

Organizations are adopting Apache Kafka and Amazon Managed Streaming for Apache Kafka (Amazon MSK) to seize and analyze information in real-time. Amazon MSK permits you to construct and run manufacturing functions on Apache Kafka with no need Kafka infrastructure administration experience or having to cope with the complicated overheads related to operating Apache Kafka by yourself. With rising maturity, prospects search to construct subtle use circumstances that mix points of actual time and batch processing. As an illustration, you could wish to practice machine studying (ML) fashions based mostly on historic information after which use these fashions to do actual time inferencing. Or you might have considered trying to have the ability to recompute earlier outcomes when the appliance logic modified, e.g., when a brand new KPI is added to a streaming analytics software or when a bug was mounted that precipitated incorrect output. These use circumstances usually require storing information for a number of weeks, months, and even years.
Apache Kafka is effectively positioned to assist these form of use circumstances. Information is retained within the Kafka cluster so long as required by configuring the retention coverage. On this method, the newest information could be processed in actual time for low-latency use circumstances whereas historic information stays accessible within the cluster and could be processed in a batch trend.
Nonetheless, retaining information in a Kafka cluster can turn out to be costly as a result of storage and compute are tightly coupled in a cluster. To scale storage, you have to add extra brokers. However including extra brokers with the only goal of accelerating the storage squanders the remainder of the compute assets like CPU and reminiscence. Additionally, a big cluster with extra nodes provides operational complexity with an extended time to recuperate and rebalance when a dealer fails. To keep away from that operational complexity and better price, you may transfer your information to Amazon Easy Storage Service (Amazon S3) for long-term entry and with cost-effective storage lessons in Amazon S3 you may optimize your general storage price. This solves price challenges, however now you must construct and preserve that a part of the structure for information motion to a distinct information retailer. You additionally must construct completely different information processing logic utilizing completely different APIs for consuming information (Kafka API for streaming, Amazon S3 API for historic reads).
At this time, we’re saying Amazon MSK tiered storage, which brings a nearly limitless and low-cost storage tier for Amazon MSK, making it less complicated and cost-effective for builders to construct streaming information functions. Because the launch of Amazon MSK in 2019, we have now enabled capabilities reminiscent of vertical scaling and automated scaling of dealer storage so you may function your Kafka workloads in an economical method. Earlier this 12 months, we launched provisioned throughput which allows seamlessly scaling I/O with out having to provision further brokers. Tiered storage makes it much more cost-effective so that you can run Kafka workloads. Now you can retailer information in Apache Kafka with out worrying about limits. You may successfully stability your efficiency and prices through the use of the performance-optimized major storage for real-time information and the brand new low-cost tier for the historic information. With just a few clicks, you may transfer streaming information right into a lower-cost tier to retailer information and solely pay for what you employ.
Tiered storage frees you from making arduous trade-offs between supporting the info retention wants of your software groups and the operational complexity that comes with it. This allows you to use the identical code to course of each real-time and historic information to attenuate redundant workflows and simplify architectures. With Amazon MSK tiered storage, you may implement a Kappa structure – a streaming-first software program structure deployment sample – to make use of the identical information processing pipeline for correctness and completeness of knowledge over a for much longer time horizon for enterprise evaluation.
How Amazon MSK tiered storage works
Let’s have a look at how tiered storage works for Amazon MSK. Apache Kafka shops information in information known as log segments. As every phase completes, based mostly on the phase dimension configured at cluster or matter degree, it’s copied to the low-cost storage tier. Information is held in performance-optimized storage for a specified retention time, or as much as a specified dimension, after which deleted. There’s a separate time and dimension restrict setting for the low-cost storage, which should be longer than the performance-optimized storage tier. If purchasers request information from segments saved within the low-cost tier, the dealer reads the info from it and serves the info in the identical method as if it have been being served from the performance-optimized storage. The APIs and current purchasers work with minimal modifications. When your software begins studying information from the low-cost tier, you may anticipate a rise in learn latency for the primary few bytes. As you begin studying the remaining information sequentially from the low-cost tier, you may anticipate latencies which are much like the first storage tier. With tiered storage, you pay for the quantity of knowledge you retailer and the quantity of knowledge you retrieve.
For a pricing instance, let’s think about a workload the place your ingestion charge is 15 MB/s, with a replication issue of three, and also you wish to retain information in your Kafka cluster for 7 days. For such a workload, it requires 6x m5.massive brokers, with 32.4 TB EBS storage, which prices $4,755. However in the event you use tiered storage for a similar workload with native retention of 4 hours and general information retention of seven days, it requires 3x m5.massive brokers, with 0.8 TB EBS storage and 9 TB of tiered storage, which prices $1,584. If you wish to learn all of the historic information without delay, it prices $13 ($0.0015 per GB retrieval price). On this instance with tiered storage, you save round 66% of your general price.
Get began utilizing Amazon MSK tiered storage
To allow tiered storage in your current cluster, improve your MSK cluster to Kafka model 2.8.2.tiered after which select Tiered storage and EBS storage as your cluster storage mode on the Amazon MSK console.

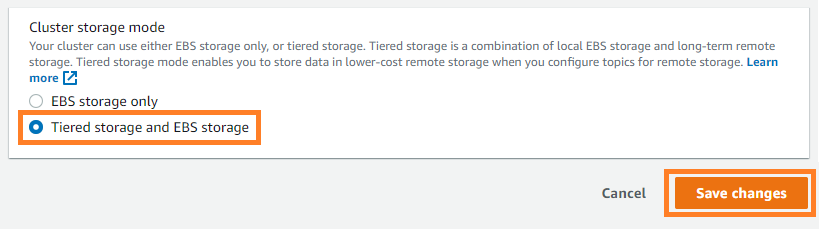
After tiered storage is enabled on the cluster degree, run the next command to allow tiered storage on an current matter. On this instance, you’re enabling tiered storage on a subject known as msk-ts-topic with 7 days’ retention (native.retention.ms=604800000) for a neighborhood high-performance storage tier, setting 180 days’ retention (retention.ms=15550000000) to retain the info within the low-cost storage tier, and updating the log phase dimension to 48 MB:
Availability and pricing
Amazon MSK tiered storage is out there in all AWS areas the place Amazon MSK is out there excluding the AWS China, AWS GovCloud areas. This low-cost storage tier scales to nearly limitless storage and requires no upfront provisioning. You pay just for the amount of knowledge retained and retrieved within the low-cost tier.
For extra details about this function and its pricing, see the Amazon MSK developer information and Amazon MSK pricing web page. For locating the proper sizing in your cluster, see the very best practices web page.
Abstract
With Amazon MSK tiered storage you don’t must provision storage for the low-cost tier or handle the infrastructure. Tiered storage allows you to scale to nearly limitless storage. You may entry information within the low-cost tier utilizing the identical purchasers you presently use to learn information from the high-performance major storage tier. Apache Kafka’s shopper API, streams API, and connectors devour information from each tiers with out modifications. You may modify the retention limits on the low-cost storage tier equally as to how one can modify the retention limits on the high-performance storage.
Allow tiered storage in your MSK clusters right this moment to retain information longer at a decrease price.
Concerning the Creator
 Masudur Rahaman Sayem is a Streaming Architect at AWS. He works with AWS prospects globally to design and construct information streaming structure to resolve real-world enterprise issues. He’s keen about distributed methods. He additionally likes to learn, particularly basic comedian books.
Masudur Rahaman Sayem is a Streaming Architect at AWS. He works with AWS prospects globally to design and construct information streaming structure to resolve real-world enterprise issues. He’s keen about distributed methods. He additionally likes to learn, particularly basic comedian books.

{kind=link}