
Derivatives play a central function in optimization and machine studying. By domestically approximating a coaching loss, derivatives information an optimizer towards decrease values of the loss. Automated differentiation frameworks comparable to TensorFlow, PyTorch, and JAX are an important a part of fashionable machine studying, making it possible to make use of gradient-based optimizers to coach very complicated fashions.
However are derivatives all we want? By themselves, derivatives solely inform us how a perform behaves on an infinitesimal scale. To make use of derivatives successfully, we regularly have to know greater than that. For instance, to decide on a studying fee for gradient descent, we have to know one thing about how the loss perform behaves over a small however finite window. A finite-scale analogue of automated differentiation, if it existed, might assist us make such selections extra successfully and thereby velocity up coaching.
In our new paper “Routinely Bounding The Taylor The rest Collection: Tighter Bounds and New Functions“, we current an algorithm known as AutoBound that computes polynomial higher and decrease bounds on a given perform, that are legitimate over a user-specified interval. We then start to discover AutoBound’s purposes. Notably, we current a meta-optimizer known as SafeRate that makes use of the higher bounds computed by AutoBound to derive studying charges which might be assured to monotonically cut back a given loss perform, with out the necessity for time-consuming hyperparameter tuning. We’re additionally making AutoBound accessible as an open-source library.
The AutoBound algorithm
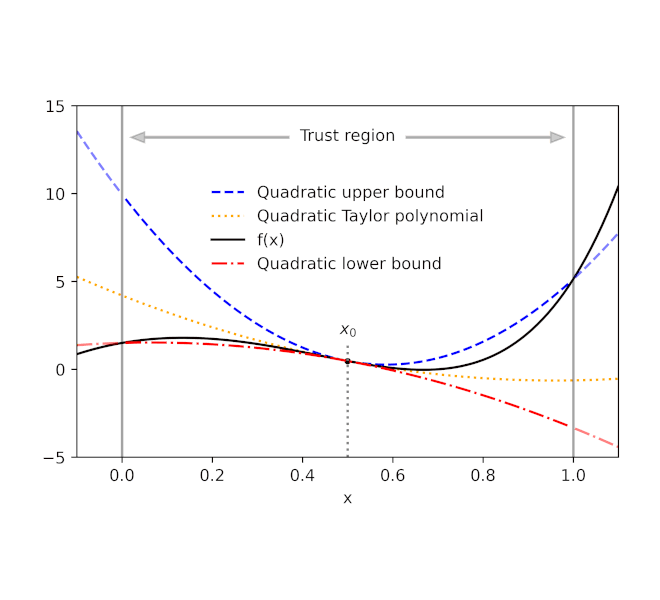
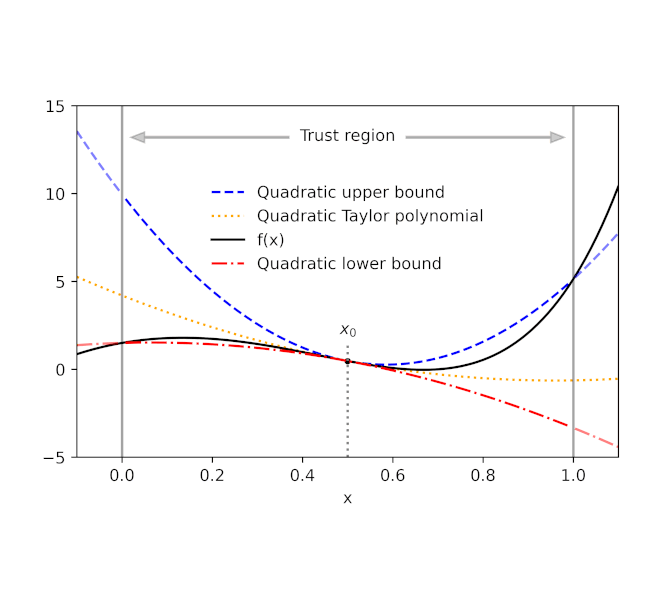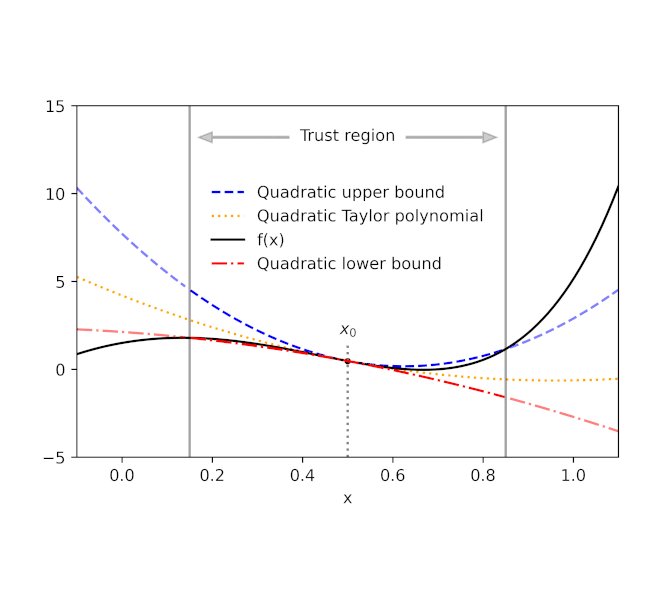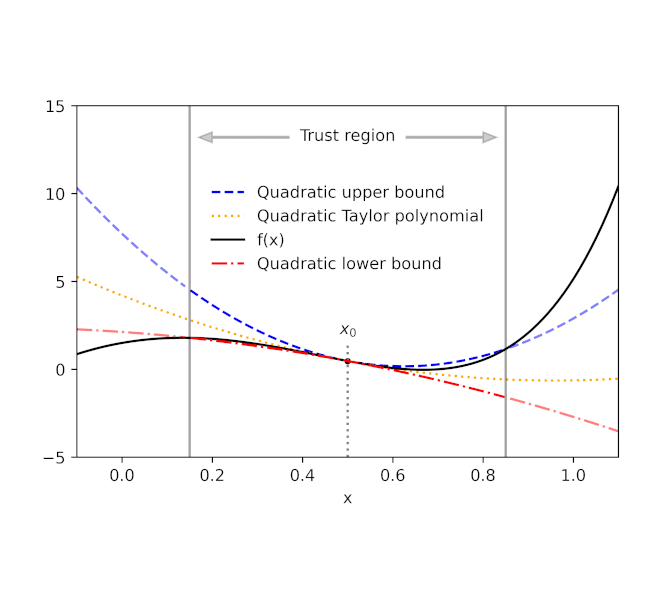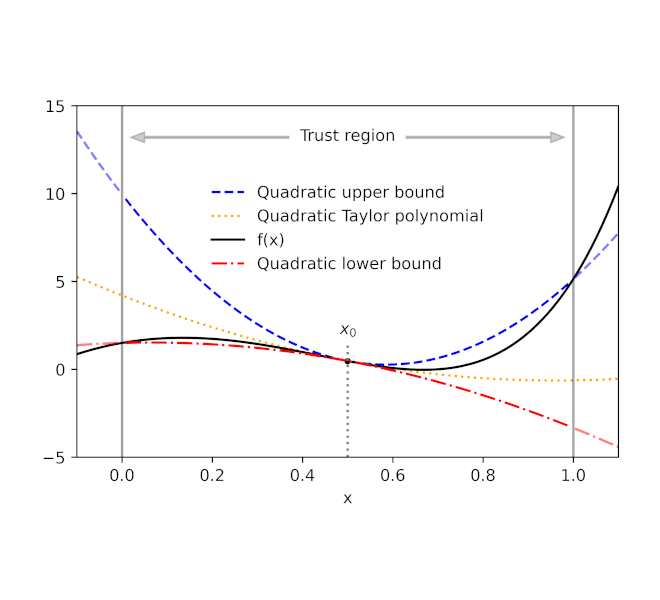
Given a perform f and a reference level x0, AutoBound computes polynomial higher and decrease bounds on f that maintain over a user-specified interval known as a belief area. Like Taylor polynomials, the bounding polynomials are equal to f at x0. The bounds change into tighter because the belief area shrinks, and method the corresponding Taylor polynomial because the belief area width approaches zero.
 |
| Routinely-derived quadratic higher and decrease bounds on a one-dimensional perform f, centered at x0=0.5. The higher and decrease bounds are legitimate over a user-specified belief area, and change into tighter because the belief area shrinks. |
Like automated differentiation, AutoBound may be utilized to any perform that may be carried out utilizing normal mathematical operations. Actually, AutoBound is a generalization of Taylor mode automated differentiation, and is equal to it within the particular case the place the belief area has a width of zero.
To derive the AutoBound algorithm, there have been two essential challenges we needed to deal with:
- We needed to derive polynomial higher and decrease bounds for varied elementary capabilities, given an arbitrary reference level and arbitrary belief area.
- We needed to give you an analogue of the chain rule for combining these bounds.
Bounds for elementary capabilities
For quite a lot of commonly-used capabilities, we derive optimum polynomial higher and decrease bounds in closed kind. On this context, “optimum” means the bounds are as tight as attainable, amongst all polynomials the place solely the maximum-diploma coefficient differs from the Taylor collection. Our idea applies to elementary capabilities, comparable to exp and log, and customary neural community activation capabilities, comparable to ReLU and Swish. It builds upon and generalizes earlier work that utilized solely to quadratic bounds, and just for an unbounded belief area.
 |
| Optimum quadratic higher and decrease bounds on the exponential perform, centered at x0=0.5 and legitimate over the interval [0, 2]. |
A brand new chain rule
To compute higher and decrease bounds for arbitrary capabilities, we derived a generalization of the chain rule that operates on polynomial bounds. For instance the concept, suppose we have now a perform that may be written as
and suppose we have already got polynomial higher and decrease bounds on g and h. How can we compute bounds on f?
The important thing seems to be representing the higher and decrease bounds for a given perform as a single polynomial whose highest-degree coefficient is an interval slightly than a scalar. We will then plug the sure for h into the sure for g, and convert the outcome again to a polynomial of the identical kind utilizing interval arithmetic. Below appropriate assumptions concerning the belief area over which the sure on g holds, it may be proven that this process yields the specified sure on f.
 |
| The interval polynomial chain rule utilized to the capabilities h(x) = sqrt(x) and g(y) = exp(y), with x0=0.25 and belief area [0, 0.5]. |
Our chain rule applies to one-dimensional capabilities, but additionally to multivariate capabilities, comparable to matrix multiplications and convolutions.
Propagating bounds
Utilizing our new chain rule, AutoBound propagates interval polynomial bounds via a computation graph from the inputs to the outputs, analogous to forward-mode automated differentiation.
 |
| Ahead propagation of interval polynomial bounds for the perform f(x) = exp(sqrt(x)). We first compute (trivial) bounds on x, then use the chain rule to compute bounds on sqrt(x) and exp(sqrt(x)). |
To compute bounds on a perform f(x), AutoBound requires reminiscence proportional to the dimension of x. For that reason, sensible purposes apply AutoBound to capabilities with a small variety of inputs. Nonetheless, as we are going to see, this doesn’t forestall us from utilizing AutoBound for neural community optimization.
Routinely deriving optimizers, and different purposes
What can we do with AutoBound that we could not do with automated differentiation alone?
Amongst different issues, AutoBound can be utilized to routinely derive problem-specific, hyperparameter-free optimizers that converge from any place to begin. These optimizers iteratively cut back a loss by first utilizing AutoBound to compute an higher sure on the loss that’s tight on the present level, after which minimizing the higher sure to acquire the following level.
 |
| Minimizing a one-dimensional logistic regression loss utilizing quadratic higher bounds derived routinely by AutoBound. |
Optimizers that use higher bounds on this means are known as majorization-minimization (MM) optimizers. Utilized to one-dimensional logistic regression, AutoBound rederives an MM optimizer first revealed in 2009. Utilized to extra complicated issues, AutoBound derives novel MM optimizers that might be tough to derive by hand.
We will use the same concept to take an present optimizer comparable to Adam and convert it to a hyperparameter-free optimizer that’s assured to monotonically cut back the loss (within the full-batch setting). The ensuing optimizer makes use of the identical replace path as the unique optimizer, however modifies the educational fee by minimizing a one-dimensional quadratic higher sure derived by AutoBound. We consult with the ensuing meta-optimizer as SafeRate.
 |
| Efficiency of SafeRate when used to coach a single-hidden-layer neural community on a subset of the MNIST dataset, within the full-batch setting. |
Utilizing SafeRate, we will create extra strong variants of present optimizers, at the price of a single further ahead move that will increase the wall time for every step by a small issue (about 2x within the instance above).
Along with the purposes simply mentioned, AutoBound can be utilized for verified numerical integration and to routinely show sharper variations of Jensen’s inequality, a basic mathematical inequality used ceaselessly in statistics and different fields.
Enchancment over classical bounds
Bounding the Taylor the rest time period routinely just isn’t a brand new concept. A classical method produces diploma okay polynomial bounds on a perform f which might be legitimate over a belief area [a, b] by first computing an expression for the okayth by-product of f (utilizing automated differentiation), then evaluating this expression over [a,b] utilizing interval arithmetic.
Whereas elegant, this method has some inherent limitations that may result in very unfastened bounds, as illustrated by the dotted blue strains within the determine under.
 |
| Quadratic higher and decrease bounds on the lack of a multi-layer perceptron with two hidden layers, as a perform of the preliminary studying fee. The bounds derived by AutoBound are a lot tighter than these obtained utilizing interval arithmetic analysis of the second by-product. |
Trying ahead
Taylor polynomials have been in use for over 300 years, and are omnipresent in numerical optimization and scientific computing. Nonetheless, Taylor polynomials have vital limitations, which may restrict the capabilities of algorithms constructed on prime of them. Our work is a part of a rising literature that acknowledges these limitations and seeks to develop a brand new basis upon which extra strong algorithms may be constructed.
Our experiments thus far have solely scratched the floor of what’s attainable utilizing AutoBound, and we consider it has many purposes we have now not found. To encourage the analysis group to discover such prospects, we have now made AutoBound accessible as an open-source library constructed on prime of JAX. To get began, go to our GitHub repo.
Acknowledgements
This submit is predicated on joint work with Josh Dillon. We thank Alex Alemi and Sergey Ioffe for beneficial suggestions on an earlier draft of the submit.

{kind=link}