

SAP’s latest announcement of a strategic partnership with Databricks has generated vital pleasure amongst SAP prospects. Databricks, the info and AI consultants, presents a compelling alternative for leveraging analytics and ML/AI capabilities by integrating SAP HANA with Databricks. Given this collaboration’s immense curiosity, we’re thrilled to embark on a deep dive weblog collection.
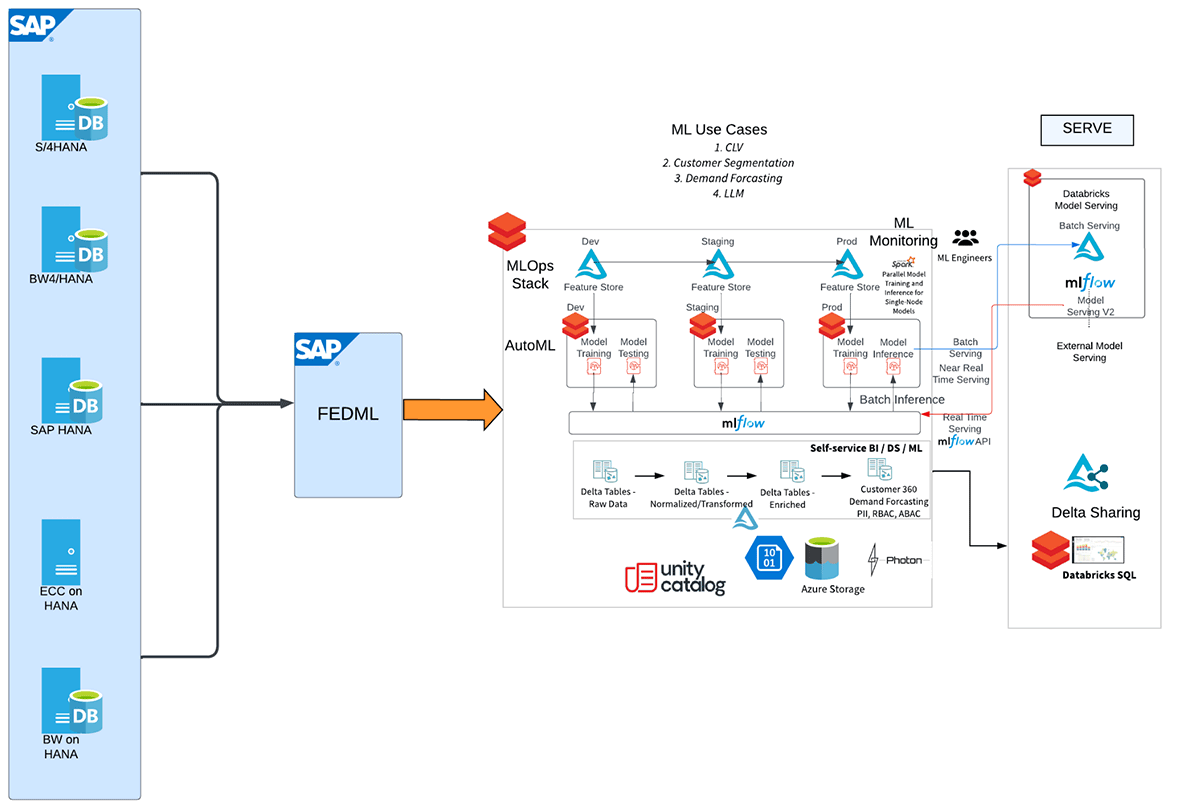
In lots of buyer eventualities, a SAP HANA system serves as the first entity for knowledge basis from varied supply methods, together with SAP CRM, SAP ERP/ECC, SAP BW. Now, the thrilling chance arises to seamlessly combine this sturdy SAP HANA analytical sidecar system with Databricks, additional enhancing the group’s knowledge capabilities. By connecting SAP HANA with Databricks, companies can leverage the superior analytics and machine studying capabilities (like MLflow, AutoML, MLOps) of Databricks whereas harnessing the wealthy and consolidated knowledge saved inside SAP HANA. This integration opens up a world of prospects for organizations to unlock precious insights and drive data-driven decision-making throughout their SAP methods.
A number of approaches can be found to entry SAP HANA tables, SQL views, and calculation views in Databricks. Nevertheless, the quickest method is to make use of SAP Federated ML Python libraries (FedML) which may be put in from the PyPi repository. Probably the most vital benefit is SAP FedML package deal has a local implementation for Databricks, with strategies like “execute_query_pyspark(‘question’)” that may execute SQL queries and return the fetched knowledge as a PySpark DataFrame.
Allow us to begin with SAP HANA and Databricks integration
With the intention to check this integration with Databricks, SAP HANA 2.0 was put in within the Azure cloud.
Put in SAP HANA information in Azure:
| model | 2.00.061.00.1644229038 |
| department | fa/hana2sp06 |
| Working System | SUSE Linux Enterprise Server 15 SP1 |
Right here is the high-level workflow depicting the completely different steps of this integration.
Please see the connected pocket book for extra detailed directions for extracting knowledge from SAP HANA’s calculation views and tables into Databricks utilizing SAP FedML.
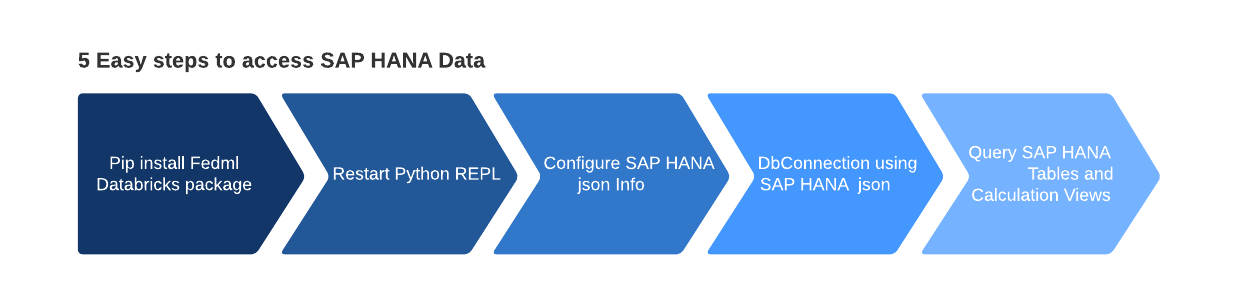
As soon as the above steps are carried out, create the Dbconnection utilizing the config_json, which carries the SAP HANA connection data.
db = DbConnection(dict_obj=config_json)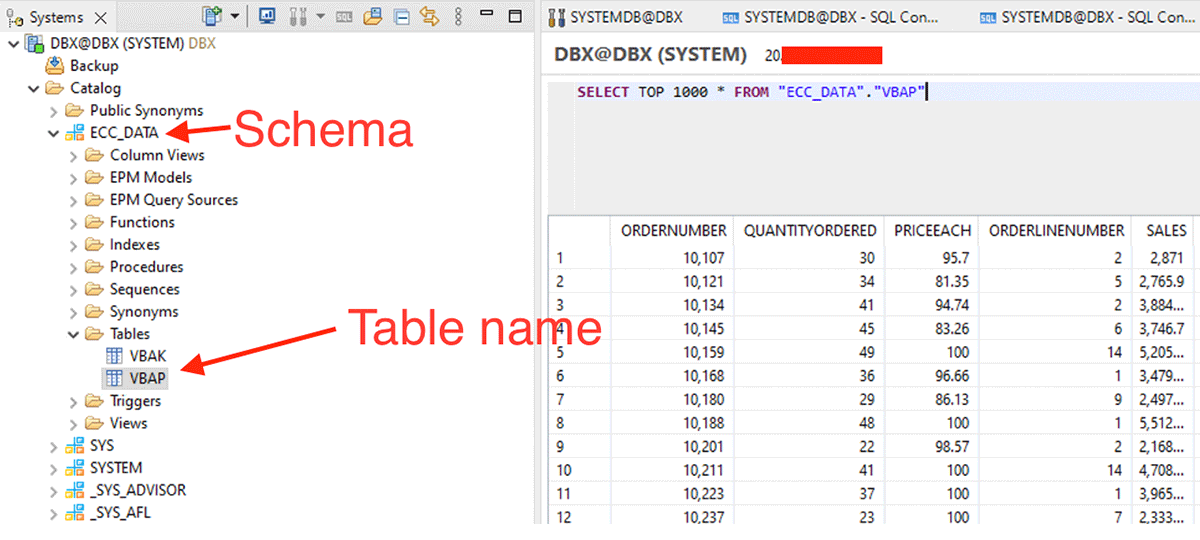
Begin creating the dataframes utilizing the execute_query_pyspark API from FedML and passing within the choose question as proven under with schema, desk title.
df_sap_ecc_hana_vbap = db.execute_query_pyspark('SELECT * FROM "ECC_DATA"."VBAP"')To get knowledge from the Calculation View, we now have to do the next:
For instance, this calculation view is created within the inside schema “_SYS_BIC”.
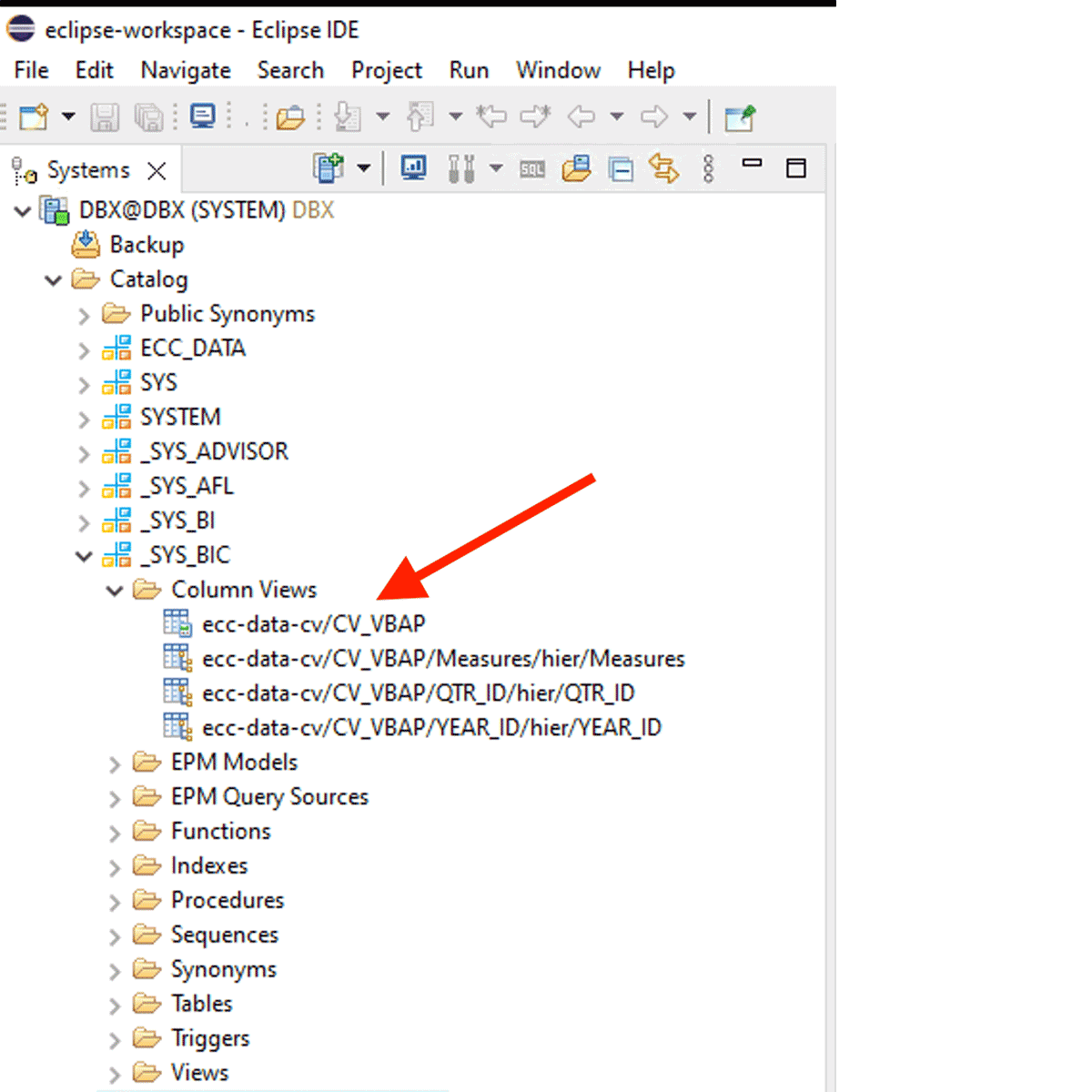
This code snippet creates a PySpark dataframe named “df_sap_ecc_hana_cv_vbap” and populates it from a Calculation View from the SAP HANA system (on this case, CV_VBAP).
df_sap_ecc_hana_cv_vbap = db.execute_query_pyspark('SELECT * FROM "_SYS_BIC"."ecc-data-cv/CV_VBAP"')After producing the PySpark knowledge body, one can leverage Databricks’ limitless capabilities for exploratory knowledge evaluation (EDA) and machine studying/synthetic intelligence (ML/AI).
Summarizing the above knowledge frames:
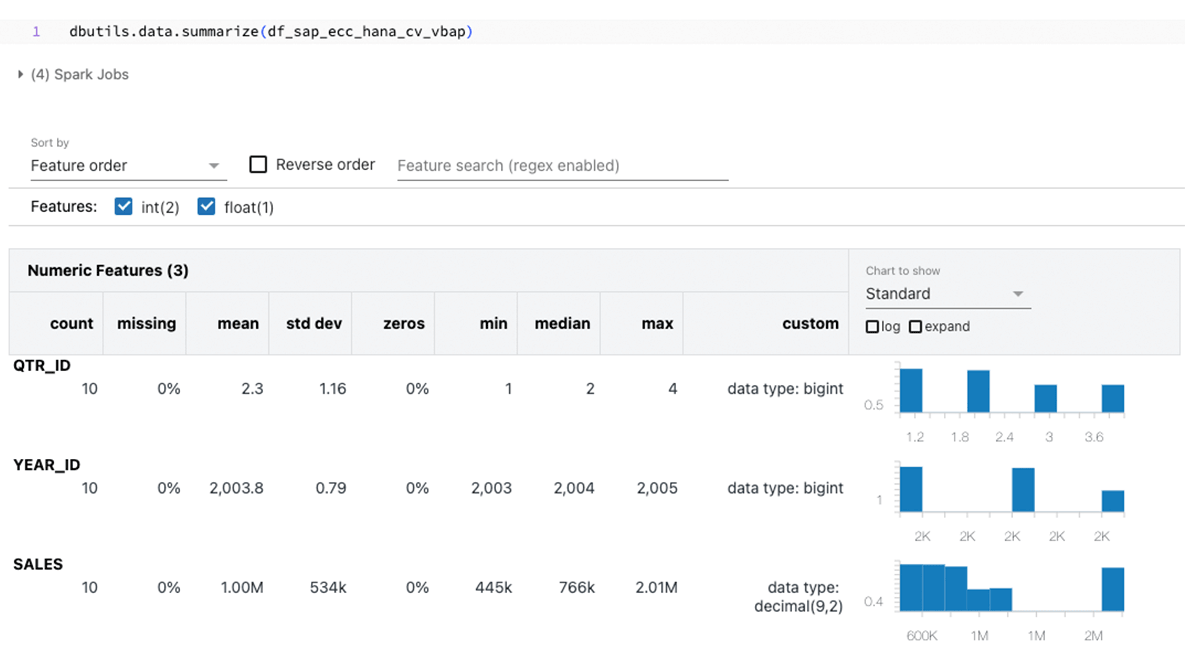
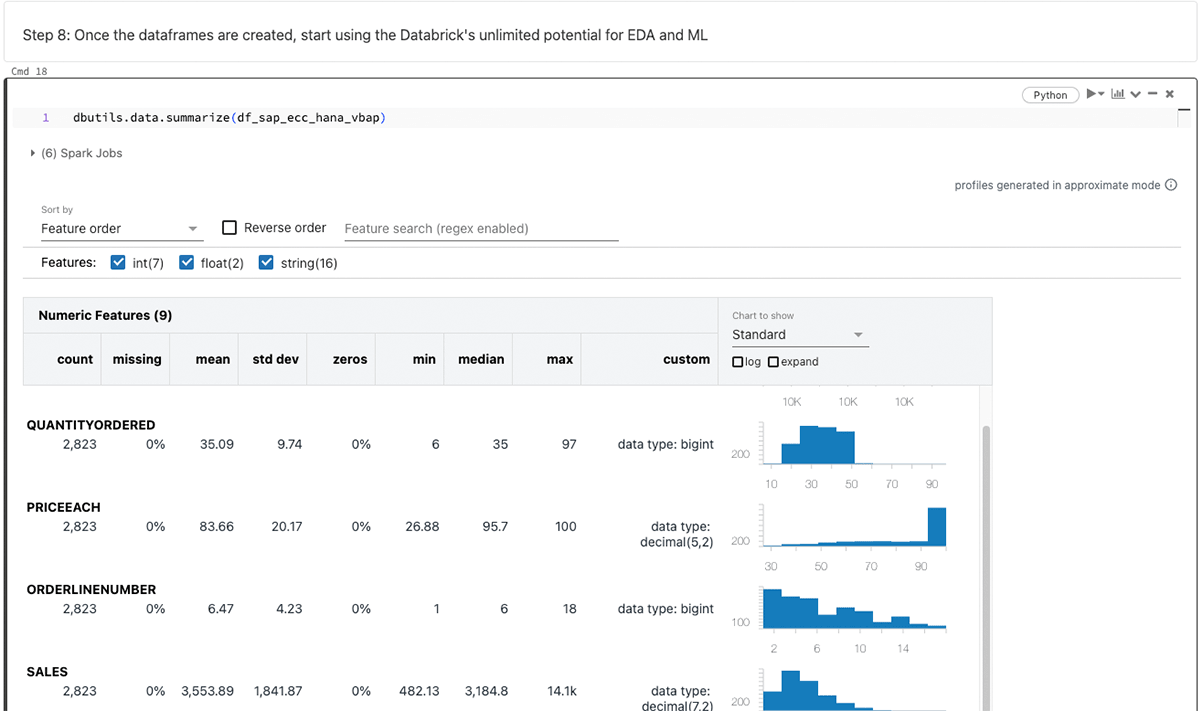
The main focus of this weblog revolves round SAP FedML for SAP HANA, but it surely’s price noting that different strategies corresponding to sparkjdbc, hdbcli, and hana_ml can be found for comparable functions.

{kind=link}