the Lakehouse. For that, we will create a easy internet type backed by a POST request to the /api/1.0/shops/storeId/gross sales endpoint. To get the shape knowledge into the Lakehouse, we’ll use a parameterised SQL assertion:
INSERT INTO
gross sales (
ss_sold_date_sk,
ss_ticket_number,
ss_store_sk,
ss_item_sk,
ss_sales_price,
ss_quantity
)
VALUES
(
:sold_date,
:sale_id,
:store_id,
:item_id,
:sales_price,
:amount
)And provide the enter from the online type to the Assertion Execution API utilizing the `parameters` record argument with a reputation, worth, and sort for every parameter:
{
"parameters": [
{ "name": "sold_date", "type": "DATE", "value": "2023-09-06" },
{ "name": "sale_id", "type": "BIGINT", "value": "10293847" },
{ "name": "store_id", "type": "INT", "value": "12345" },
{ "name": "item_id", "type": "INT", "value": "67890" },
{ "name": "sales_price", "type": "DECIMAL(7,2)", "value": "1.99" }
{ "name": "quantity", "type": "INT", "value": "100" },
]
}The SQL Warehouse engine will safely substitute the offered parameters into the question plan as literals after parsing the SQL code. This prevents maliciously injected SQL syntax from being interpreted as SQL. The “sort” subject for every parameter supplies a further layer of security by checking the type-correctness of the offered “worth“. If a malicious person supplies a price like “100); drop desk gross sales” as enter for the amount subject, the INSERT INTO assertion will outcome within the following error and won’t be executed:
[INVALID_PARAMETER_MARKER_VALUE.INVALID_VALUE_FOR_DATA_TYPE] An invalid parameter mapping was offered: the worth ‘100); drop desk gross sales’ for parameter ‘amount’ can’t be solid to INT as a result of it’s malformed.
You’ll be able to see how we put parameters to make use of as a part of the `POST /api/1.0/shops/store_id/gross sales` endpoint right here. If the enter to the online type is legitimate with the proper sorts, then the gross sales desk might be efficiently up to date after the person clicks “Submit”.
Now you can iterate on prime of this tradition API or use it as a stepping stone to constructing your individual customized knowledge utility on prime of the Databricks Lakehouse Platform. Along with utilizing the pattern code we have been utilizing all through this text and the `setup.sh` script that creates pattern tables in your individual Databricks surroundings, chances are you’ll wish to watch the stay clarification on the Knowledge+AI Summit – the video beneath.
Getting began with the Databricks SQL Assertion Execution API
The Databricks SQL Assertion Execution API is out there with the Databricks Premium and Enterprise tiers. If you have already got a Databricks account, comply with our tutorial (AWS | Azure), the documentation (AWS | Azure), or examine our repository of code samples. If you’re not an current Databricks buyer, join a free trial.

{kind=link}