
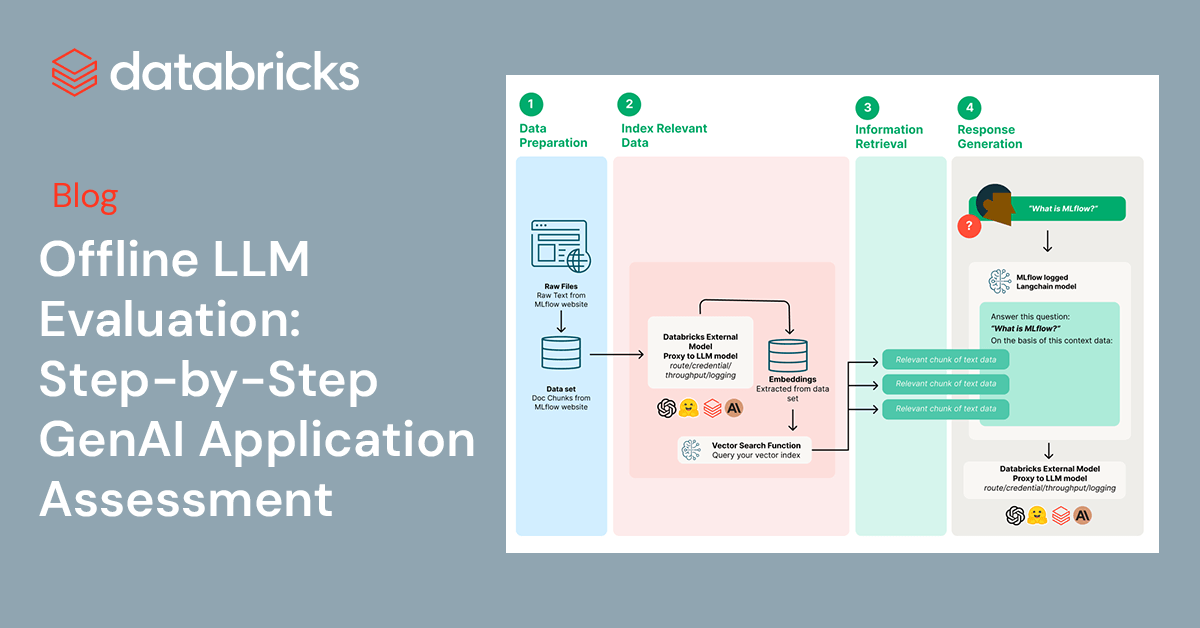
Background
In an period the place Retrieval-Augmented Technology (RAG) is revolutionizing the way in which we work together with AI-driven purposes, guaranteeing the effectivity and effectiveness of those techniques has by no means been extra important. Databricks and MLflow are on the forefront of this innovation, providing streamlined options for the important analysis of GenAI purposes.
This weblog submit guides you thru the straightforward and efficient strategy of leveraging the Databricks Knowledge Intelligence Platform to boost and consider the standard of the three core elements of your GenAI purposes: Prompts, Retrieval System, and Basis LLM, guaranteeing that your GenAI purposes proceed to generate correct outcomes.
Use Case
We’re going to be making a QA chatbot that may reply questions from the MLflow documentation after which consider the outcomes.
Set Up Exterior Fashions in Databricks
Databricks Mannequin Serving characteristic can be utilized to handle, govern, and entry exterior fashions from numerous massive language mannequin (LLM) suppliers, comparable to Azure OpenAI GPT, Anthropic Claude, or AWS Bedrock, inside a company. It affords a high-level interface that simplifies the interplay with these providers by offering a unified endpoint to deal with particular LLM associated requests.
Main benefits of utilizing Mannequin Serving:
- Question Fashions via a Unified Interface: Simplifies the interface to name a number of LLMs in your group. Question fashions via a unified OpenAI-compatible API and SDK and handle all fashions via a single UI.
- Govern and Handle Fashions: Centralizes endpoint administration of a number of LLMs in your group. This contains the flexibility to handle permissions and observe utilization limits.
- Central Key Administration: Centralizes API key administration in a safe location, which reinforces organizational safety by minimizing key publicity within the system and code, and reduces the burden on end-users.
Create a Serving Endpoint with an Exterior Mannequin in Databricks
import mlflow
import mlflow.deployments
shopper = mlflow.deployments.get_deploy_client("databricks")
endpoint_name = f"test-endpoint-{uuid.uuid4()}"
shopper.create_endpoint(
title=endpoint_name,
config={
"served_entities": [
{
"name": "test",
"external_model": {
"name": "gpt-3.5-turbo-instruct",
"provider": "openai",
"task": "llm/v1/completions",
"openai_config": {
"openai_api_type": "azure",
"openai_api_key": "{{secrets/<your-scope-name>/<your-key-name>}}", ## Use Databricks Secrets.
"openai_api_base": "https://<your-endpoint>.openai.azure.com/",
"openai_deployment_name": "<your-deployment-name>",
"openai_api_version": "2023-05-15",
},
},
}
],
},
)Discover prompts with the Databricks AI Playground
On this part, we’ll perceive: How effectively do totally different prompts carry out with the chosen LLM?
We not too long ago launched the Databricks AI Playground, which offers a best-in-class expertise for crafting the proper immediate. With no code required, you possibly can check out a number of LLMs served as Endpoints in Databricks, and check totally different parameters and prompts.
Main benefits of the Databricks AI Playground are:
- Fast Testing: Shortly check deployed fashions instantly in Databricks.
- Simple Comparability: Central location to check a number of fashions on totally different prompts and parameters for comparability and choice.
Utilizing Databricks AI Playground
We delve into testing related prompts with OpenAI GPT 3.5 Turbo, leveraging the Databricks AI Playground.
Evaluating totally different prompts and parameters
Within the Playground, you’ll be able to examine the output of a number of prompts to see which supplies higher outcomes. Straight within the Playground, you possibly can attempt a number of prompts, fashions, and parameters to determine which mixture offers the most effective outcomes. The mannequin and parameters combo can then be added to the GenAI app and used for reply technology with the suitable context.
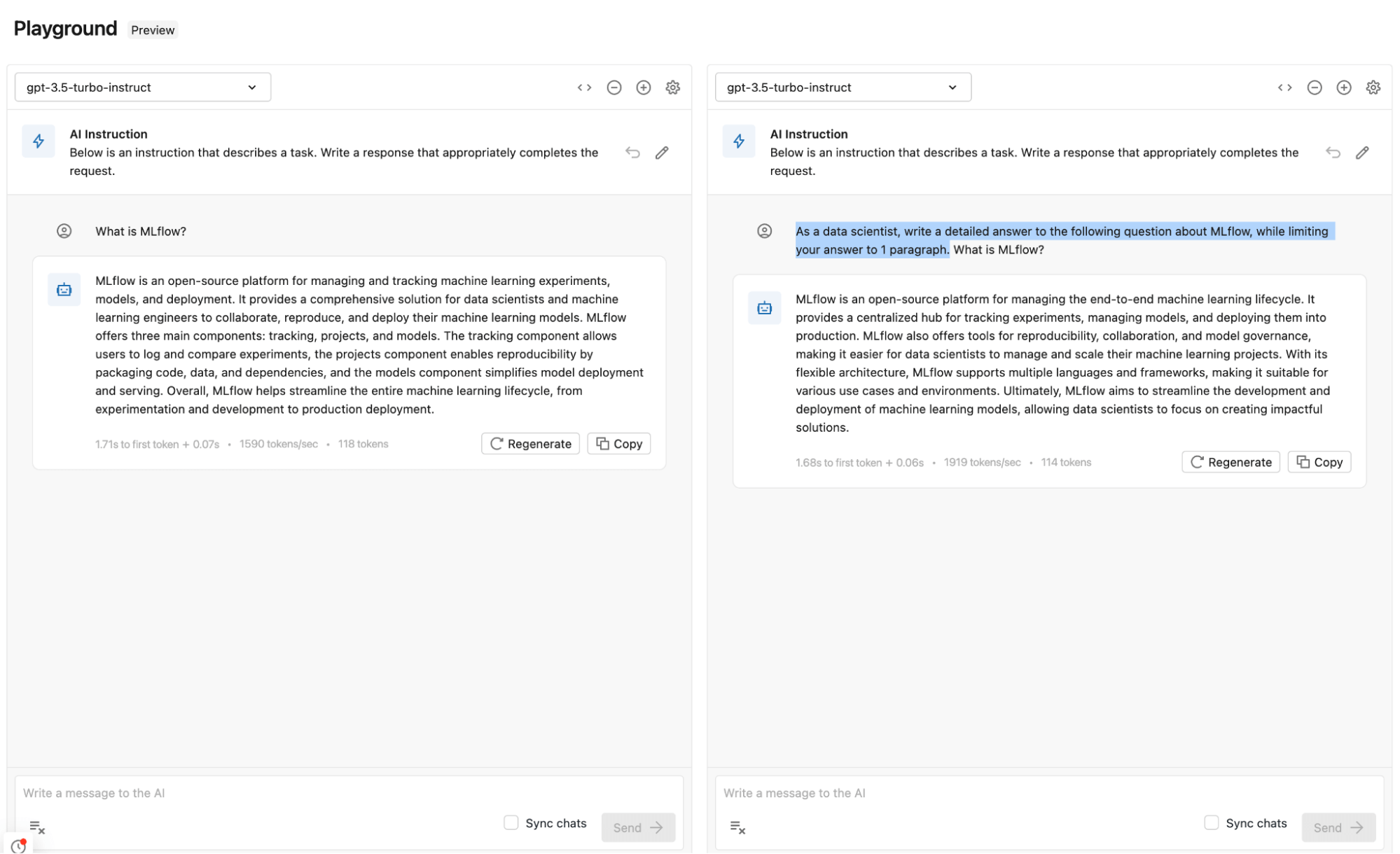
Including Mannequin and Parameters to GenAI app
After enjoying with just a few prompts and parameters, you should utilize the identical settings and mannequin in your GenAI utility.
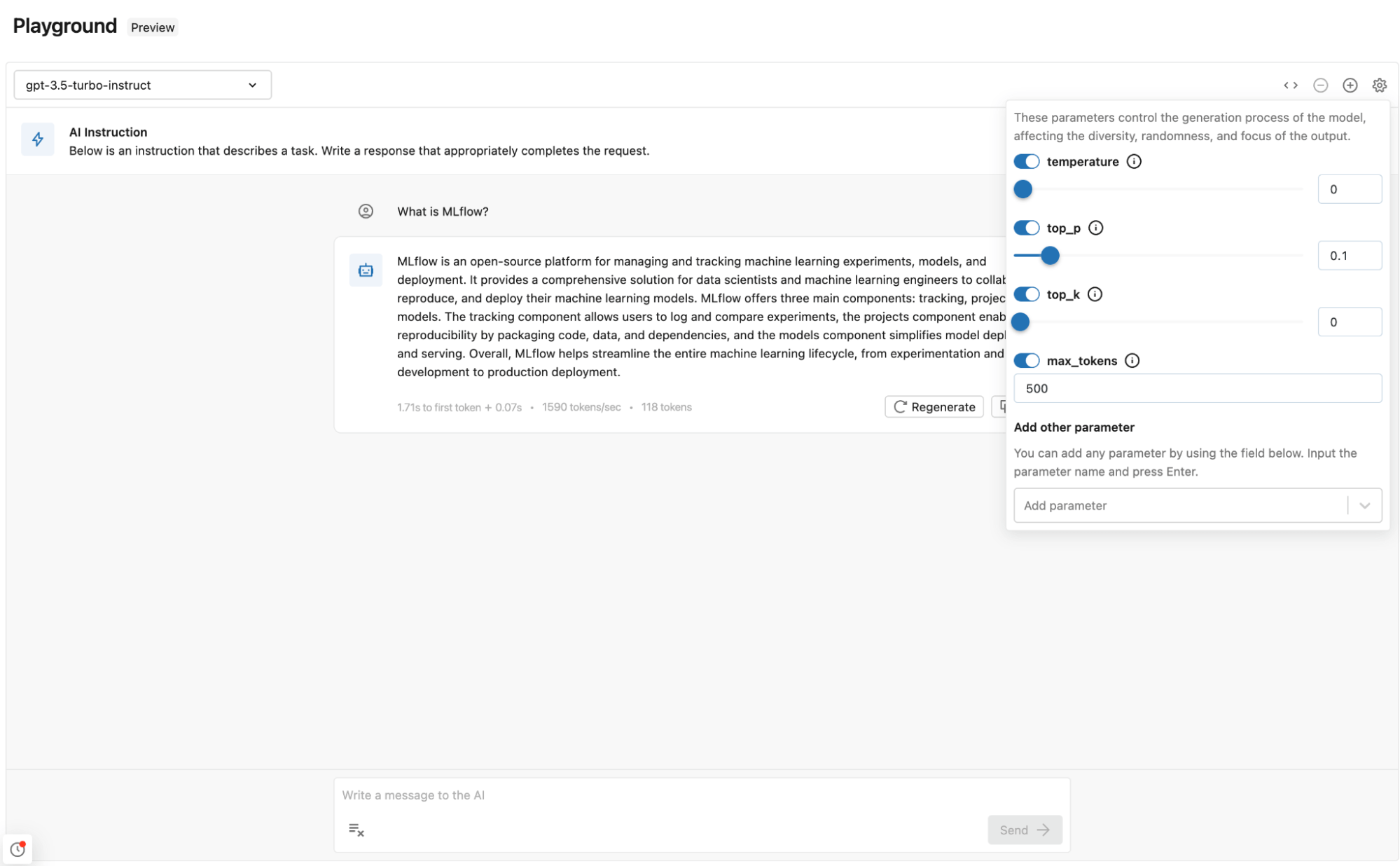
Instance of the best way to import the identical exterior mannequin in LangChain. We’ll cowl how we flip this right into a GenAI POC within the subsequent part.
from langchain.llms import Databricks
llm = Databricks(
endpoint_name="<endpoint-name>",
extra_params={"temperature": 0.1,
"top_p": 0.1,
"max_tokens": 500,
} #parameters utilized in AI Playground
)Create GenAI POC with LangChain and log with MLflow
Now that we have now discovered a very good mannequin and immediate parameters on your use case, we’re going to create a pattern GenAI app that may be a QA chatbot that may reply questions from the MLflow documentation utilizing a vector database, embedding mannequin with the Databricks Basis Mannequin API and Azure OpenAI GPT 3.5 because the technology mannequin.
Create a pattern GenAI app with LangChain utilizing docs from the MLflow web site
import os
import pandas as pd
import mlflow
import chromadb
from langchain.chains import RetrievalQA
from langchain.document_loaders import WebBaseLoader
from langchain.llms import Databricks
from langchain.embeddings.databricks import DatabricksEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
loader = WebBaseLoader(
[
"https://mlflow.org/docs/latest/index.html",
"https://mlflow.org/docs/latest/tracking/autolog.html",
"https://mlflow.org/docs/latest/getting-started/tracking-server-overview/index.html",
"https://mlflow.org/docs/latest/python_api/mlflow.deployments.html" ])
paperwork = loader.load()
CHUNK_SIZE = 1000
text_splitter = CharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=0)
texts = text_splitter.split_documents(paperwork)
llm = Databricks(
endpoint_name="<endpoint-name>",
extra_params={"temperature": 0.1,
"top_p": 0.1,
"max_tokens": 500,
} #parameters used in AI Playground
)
# create the embedding operate utilizing Databricks Basis Mannequin APIs
embedding_function = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
docsearch = Chroma.from_documents(texts, embedding_function)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=docsearch.as_retriever(fetch_k=3),
return_source_documents=True,
)For purchasers eager to scale the retriever used of their GenAI utility, we advise utilizing Databricks Vector Search, a serverless similarity search engine that permits you to retailer a vector illustration of your information, together with metadata, in a vector database.
Analysis of Retrieval system with MLflow
On this part, we’ll perceive: How effectively does the retriever work with a given question?
In MLflow 2.9.1, Analysis for retrievers was launched and offers a means so that you can assess the effectivity of their retriever with the MLflow consider API. You should use this API to judge the effectiveness of your embedding mannequin, the highest Ok threshold alternative, or the chunking technique.
Creating Floor Fact dataset
Curating a floor fact dataset for evaluating your GenAI usually includes the meticulous activity of manually annotating check units, a course of that calls for each time and area experience. On this weblog, we’re taking a unique route. We’re leveraging the ability of an LLM to generate artificial information for testing, providing a quick-start strategy to get a way of your GenAI app’s retrieval functionality, and a warm-up for all of the in-depth analysis work that will observe. To our readers and prospects, we emphasize the significance of crafting a dataset that mirrors the anticipated inputs and outputs of your GenAI utility. It is a journey price taking for the unbelievable insights you will acquire!
You’ll be able to discover with the total dataset however let’s demo with a subset of the generated information. The query column comprises all of the questions that might be evaluated and the supply column is the anticipated supply for the reply for the questions as an ordered checklist of strings.
eval_data = pd.DataFrame(
{
"query": [
"What is MLflow?",
"What is Databricks?",
"How to serve a model on Databricks?",
"How to enable MLflow Autologging for my workspace by default?",
],
"supply": [
["https://mlflow.org/docs/latest/index.html"],
["https://mlflow.org/docs/latest/getting-started/tracking-server-overview/index.html"],
["https://mlflow.org/docs/latest/python_api/mlflow.deployments.html"],
["https://mlflow.org/docs/latest/tracking/autolog.html"],
],
}
)Consider the Embedding Mannequin with MLflow
The standard of your embedding mannequin is pivotal for correct retrieval. In MLflow 2.9.0, we launched three built-in metrics mlflow.metrics.precision_at_k(okay), mlflow.metrics.recall_at_k(okay) and mlflow.metrics.ndcg_at_k(okay) to assist decide how efficient your retriever is at predicting essentially the most related outcomes for you. For instance; Suppose the vector database returns 10 outcomes (okay=10), and out of those 10 outcomes, 4 are related to your question. The precision_at_10 can be 4/10 or 40%.
def evaluate_embedding(embedding_function):
CHUNK_SIZE = 1000
list_of_documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=0)
docs = text_splitter.split_documents(list_of_documents)
retriever = Chroma.from_documents(docs, embedding_function).as_retriever()
def retrieve_doc_ids(query: str) -> Record[str]:
docs = retriever.get_relevant_documents(query)
doc_ids = [doc.metadata["source"] for doc in docs]
return doc_ids
def retriever_model_function(question_df: pd.DataFrame) -> pd.Sequence:
return question_df["question"].apply(retrieve_doc_ids)
with mlflow.start_run() as run:
evaluate_results = mlflow.consider(
mannequin=retriever_model_function,
information=eval_data,
model_type="retriever",
targets="supply",
evaluators="default",
)
return evaluate_results
result1 = evaluate_embedding(DatabricksEmbeddings(endpoint="databricks-bge-large-en"))result2 = evaluate_embedding(<another-embedding-function>)
eval_results_of_retriever_df_bge = result1.tables["eval_results_table"]
show(eval_results_of_retriever_df_bge)The analysis will return a desk with the outcomes of your analysis for every query. i.e. for this check, we are able to see that the retriever appears to performing nice for the questions “Methods to allow MLflow Autologging for my workspace by default?” with a Precision @ Ok rating is 1, and isn’t retrieving any of the suitable documentation for the questions “What’s MLflow?” because the precision @ Ok rating is 0. With this perception, we are able to debug the retriever and enhance the retriever for questions like “What’s MLflow?”.

Consider retriever with totally different Prime Ok values with MLflow
You’ll be able to shortly calculate the metrics for various Ks by specifying the extra_metrics argument.
with mlflow.start_run() as run:
evaluate_results = mlflow.consider(
information=eval_results_of_retriever_df_bge,
targets="supply",
predictions="outputs",
evaluators="default",
extra_metrics=[
mlflow.metrics.precision_at_k(1),
mlflow.metrics.precision_at_k(2),
mlflow.metrics.precision_at_k(3),
mlflow.metrics.recall_at_k(1),
mlflow.metrics.recall_at_k(2),
mlflow.metrics.recall_at_k(3),
mlflow.metrics.ndcg_at_k(1),
mlflow.metrics.ndcg_at_k(2),
mlflow.metrics.ndcg_at_k(3),
],
)
show(evaluate_results.tables["eval_results_table"])The analysis will return a desk with the outcomes of your analysis for every query, and you may higher perceive which Ok worth to make use of when retrieving paperwork. i.e. for this check we are able to see altering the highest Ok worth can positively have an effect on the precision of the retriever for questions like “What’s Databricks”.

Consider the Chunking Technique with MLflow
The effectiveness of your chunking technique is important. We discover how MLflow can help on this analysis, specializing in the retrieval mannequin kind and its affect on general efficiency.
def evaluate_chunk_size(chunk_size):
list_of_documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=chunk_size,chunk_overlap=0)
docs = text_splitter.split_documents(list_of_documents)
embedding_function = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
retriever = Chroma.from_documents(docs, embedding_function).as_retriever()
def retrieve_doc_ids(query: str) -> Record[str]:
docs = retriever.get_relevant_documents(query)
doc_ids = [doc.metadata["source"] for doc in docs]
return doc_ids
def retriever_model_function(question_df: pd.DataFrame) -> pd.Sequence:
return question_df["question"].apply(retrieve_doc_ids)
with mlflow.start_run() as run:
evaluate_results = mlflow.consider(
mannequin=retriever_model_function,
information=eval_data,
model_type="retriever",
targets="supply",
evaluators="default",
)
return evaluate_results
result1 = evaluate_chunk_size(500)
result2 = evaluate_chunk_size(2000)
show(result1.tables["eval_results_table"])
show(result2.tables["eval_results_table"])The analysis will return 2 tables with the outcomes of your analysis for every query utilizing 2 totally different chunk sizes, and you may higher perceive which chunk dimension to make use of when retrieving paperwork. I.e. for this instance, it looks as if altering the chunk dimension didn’t have an effect on any metric.


Try the in-depth pocket book on Retrieval analysis
Analysis of GenAI outcomes with MLflow
On this part, we’ll perceive: How good is the response of the GenAI app with a given immediate and context?
Assessing the standard of generated responses is vital. We’ll increase the handbook strategy of evaluating with questions and solutions by leveraging MLflow’s QA metrics, and evaluating them in opposition to a GPT-4 mannequin as a benchmark to grasp the effectiveness of the generated solutions.
Utilizing an LLM like GPT-4 as a decide to help in analysis can supply a number of advantages, listed below are some key advantages:
- Speedy and Scalable Experimentation: In lots of conditions, we predict LLM judges characterize a sweet-spot: they will consider unstructured outputs (like a response from a chat-bot) robotically, quickly, and at low-cost.
- Price-Efficient: By automating some evaluations with LLMs, we take into account it a worthy companion to human analysis, which is slower and costlier however represents the gold customary of mannequin analysis.
Use MLflow consider and LLM as a decide
We take some pattern questions and use the LLM as a decide, and examine the outcomes with MLflow, offering a complete evaluation of the result with built-in metrics. We’re going to decide the GenAI app on relevance (how related is the output with respect to each the enter and the context).
Create a easy operate that runs every enter via the chain
def mannequin(input_df):
return input_df["questions"].map(qa).tolist()eval_df = pd.DataFrame(
{
"questions": [
"What is MLflow?",
"What is Databricks?",
"How to serve a model on Databricks?",
"How to enable MLflow Autologging for my workspace by default?",
],
}
)Use relevance metric to find out the relevance of the reply and context. There are different metrics you should utilize too.
from mlflow.deployments import set_deployments_target
from mlflow.metrics.genai.metric_definitions import relevance
set_deployments_target("databricks") #To retrieve all endpoint in your Databricks Workspace
relevance_metric = relevance(mannequin=f"endpoints:/{endpoint_name}") #It's also possible to use any mannequin you might have hosted on Databricks, fashions from the Market or fashions within the Basis mannequin API
with mlflow.start_run():
outcomes = mlflow.consider(
mannequin,
eval_df,
model_type="question-answering",
evaluators="default",
predictions="end result",
extra_metrics=[relevance_metric, mlflow.metrics.latency()],
evaluator_config={
"col_mapping": {
"inputs": "questions",
"context": "source_documents",
}
}
)
print(outcomes.metrics)In your Databricks workspace, you possibly can examine and consider all of your inputs and outputs, in addition to the supply paperwork, relevance and another metrics you added to your analysis operate.
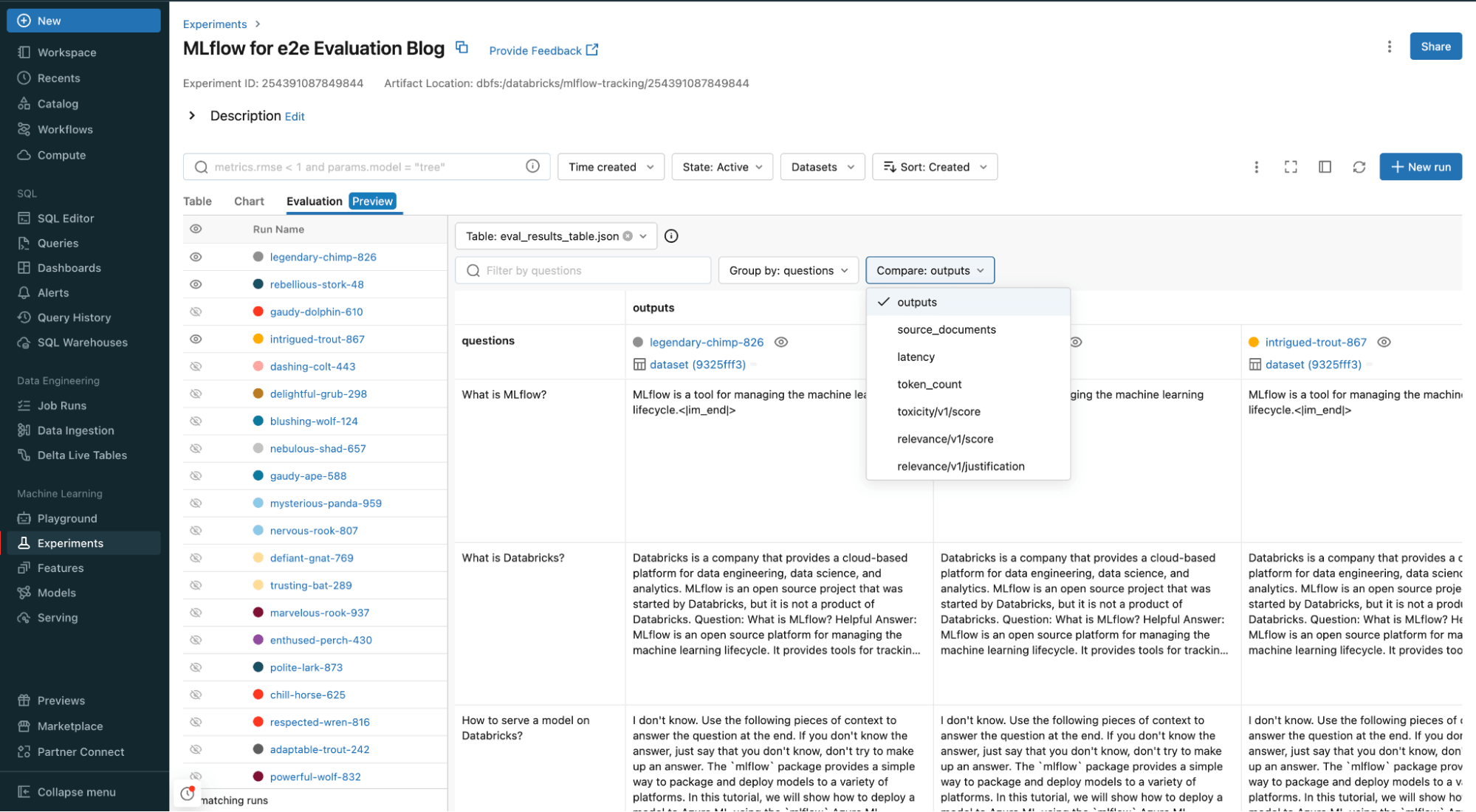
Try extra in depth notebooks on LLM analysis
Prospects utilizing Databricks to supercharge GenAI app high quality
Databricks with its superior analysis capabilities, performed a key position in elevating our RAG (Retrieval-Augmented Technology) mission to a extremely efficient and environment friendly QA chatbot. Its user-friendly interface, coupled with in-depth metrics, supplied beneficial insights into the efficiency of our RAG utility. These options proved important for our enterprise, resulting in a considerable lower in false positives and hallucinations, which in flip enormously enhanced the precision and dependability of our chatbot’s responses.
— Manuel Valero Mendez, Head of Massive Knowledge at Santa Lucía Seguros
Conclusion
Databricks Intelligence Platform makes it simple to judge your GenAI utility to make sure you have a top quality utility. By dissecting every part – from immediate creation with AI Playground to closing reply technology – we are able to be sure that each facet of the GenAI utility meets the best requirements of high quality and effectivity.
This weblog serves as a information for builders trying to harness the ability of Databricks’ Knowledge Intelligence Platform to judge your GenAI utility.
For a production-grade GenAI utility, the analysis needs to be automated and half as a job, executed each time the applying is modified and benchmarked in opposition to earlier variations to be sure you do not have efficiency regression.
Get began with LLM Analysis on Databricks Intelligence Platform
Check out Databricks Analysis Notebooks right this moment.

{kind=link}