

There are a number of change knowledge seize strategies obtainable when utilizing a MySQL or Postgres database. A few of these strategies overlap and are very related no matter which database expertise you might be utilizing, others are totally different. Finally, we require a strategy to specify and detect what has modified and a technique of sending these modifications to a goal system.
This put up assumes you might be aware of change knowledge seize, if not learn the earlier introductory put up right here “Change Information Seize: What It Is and How To Use It.” On this put up, we’re going to dive deeper into the alternative ways you may implement CDC when you’ve got both a MySQL and Postgres database and examine the approaches.
CDC with Replace Timestamps and Kafka
One of many easiest methods to implement a CDC resolution in each MySQL and Postgres is through the use of replace timestamps. Any time a report is inserted or modified, the replace timestamp is up to date to the present date and time and allows you to know when that report was final modified.
We will then both construct bespoke options to ballot the database for any new data and write them to a goal system or a CSV file to be processed later. Or we will use a pre-built resolution like Kafka and Kafka Join that has pre-defined connectors that ballot tables and publish rows to a queue when the replace timestamp is larger than the final processed report. Kafka Join additionally has connectors to focus on techniques that may then write these data for you.
Fetching the Updates and Publishing them to the Goal Database utilizing Kafka
Kafka is an occasion streaming platform that follows a pub-sub mannequin. Publishers ship knowledge to a queue and a number of shoppers can then learn messages from that queue. If we wished to seize modifications from a MySQL or Postgres database and ship them to an information warehouse or analytics platform, we first must arrange a writer to ship the modifications after which a shopper that would learn the modifications and apply them to our goal system.
To simplify this course of we will use Kafka Join. Kafka Join works as a center man with pre-built connectors to each publish and devour knowledge that may merely be configured with a config file.
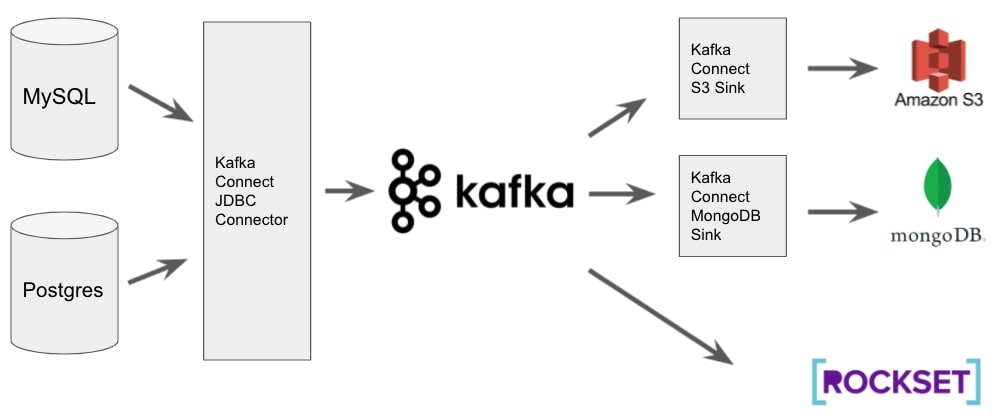
Fig 1. CDC structure with MySQL, Postgres and Kafka
As proven in Fig 1, we will configure a JDBC connector for Kafka Join that specifies which desk we want to devour, how you can detect modifications which in our case might be through the use of the replace timestamp and which matter (queue) to publish them to. Utilizing Kafka Connect with deal with this implies the entire logic required to detect which rows have modified is finished for us. We solely want to make sure that the replace timestamp subject is up to date (coated within the subsequent part) and Kafka Join will handle:
- Maintaining observe of the utmost replace timestamp of the most recent report it has revealed
- Polling the database for any data with newer replace timestamp fields
- Writing the info to a queue to be consumed downstream
We will then both configure “sinks” which outline the place to output the info or have the supply system speak to Kafka straight. Once more, Kafka Join has many pre-defined sink connectors that we will simply configure to output the info to many various goal techniques. Providers like Rockset can speak to Kafka straight and due to this fact don’t require a sink to be configured.
Once more, utilizing Kafka Join signifies that out of the field, not solely can we write knowledge to many various places with little or no coding required, however we additionally get Kafkas throughput and fault tolerance that can assist us scale our resolution sooner or later.
For this to work, we have to make sure that now we have replace timestamp fields on the tables we need to seize and that these fields are at all times up to date every time the report is up to date. Within the subsequent part, we cowl how you can implement this in each MySQL and Postgres.
Utilizing Triggers for Replace Timestamps (MySQL & Postgres)
MySQL and Postgres each assist triggers. Triggers permit you to carry out actions within the database both instantly earlier than or after one other motion occurs. For this instance, every time an replace command is detected to a row in our supply desk, we need to set off one other replace on the affected row which units the replace timestamp to the present date and time.
We solely need the set off to run on an replace command as in each MySQL and Postgres you may set the replace timestamp column to robotically use the present date and time when a brand new report is inserted. The desk definition in MySQL would look as follows (the Postgres syntax can be very related). Be aware the DEFAULT CURRENTTIMESTAMP key phrases when declaring the replacetimestamp column that ensures when a report is inserted, by default the present date and time are used.
CREATE TABLE consumer
(
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
e-mail VARCHAR(50),
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
This may imply our update_timestamp column will get set to the present date and time for any new data, now we have to outline a set off that can replace this subject every time a report is up to date within the consumer desk. The MySQL implementation is straightforward and appears as follows.
DELIMITER $$
CREATE TRIGGER user_update_timestamp
BEFORE UPDATE ON consumer
FOR EACH ROW BEGIN
SET NEW.update_timestamp = CURRENT_TIMESTAMP;
END$$
DELIMITER ;
For Postgres, you first should outline a operate that can set the update_timestamp subject to the present timestamp after which the set off will execute the operate. It is a refined distinction however is barely extra overhead as you now have a operate and a set off to keep up within the postgres database.
Utilizing Auto-Replace Syntax in MySQL
If you’re utilizing MySQL there may be one other, a lot less complicated approach of implementing an replace timestamp. When defining the desk in MySQL you may outline what worth to set a column to when the report is up to date, which in our case can be to replace it to the present timestamp.
CREATE TABLE consumer
(
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
e-mail VARCHAR(50),
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
The good thing about that is that we now not have to keep up the set off code (or the operate code within the case of Postgres).
CDC with Debezium, Kafka and Amazon DMS
Another choice for implementing a CDC resolution is through the use of the native database logs that each MySQL and Postgres can produce when configured to take action. These database logs report each operation that’s executed in opposition to the database which may then be used to duplicate these modifications in a goal system.
The benefit of utilizing database logs is that firstly, you don’t want to write down any code or add any additional logic to your tables as you do with replace timestamps. Second, it additionally helps deletion of data, one thing that isn’t potential with replace timestamps.
In MySQL you do that by turning on the binlog and in Postgres, you configure the Write Forward Log (WAL) for replication. As soon as the database is configured to write down these logs you may select a CDC system to assist seize the modifications. Two widespread choices are Debezium and Amazon Database Migration Service (DMS). Each of those techniques utilise the binlog for MySQL and WAL for Postgres.
Debezium works natively with Kafka. It picks up the related modifications, converts them right into a JSON object that comprises a payload describing what has modified and the schema of the desk and places it on a Kafka matter. This payload comprises all of the context required to use these modifications to our goal system, we simply want to write down a shopper or use a Kafka Join sink to write down the info. As Debezium makes use of Kafka, we get all the advantages of Kafka reminiscent of fault tolerance and scalability.
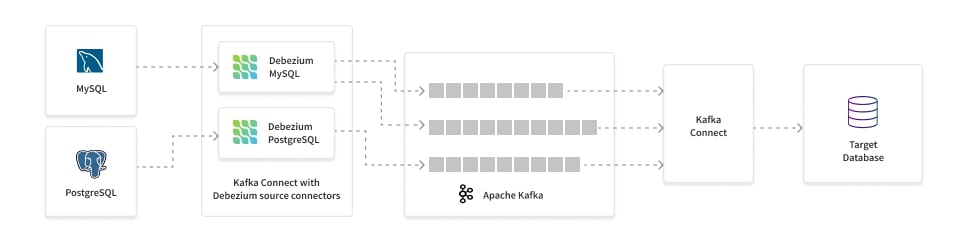
Fig 2. Debezium CDC structure for MySQL and Postgres
AWS DMS works in an analogous strategy to Debezium. It helps many various supply and goal techniques and integrates natively with the entire widespread AWS knowledge providers together with Kinesis and Redshift.
The principle good thing about utilizing DMS over Debezium is that it is successfully a “serverless” providing. With Debezium, in order for you the flexibleness and fault tolerance of Kafka, you have got the overhead of deploying a Kafka cluster. DMS as its identify states is a service. You configure the supply and goal endpoints and AWS takes care of dealing with the infrastructure to cope with monitoring the database logs and copying the info to the goal.
Nonetheless, this serverless strategy does have its drawbacks, primarily in its characteristic set.
Which Possibility for CDC?
When weighing up which sample to observe it’s vital to evaluate your particular use case. Utilizing replace timestamps works if you solely need to seize inserts and updates, if you have already got a Kafka cluster you may rise up and operating with this in a short time, particularly if most tables already embody some form of replace timestamp.
When you’d slightly go together with the database log strategy, possibly since you need precise replication then you must look to make use of a service like Debezium or AWS DMS. I might counsel first checking which system helps the supply and goal techniques you require. If in case you have some extra superior use circumstances reminiscent of masking delicate knowledge or re-routing knowledge to totally different queues based mostly on its content material then Debezium might be the only option. When you’re simply on the lookout for easy replication with little overhead then DMS will give you the results you want if it helps your supply and goal system.
If in case you have real-time analytics wants, chances are you’ll think about using a goal database like Rockset as an analytics serving layer. Rockset integrates with MySQL and Postgres, utilizing AWS DMS, to ingest CDC streams and index the info for sub-second analytics at scale. Rockset may learn CDC streams from NoSQL databases, reminiscent of MongoDB and Amazon DynamoDB.
The fitting reply relies on your particular use case and there are various extra choices than have been mentioned right here, these are simply a number of the extra widespread methods to implement a contemporary CDC system.
Lewis Gavin has been an information engineer for 5 years and has additionally been running a blog about abilities inside the Information neighborhood for 4 years on a private weblog and Medium. Throughout his laptop science diploma, he labored for the Airbus Helicopter staff in Munich enhancing simulator software program for army helicopters. He then went on to work for Capgemini the place he helped the UK authorities transfer into the world of Huge Information. He’s at the moment utilizing this expertise to assist remodel the info panorama at easyfundraising.org.uk, a web based charity cashback web site, the place he’s serving to to form their knowledge warehousing and reporting functionality from the bottom up.

{kind=link}