

Main current advances in a number of subfields of machine studying (ML) analysis, equivalent to pc imaginative and prescient and pure language processing, have been enabled by a shared widespread method that leverages massive, various datasets and expressive fashions that may soak up the entire knowledge successfully. Though there have been varied makes an attempt to use this method to robotics, robots haven’t but leveraged highly-capable fashions in addition to different subfields.
A number of elements contribute to this problem. First, there’s the shortage of large-scale and various robotic knowledge, which limits a mannequin’s capability to soak up a broad set of robotic experiences. Information assortment is especially costly and difficult for robotics as a result of dataset curation requires engineering-heavy autonomous operation, or demonstrations collected utilizing human teleoperations. A second issue is the shortage of expressive, scalable, and fast-enough-for-real-time-inference fashions that may study from such datasets and generalize successfully.
To handle these challenges, we suggest the Robotics Transformer 1 (RT-1), a multi-task mannequin that tokenizes robotic inputs and outputs actions (e.g., digital camera photographs, job directions, and motor instructions) to allow environment friendly inference at runtime, which makes real-time management possible. This mannequin is skilled on a large-scale, real-world robotics dataset of 130k episodes that cowl 700+ duties, collected utilizing a fleet of 13 robots from On a regular basis Robots (EDR) over 17 months. We display that RT-1 can exhibit considerably improved zero-shot generalization to new duties, environments and objects in comparison with prior methods. Furthermore, we rigorously consider and ablate most of the design selections within the mannequin and coaching set, analyzing the results of tokenization, motion illustration, and dataset composition. Lastly, we’re open-sourcing the RT-1 code, and hope it would present a precious useful resource for future analysis on scaling up robotic studying.
 |
| RT-1 absorbs massive quantities of information, together with robotic trajectories with a number of duties, objects and environments, leading to higher efficiency and generalization. |
Robotics Transformer (RT-1)
RT-1 is constructed on a transformer structure that takes a brief historical past of photographs from a robotic’s digital camera together with job descriptions expressed in pure language as inputs and immediately outputs tokenized actions.
RT-1’s structure is much like that of a up to date decoder-only sequence mannequin skilled towards a normal categorical cross-entropy goal with causal masking. Its key options embody: picture tokenization, motion tokenization, and token compression, described under.
Picture tokenization: We move photographs by way of an EfficientNet-B3 mannequin that’s pre-trained on ImageNet, after which flatten the ensuing 9×9×512 spatial characteristic map to 81 tokens. The picture tokenizer is conditioned on pure language job directions, and makes use of FiLM layers initialized to identification to extract task-relevant picture options early on.
Motion tokenization: The robotic’s motion dimensions are 7 variables for arm motion (x, y, z, roll, pitch, yaw, gripper opening), 3 variables for base motion (x, y, yaw), and an additional discrete variable to change between three modes: controlling arm, controlling base, or terminating the episode. Every motion dimension is discretized into 256 bins.
Token Compression: The mannequin adaptively selects mushy mixtures of picture tokens that may be compressed based mostly on their influence in direction of studying with the element-wise consideration module TokenLearner, leading to over 2.4x inference speed-up.
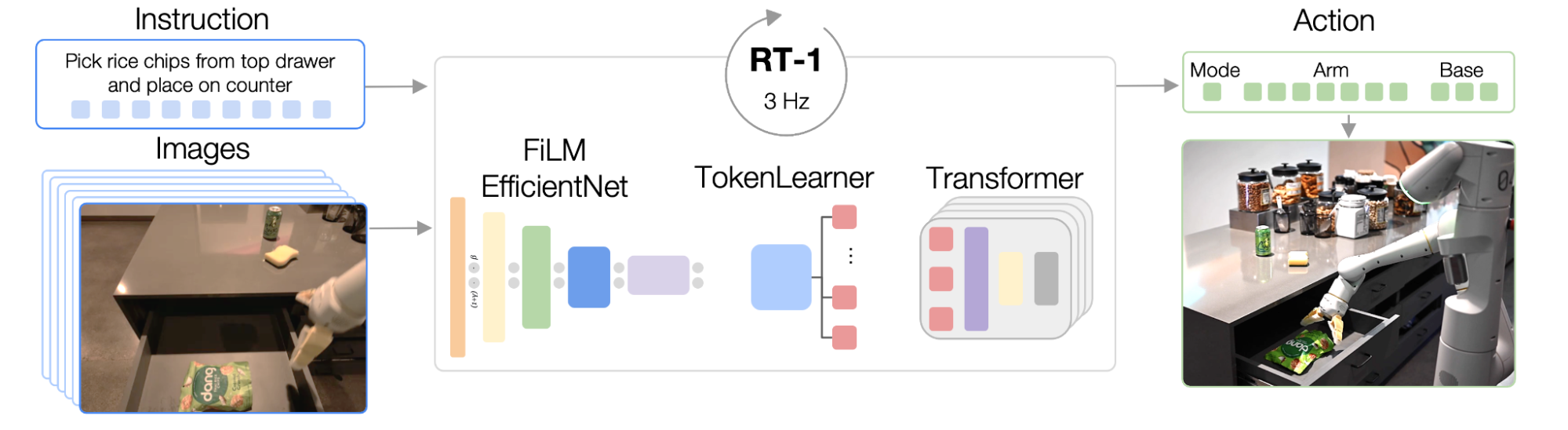 |
| RT-1’s structure: The mannequin takes a textual content instruction and set of photographs as inputs, encodes them as tokens by way of a pre-trained FiLM EfficientNet mannequin and compresses them by way of TokenLearner. These are then fed into the Transformer, which outputs motion tokens. |
To construct a system that would generalize to new duties and present robustness to completely different distractors and backgrounds, we collected a big, various dataset of robotic trajectories. We used 13 EDR robotic manipulators, every with a 7-degree-of-freedom arm, a 2-fingered gripper, and a cell base, to gather 130k episodes over 17 months. We used demonstrations offered by people by way of distant teleoperation, and annotated every episode with a textual description of the instruction that the robotic simply carried out. The set of high-level abilities represented within the dataset consists of selecting and putting objects, opening and shutting drawers, getting objects out and in drawers, putting elongated objects up-right, knocking objects over, pulling napkins and opening jars. The ensuing dataset consists of 130k+ episodes that cowl 700+ duties utilizing many alternative objects.
Experiments and Outcomes
To raised perceive RT-1’s generalization talents, we research its efficiency towards three baselines: Gato, BC-Z and BC-Z XL (i.e., BC-Z with identical variety of parameters as RT-1), throughout 4 classes:
- Seen duties efficiency: efficiency on duties seen throughout coaching
- Unseen duties efficiency: efficiency on unseen duties the place the talent and object(s) have been seen individually within the coaching set, however mixed in novel methods
- Robustness (distractors and backgrounds): efficiency with distractors (as much as 9 distractors and occlusion) and efficiency with background modifications (new kitchen, lighting, background scenes)
- Lengthy-horizon situations: execution of SayCan-type pure language directions in an actual kitchen
RT-1 outperforms baselines by massive margins in all 4 classes, exhibiting spectacular levels of generalization and robustness.
 |
| Efficiency of RT-1 vs. baselines on analysis situations. |
Incorporating Heterogeneous Information Sources
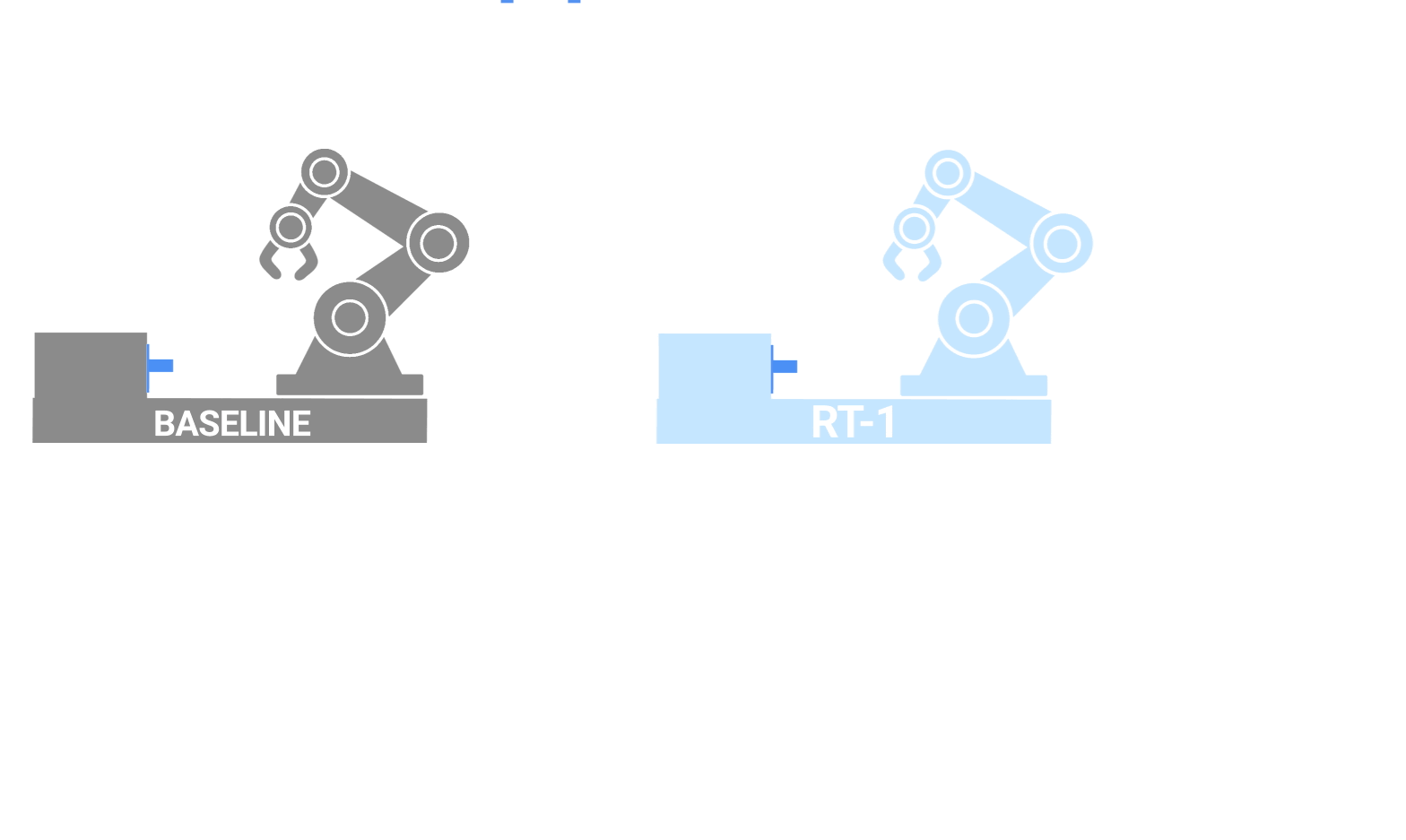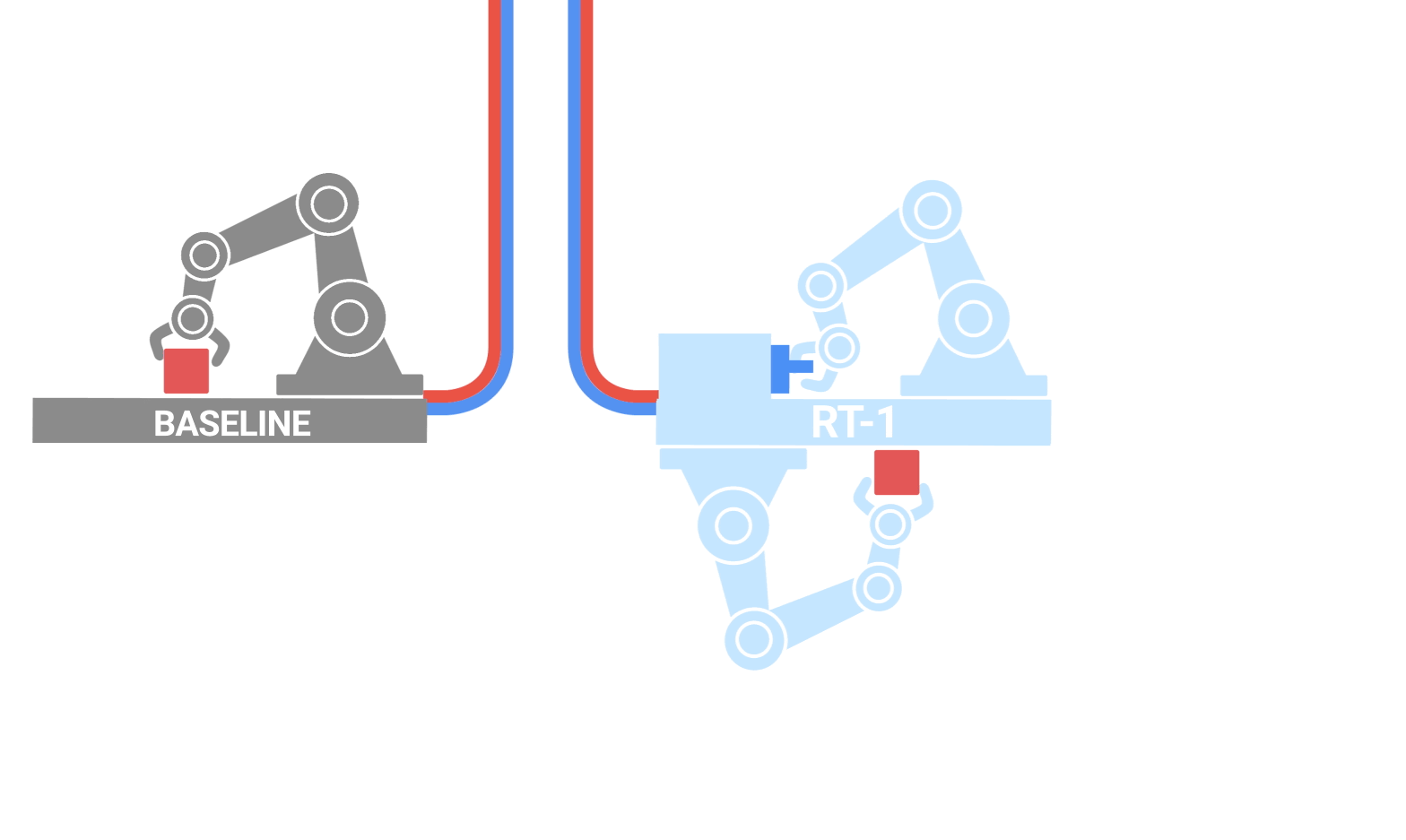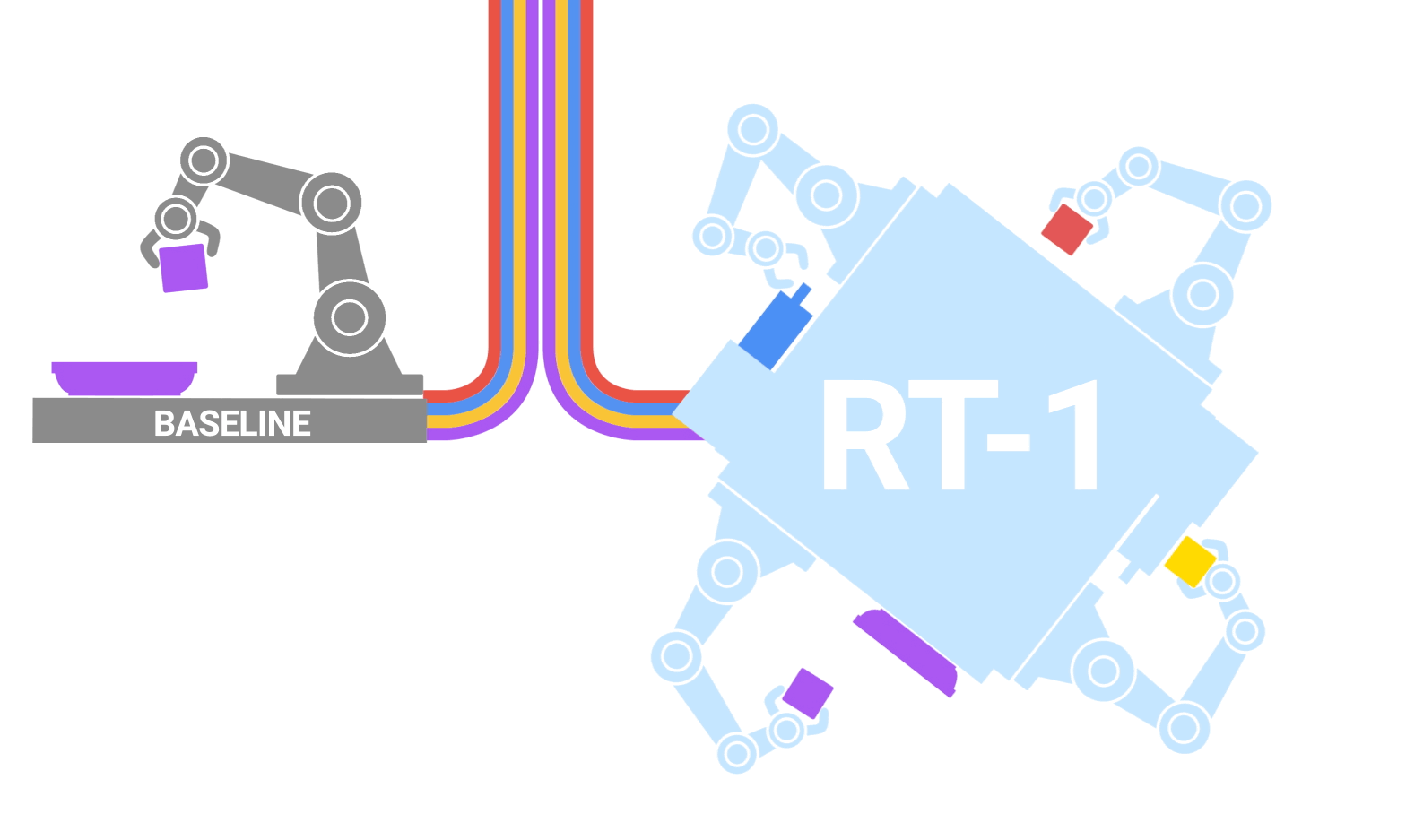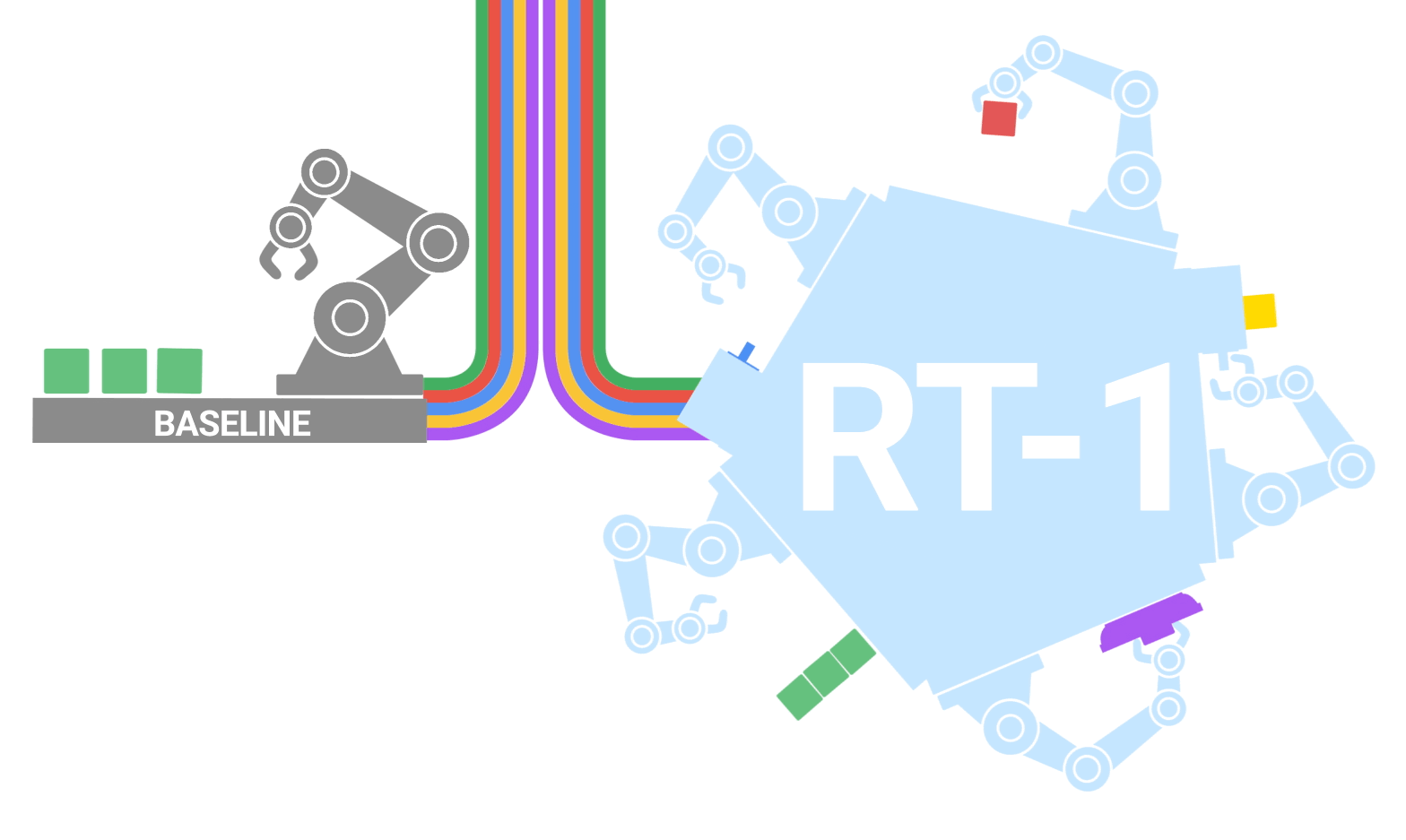
To push RT-1 additional, we practice it on knowledge gathered from one other robotic to check if (1) the mannequin retains its efficiency on the unique duties when a brand new knowledge supply is offered and (2) if the mannequin sees a lift in generalization with new and completely different knowledge, each of that are fascinating for a normal robotic studying mannequin. Particularly, we use 209k episodes of indiscriminate greedy that have been autonomously collected on a fixed-base Kuka arm for the QT-Choose mission. We remodel the info collected to match the motion specs and bounds of our authentic dataset collected with EDR, and label each episode with the duty instruction “decide something” (the Kuka dataset doesn’t have object labels). Kuka knowledge is then blended with EDR knowledge in a 1:2 ratio in each coaching batch to regulate for regression in authentic EDR abilities.
 |
| Coaching methodology when knowledge has been collected from a number of robots. |
Our outcomes point out that RT-1 is ready to purchase new abilities by observing different robots’ experiences. Particularly, the 22% accuracy seen when coaching with EDR knowledge alone jumps by virtually 2x to 39% when RT-1 is skilled on each bin-picking knowledge from Kuka and present EDR knowledge from robotic lecture rooms, the place we collected most of RT-1 knowledge. When coaching RT-1 on bin-picking knowledge from Kuka alone, after which evaluating it on bin-picking from the EDR robotic, we see 0% accuracy. Mixing knowledge from each robots, alternatively, permits RT-1 to deduce the actions of the EDR robotic when confronted with the states noticed by Kuka, with out specific demonstrations of bin-picking on the EDR robotic, and by benefiting from experiences collected by Kuka. This presents a possibility for future work to mix extra multi-robot datasets to boost robotic capabilities.
| Coaching Information | Classroom Eval | Bin-picking Eval |
| Kuka bin-picking knowledge + EDR knowledge | 90% | 39% |
| EDR solely knowledge | 92% | 22% |
| Kuka bin-picking solely knowledge | 0 | 0 |
| RT-1 accuracy analysis utilizing varied coaching knowledge. |
Lengthy-Horizon SayCan Duties
RT-1’s excessive efficiency and generalization talents can allow long-horizon, cell manipulation duties by way of SayCan. SayCan works by grounding language fashions in robotic affordances, and leveraging few-shot prompting to interrupt down a long-horizon job expressed in pure language right into a sequence of low-level abilities.
SayCan duties current a perfect analysis setting to check varied options:
- Lengthy-horizon job success falls exponentially with job size, so excessive manipulation success is essential.
- Cell manipulation duties require a number of handoffs between navigation and manipulation, so the robustness to variations in preliminary coverage circumstances (e.g., base place) is important.
- The variety of potential high-level directions will increase combinatorially with skill-breadth of the manipulation primitive.
We consider SayCan with RT-1 and two different baselines (SayCan with Gato and SayCan with BC-Z) in two actual kitchens. Under, “Kitchen2” constitutes a way more difficult generalization scene than “Kitchen1”. The mock kitchen used to collect many of the coaching knowledge was modeled after Kitchen1.
SayCan with RT-1 achieves a 67% execution success fee in Kitchen1, outperforming different baselines. As a result of generalization issue offered by the brand new unseen kitchen, the efficiency of SayCan with Gato and SayCan with BCZ shapely falls, whereas RT-1 doesn’t present a visual drop.
| SayCan duties in Kitchen1 | SayCan duties in Kitchen2 | |||
| Planning | Execution | Planning | Execution | |
| Unique Saycan | 73 | 47 | – | – |
| SayCan w/ Gato | 87 | 33 | 87 | 0 |
| SayCan w/ BC-Z | 87 | 53 | 87 | 13 |
| SayCan w/ RT-1 | 87 | 67 | 87 | 67 |
The next video reveals a number of instance PaLM-SayCan-RT1 executions of long-horizon duties in a number of actual kitchens.
Conclusion
The RT-1 Robotics Transformer is a straightforward and scalable action-generation mannequin for real-world robotics duties. It tokenizes all inputs and outputs, and makes use of a pre-trained EfficientNet mannequin with early language fusion, and a token learner for compression. RT-1 reveals robust efficiency throughout a whole lot of duties, and in depth generalization talents and robustness in real-world settings.
As we discover future instructions for this work, we hope to scale the variety of robotic abilities sooner by growing strategies that permit non-experts to coach the robotic with directed knowledge assortment and mannequin prompting. We additionally look ahead to bettering robotics transformers’ response speeds and context retention with scalable consideration and reminiscence. To study extra, try the paper, open-sourced RT-1 code, and the mission web site.
Acknowledgements
This work was completed in collaboration with Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, Deeksha Manjunath, Igor Mordatch, Ofir Nachum, Carolina Parada, Jodilyn Peralta, Emily Perez, Karl Pertsch, Jornell Quiambao, Kanishka Rao, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Kevin Sayed, Jaspiar Singh, Sumedh Sontakke, Austin Stone, Clayton Tan, Huong Tran, Vincent Vanhoucke, Steve Vega, Quan Vuong, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, and Brianna Zitkovich.

{kind=link}