

Amazon EMR gives a managed Apache Hadoop framework that makes it simple, quick, and cost-effective to run Apache HBase. Apache HBase is a massively scalable, distributed massive knowledge retailer within the Apache Hadoop ecosystem. It’s an open-source, non-relational, versioned database that runs on high of the Apache Hadoop Distributed File System (HDFS). It’s constructed for random, strictly constant, real-time entry for tables with billions of rows and thousands and thousands of columns. Monitoring HBase clusters is vital in an effort to determine stability and efficiency bottlenecks and proactively preempt them. On this put up, we focus on how you should use Amazon Managed Service for Prometheus and Amazon Managed Grafana to watch, alert, and visualize HBase metrics.
HBase has built-in help for exporting metrics by way of the Hadoop metrics subsystem to recordsdata or Ganglia or by way of JMX. You may both use AWS Distro for OpenTelemetry or Prometheus JMX exporters to gather metrics uncovered by HBase. On this put up, we present the way to use Prometheus exporters. These exporters behave like small webservers that convert inside software metrics to Prometheus format and serve it at /metrics path. A Prometheus server operating on an Amazon Elastic Compute Cloud (Amazon EC2) occasion collects these metrics and distant writes to an Amazon Managed Service for Prometheus workspace. We then use Amazon Managed Grafana to create dashboards and consider these metrics utilizing an Amazon Managed Service for Prometheus workspace as its knowledge supply.
This resolution could be prolonged to different massive knowledge platforms similar to Apache Spark and Apache Presto that additionally use JMX to reveal their metrics.
Resolution overview
The next diagram illustrates our resolution structure.
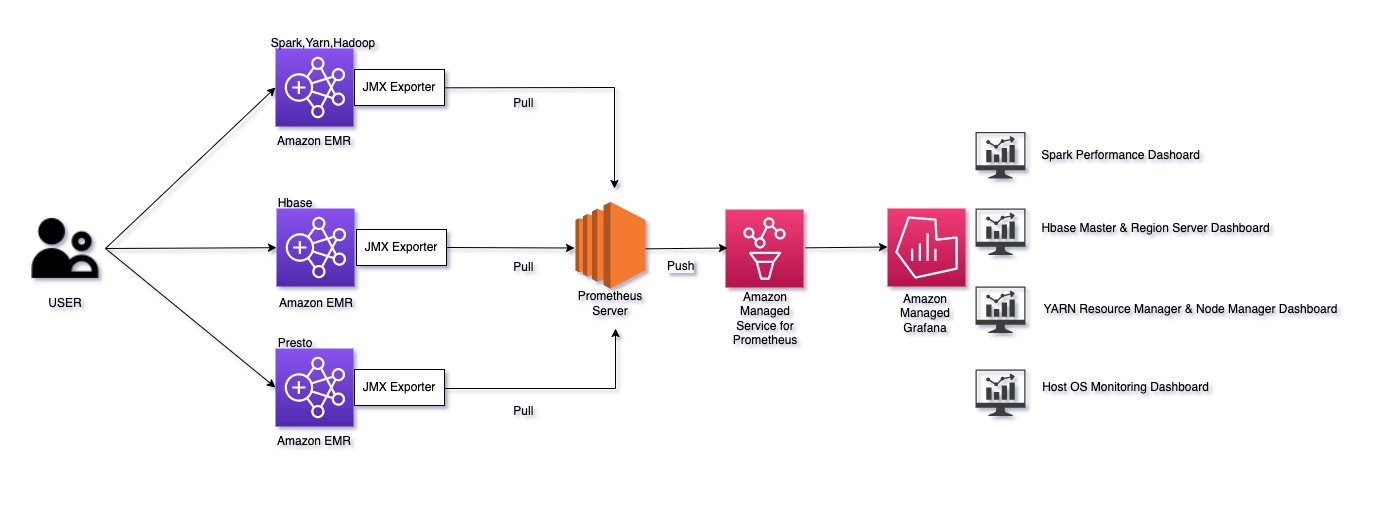
This put up makes use of an AWS CloudFormation template to carry out beneath actions:
- Set up an open-source Prometheus server on an EC2 occasion.
- Create acceptable AWS Identification and Entry Administration (IAM) roles and safety group for the EC2 occasion operating the Prometheus server.
- Create an EMR cluster with an HBase on Amazon S3 configuration.
- Set up JMX exporters on all EMR nodes.
- Create further safety teams for the EMR grasp and employee nodes to attach with the Prometheus server operating on the EC2 occasion.
- Create a workspace in Amazon Managed Service for Prometheus.
Stipulations
To implement this resolution, be sure to have the next stipulations:
Deploy the CloudFormation template
Deploy the CloudFormation template within the us-east-1 Area:
![]()
It would take 15–20 minutes for the template to finish. The template requires the next fields:
- Stack Identify – Enter a reputation for the stack
- VPC – Select an current VPC
- Subnet – Select an current subnet
- EMRClusterName – Use
EMRHBase - HBaseRootDir – Present a brand new HBase root listing (for instance,
s3://hbase-root-dir/). - MasterInstanceType – Use m5x.massive
- CoreInstanceType – Use m5x.massive
- CoreInstanceCount – Enter 2
- SSHIPRange – Use
<your ip deal with>/32(you possibly can go to https://checkip.amazonaws.com/ to examine your IP deal with) - EMRKeyName – Select a key pair for the EMR cluster
- EMRRleaseLabel – Use
emr-6.9.0 - InstanceType – Use the EC2 occasion kind for putting in the Prometheus server

Allow distant writes on the Prometheus server
The Prometheus server is operating on an EC2 occasion. You will discover the occasion hostname within the CloudFormation stack’s Outputs tab for key PrometheusServerPublicDNSName.
- SSH into the EC2 occasion utilizing the important thing pair:
- Copy the worth for Endpoint – distant write URL from the Amazon Managed Service for Prometheus workspace console.

- Edit
remote_write urlin/and many others/prometheus/conf/prometheus.yml:
It ought to appear to be the next code:

- Now we have to restart the Prometheus server to choose up the adjustments:
Allow Amazon Managed Grafana to learn from an Amazon Managed Service for Prometheus workspace
We have to add the Amazon Managed Prometheus workspace as an information supply in Amazon Managed Grafana. You may skip on to step 3 if you have already got an current Amazon Managed Grafana workspace and wish to use it for HBase metrics.
- First, let’s create a workspace on Amazon Managed Grafana. You may comply with the appendix to create a workspace utilizing the Amazon Managed Grafana console or run the next API out of your terminal (present your function ARN):
- On the Amazon Managed Grafana console, select Configure customers and choose a consumer you wish to enable to log in to Grafana dashboards.
Make certain your IAM Identification Middle consumer kind is admin. We’d like this to create dashboards. You may assign the viewer function to all the opposite customers.


- Log in to the Amazon Managed Grafana workspace URL utilizing your admin credentials.
- Select AWS Information Sources within the navigation pane.

- For Service, select Amazon Managed Service for Prometheus.

- For Areas, select US East (N. Virginia).
Create an HBase dashboard
Grafana labs has an open-source dashboard that you should use. For instance, you possibly can comply with the steering from the next HBase dashboard. Begin creating your dashboard and selected the import possibility. Present the URL of the dashboard or enter 12722 and select Load. Make certain your Prometheus workspace is chosen on the subsequent web page. You must see HBase metrics exhibiting up on the dashboard.

Key HBase metrics to watch
HBase has a variety of metrics for HMaster and RegionServer. The next are just a few vital metrics to bear in mind.
| HMASTER | Metric Identify | Metric Description |
| . | hadoop_HBase_numregionservers | Variety of reside area servers |
| . | hadoop_HBase_numdeadregionservers | Variety of lifeless area servers |
| . | hadoop_HBase_ritcount | Variety of areas in transition |
| . | hadoop_HBase_ritcountoverthreshold | Variety of areas which have been in transition longer than a threshold time (default: 60 seconds) |
| . | hadoop_HBase_ritduration_99th_percentile | Most time taken by 99% of the areas to stay in transition state |
| REGIONSERVER | Metric Identify | Metric Description |
| . | hadoop_HBase_regioncount | Variety of areas hosted by the area server |
| . | hadoop_HBase_storefilecount | Variety of retailer recordsdata at present managed by the area server |
| . | hadoop_HBase_storefilesize | Combination dimension of the shop recordsdata |
| . | hadoop_HBase_hlogfilecount | Variety of write-ahead logs not but archived |
| . | hadoop_HBase_hlogfilesize | Dimension of all write-ahead log recordsdata |
| . | hadoop_HBase_totalrequestcount | Complete variety of requests acquired |
| . | hadoop_HBase_readrequestcount | Variety of learn requests acquired |
| . | hadoop_HBase_writerequestcount | Variety of write requests acquired |
| . | hadoop_HBase_numopenconnections | Variety of open connections on the RPC layer |
| . | hadoop_HBase_numactivehandler | Variety of RPC handlers actively servicing requests |
| Memstore | . | . |
| . | hadoop_HBase_memstoresize | Complete memstore reminiscence dimension of the area server |
| . | hadoop_HBase_flushqueuelength | Present depth of the memstore flush queue (if rising, we’re falling behind with clearing memstores out to Amazon S3) |
| . | hadoop_HBase_flushtime_99th_percentile | 99th percentile latency for flush operation |
| . | hadoop_HBase_updatesblockedtime | Variety of milliseconds updates have been blocked so the memstore could be flushed |
| Block Cache | . | . |
| . | hadoop_HBase_blockcachesize | Block cache dimension |
| . | hadoop_HBase_blockcachefreesize | Block cache free dimension |
| . | hadoop_HBase_blockcachehitcount | Variety of block cache hits |
| . | hadoop_HBase_blockcachemisscount | Variety of block cache misses |
| . | hadoop_HBase_blockcacheexpresshitpercent | Share of the time that requests with the cache turned on hit the cache |
| . | hadoop_HBase_blockcachecounthitpercent | Share of block cache hits |
| . | hadoop_HBase_blockcacheevictioncount | Variety of block cache evictions within the area server |
| . | hadoop_HBase_l2cachehitratio | Native disk-based bucket cache hit ratio |
| . | hadoop_HBase_l2cachemissratio | Bucket cache miss ratio |
| Compaction | . | . |
| . | hadoop_HBase_majorcompactiontime_99th_percentile | Time in milliseconds taken for main compaction |
| . | hadoop_HBase_compactiontime_99th_percentile | Time in milliseconds taken for minor compaction |
| . | hadoop_HBase_compactionqueuelength | Present depth of the compaction request queue (if rising, we’re falling behind with storefile compaction) |
| . | flush queue size | Variety of flush operations ready to be processed within the area server (a better quantity signifies flush operations are gradual) |
| IPC Queues | . | . |
| . | hadoop_HBase_queuesize | Complete knowledge dimension of all RPC calls within the RPC queues within the area server |
| . | hadoop_HBase_numcallsingeneralqueue | Variety of RPC calls within the basic processing queue within the area server |
| . | hadoop_HBase_processcalltime_99th_percentile | 99th percentile latency for RPC calls to be processed within the area server |
| . | hadoop_HBase_queuecalltime_99th_percentile | 99th percentile latency for RPC calls to remain within the RPC queue within the area server |
| JVM and GC | . | . |
| . | hadoop_HBase_memheapusedm | Heap used |
| . | hadoop_HBase_memheapmaxm | Complete heap |
| . | hadoop_HBase_pausetimewithgc_99th_percentile | Pause time in milliseconds |
| . | hadoop_HBase_gccount | Rubbish assortment depend |
| . | hadoop_HBase_gctimemillis | Time spent in rubbish assortment, in milliseconds |
| Latencies | . | . |
| . | HBase.regionserver.<op>_<measure> | Operation latencies, the place <op> is Append, Delete, Mutate, Get, Replay, or Increment, and <measure> is min, max, imply, median, 75th_percentile, 95th_percentile, or 99th_percentile |
| . | HBase.regionserver.gradual<op>Depend | Variety of operations we thought have been gradual, the place <op> is likely one of the previous listing |
| Bulk Load | . | . |
| . | Bulkload_99th_percentile | hadoop_HBase_bulkload_99th_percentile |
| I/O | . | . |
| . | FsWriteTime_99th_percentile | hadoop_HBase_fswritetime_99th_percentile |
| . | FsReadTime_99th_percentile | hadoop_HBase_fsreadtime_99th_percentile |
| Exceptions | . | . |
| . | exceptions.RegionTooBusyException | . |
| . | exceptions.callQueueTooBig | . |
| . | exceptions.NotServingRegionException | . |
Concerns and limitations
Word the next when utilizing this resolution:
- You may arrange alerts on Amazon Managed Service for Prometheus and visualize them in Amazon Managed Grafana.
- This structure could be simply prolonged to incorporate different open-source frameworks similar to Apache Spark, Apache Presto, and Apache Hive.
- Confer with the pricing particulars for Amazon Managed Service for Prometheus and Amazon Managed Grafana.
- These scripts are for steering functions solely and aren’t prepared for manufacturing deployments. Make certain to carry out thorough testing.
Clear up
To keep away from ongoing costs, delete the CloudFormation stack and workspaces created in Amazon Managed Grafana and Amazon Managed Service for Prometheus.
Conclusion
On this put up, you realized the way to monitor EMR HBase clusters and arrange dashboards to visualise key metrics. This resolution can function a unified monitoring platform for a number of EMR clusters and different functions. For extra info on EMR HBase, see Launch Information and HBase Migration whitepaper.
Appendix
Full the next steps to create a workspace on Amazon Managed Grafana:
- Log in to the Amazon Managed Grafana console and select Create workspace.

- For Authentication entry, choose AWS IAM Identification Middle.
When you don’t have IAM Identification Middle enabled, consult with Allow IAM Identification Middle.
- Optionally, to view Prometheus alerts in your Grafana workspace, choose Flip Grafana alerting on.

- On the subsequent web page, choose Amazon Managed Service for Prometheus as the info supply.

- After the workspace is created, assign customers to entry Amazon Managed Grafana.
- For a first-time setup, assign admin privileges to the consumer.
You may add different customers with solely viewer entry.
Make certain you’ll be able to log in to the Grafana workspace URL utilizing your IAM Identification Middle consumer credentials.
In regards to the Creator
 Anubhav Awasthi is a Sr. Massive Information Specialist Options Architect at AWS. He works with clients to offer architectural steering for operating analytics options on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Anubhav Awasthi is a Sr. Massive Information Specialist Options Architect at AWS. He works with clients to offer architectural steering for operating analytics options on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.

{kind=link}