
In lots of organizations, as soon as the work has been achieved to combine a
new system into the mainframe, say, it turns into a lot
simpler to work together with that system through the mainframe moderately than
repeat the combination every time. For a lot of legacy techniques with a
monolithic structure this made sense, integrating the
similar system into the identical monolith a number of occasions would have been
wasteful and certain complicated. Over time different techniques start to achieve
into the legacy system to fetch this knowledge, with the originating
built-in system usually “forgotten”.
Normally this results in a legacy system changing into the only level
of integration for a number of techniques, and therefore additionally changing into a key
upstream knowledge supply for any enterprise processes needing that knowledge.
Repeat this method just a few occasions and add within the tight coupling to
legacy knowledge representations we frequently see,
for instance as in Invasive Essential Aggregator, then this could create
a major problem for legacy displacement.
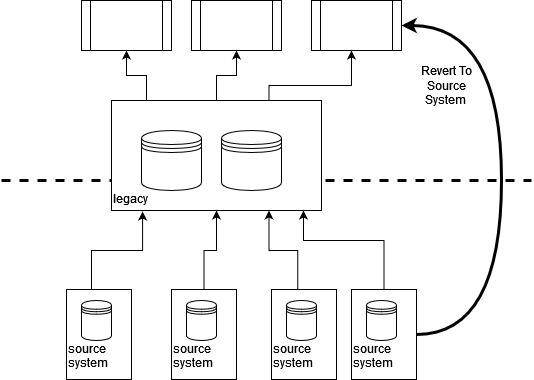
By tracing sources of information and integration factors again “past” the
legacy property we will usually “revert to supply” for our legacy displacement
efforts. This could permit us to cut back dependencies on legacy
early on in addition to offering a possibility to enhance the standard and
timeliness of information as we will convey extra fashionable integration strategies
into play.
It’s also price noting that it’s more and more very important to grasp the true sources
of information for enterprise and authorized causes similar to GDPR. For a lot of organizations with
an intensive legacy property it’s only when a failure or situation arises that
the true supply of information turns into clearer.
How It Works
As a part of any legacy displacement effort we have to hint the originating
sources and sinks for key knowledge flows. Relying on how we select to slice
up the general drawback we might not want to do that for all techniques and
knowledge directly; though for getting a way of the general scale of the work
to be achieved it is rather helpful to grasp the principle
flows.
Our intention is to provide some sort of information movement map. The precise format used
is much less vital,
moderately the important thing being that this discovery does not simply
cease on the legacy techniques however digs deeper to see the underlying integration factors.
We see many
structure diagrams whereas working with our purchasers and it’s stunning
how usually they appear to disregard what lies behind the legacy.
There are a number of strategies for tracing knowledge via techniques. Broadly
we will see these as tracing the trail upstream or downstream. Whereas there’s
usually knowledge flowing each to and from the underlying supply techniques we
discover organizations are inclined to assume in phrases solely of information sources. Maybe
when considered via the lenses of the legacy techniques this
is probably the most seen a part of any integration? It’s not unusual to
discover the movement of information from legacy again into supply techniques is the
most poorly understood and least documented a part of any integration.
For upstream we frequently begin with the enterprise processes after which try
to hint the movement of information into, after which again via, legacy.
This may be difficult, particularly in older techniques, with many alternative
mixtures of integration applied sciences. One helpful approach is to make use of
is CRC playing cards with the objective of making
a dataflow diagram alongside sequence diagrams for key enterprise
course of steps. Whichever approach we use it is important to get the appropriate
folks concerned, ideally those that initially labored on the legacy techniques
however extra generally those that now help them. If these folks aren’t
out there and the information of how issues work has been misplaced then beginning
at supply and dealing downstream may be extra appropriate.
Tracing integration downstream may also be extraordinarily helpful and in our
expertise is usually uncared for, partly as a result of if
Function Parity is in play the main focus tends to be solely
on current enterprise processes. When tracing downstream we start with an
underlying integration level after which attempt to hint via to the
key enterprise capabilities and processes it helps.
Not in contrast to a geologist introducing dye at a attainable supply for a
river after which seeing which streams and tributaries the dye ultimately seems in
downstream.
This method is very helpful the place information concerning the legacy integration
and corresponding techniques is briefly provide and is very helpful once we are
creating a brand new element or enterprise course of.
When tracing downstream we would uncover the place this knowledge
comes into play with out first realizing the precise path it
takes, right here you’ll doubtless need to evaluate it towards the unique supply
knowledge to confirm if issues have been altered alongside the way in which.
As soon as we perceive the movement of information we will then see whether it is attainable
to intercept or create a duplicate of the information at supply, which might then movement to
our new answer. Thus as a substitute of integrating to legacy we create some new
integration to permit our new parts to Revert to Supply.
We do want to ensure we account for each upstream and downstream flows,
however these do not must be carried out collectively as we see within the instance
under.
If a brand new integration is not attainable we will use Occasion Interception
or just like create a duplicate of the information movement and route that to our new element,
we need to try this as far upstream as attainable to cut back any
dependency on current legacy behaviors.
When to Use It
Revert to Supply is most helpful the place we’re extracting a selected enterprise
functionality or course of that depends on knowledge that’s finally
sourced from an integration level “hiding behind” a legacy system. It
works greatest the place the information broadly passes via legacy unchanged, the place
there’s little processing or enrichment taking place earlier than consumption.
Whereas this may occasionally sound unlikely in follow we discover many circumstances the place legacy is
simply performing as a integration hub. The primary adjustments we see taking place to
knowledge in these conditions are lack of knowledge, and a discount in timeliness of information.
Lack of knowledge, since fields and components are normally being filtered out
just because there was no method to signify them within the legacy system, or
as a result of it was too expensive and dangerous to make the adjustments wanted.
Discount in timeliness since many legacy techniques use batch jobs for knowledge import, and
as mentioned in Essential Aggregator the “secure knowledge
replace interval” is usually pre-defined and close to unimaginable to vary.
We are able to mix Revert to Supply with Parallel Operating and Reconciliation
with a view to validate that there is not some further change taking place to the
knowledge inside legacy. It is a sound method to make use of generally however
is very helpful the place knowledge flows through totally different paths to totally different
finish factors, however should finally produce the identical outcomes.
There may also be a strong enterprise case to be made
for utilizing Revert to Supply as richer and extra well timed knowledge is usually
out there.
It’s common for supply techniques to have been upgraded or
modified a number of occasions with these adjustments successfully remaining hidden
behind legacy.
We have seen a number of examples the place enhancements to the information
was truly the core justification for these upgrades, however the advantages
have been by no means totally realized because the extra frequent and richer updates might
not be made out there via the legacy path.
We are able to additionally use this sample the place there’s a two manner movement of information with
an underlying integration level, though right here extra care is required.
Any updates finally heading to the supply system should first
movement via the legacy techniques, right here they could set off or replace
different processes. Fortunately it’s fairly attainable to separate the upstream and
downstream flows. So, for instance, adjustments flowing again to a supply system
might proceed to movement through legacy, whereas updates we will take direct from
supply.
It is very important be conscious of any cross purposeful necessities and constraints
that may exist within the supply system, we do not need to overload that system
or discover out it’s not relaiable or out there sufficient to immediately present
the required knowledge.
Retail Retailer Instance
For one retail shopper we have been in a position to make use of Revert to Supply to each
extract a brand new element and enhance current enterprise capabilities.
The shopper had an intensive property of outlets and a extra lately created
web page for on-line buying. Initially the brand new web site sourced all of
it is inventory data from the legacy system, in flip this knowledge
got here from a warehouse stock monitoring system and the retailers themselves.
These integrations have been achieved through in a single day batch jobs. For
the warehouse this labored high quality as inventory solely left the warehouse as soon as
per day, so the enterprise might ensure that the batch replace acquired every
morning would stay legitimate for roughly 18 hours. For the retailers
this created an issue since inventory might clearly depart the retailers at
any level all through the working day.
Given this constraint the web site solely made out there inventory on the market that
was within the warehouse.
The analytics from the positioning mixed with the store inventory
knowledge acquired the next day made clear gross sales have been being
misplaced consequently: required inventory had been out there in a retailer all day,
however the batch nature of the legacy integration made this unimaginable to
benefit from.
On this case a brand new stock element was created, initially to be used solely
by the web site, however with the objective of changing into the brand new system of report
for the group as an entire. This element built-in immediately
with the in-store until techniques which have been completely able to offering
close to real-time updates as and when gross sales came about. The truth is the enterprise
had invested in a extremely dependable community linking their shops so as
to help digital funds, a community that had loads of spare capability.
Warehouse inventory ranges have been initially pulled from the legacy techniques with
long run objective of additionally reverting this to supply at a later stage.
The tip end result was an internet site that would safely supply in-store inventory
for each in-store reservation and on the market on-line, alongside a brand new stock
element providing richer and extra well timed knowledge on inventory actions.
By reverting to supply for the brand new stock element the group
additionally realized they may get entry to way more well timed gross sales knowledge,
which at the moment was additionally solely up to date into legacy through a batch course of.
Reference knowledge similar to product strains and costs continued to movement
to the in-store techniques through the mainframe, completely acceptable given
this modified solely sometimes.

{kind=link}