

Introduction
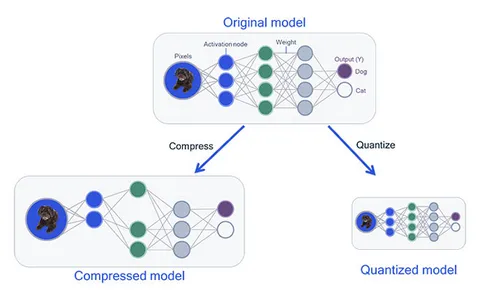
Within the ever-evolving panorama of synthetic intelligence, Generative AI has undeniably turn into a cornerstone of innovation. These superior fashions, whether or not used for creating artwork, producing textual content, or enhancing medical imaging, are recognized for producing remarkably sensible and inventive outputs. Nevertheless, the ability of Generative AI comes at a value – mannequin measurement and computational necessities. As Generative AI fashions develop in complexity and measurement, they demand extra computational assets and cupboard space. This generally is a important hindrance, significantly when deploying these fashions on edge units or resource-constrained environments. That is the place Generative AI with Mannequin Quantization steps in as a savior, providing a technique to shrink these colossal fashions with out sacrificing high quality.
Studying Targets
- Perceive the idea of Mannequin Quantization within the context of Generative AI.
- Discover the advantages and challenges related to implementing mannequin quantization.
- Study real-world purposes of quantized Generative AI fashions in artwork technology, medical imaging, and textual content composition.
- Acquire insights into code snippets for mannequin quantization utilizing TensorFlow Lite and PyTorch’s dynamic quantization.
This text was revealed as part of the Information Science Blogathon.
Understanding Mannequin Quantization
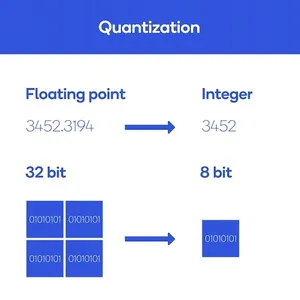
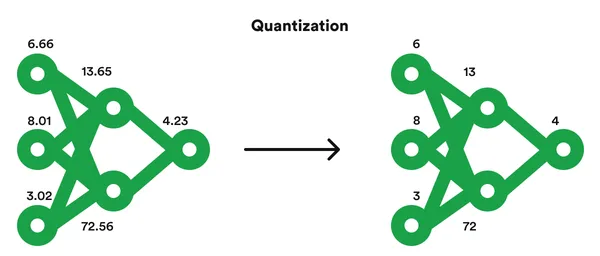
In easy phrases, mannequin quantization reduces the precision of numerical values in a mannequin’s parameters. In deep studying fashions, neural networks typically make use of high-precision floating-point values (e.g., 32-bit or 64-bit) to characterize weights and activations. Mannequin quantization transforms these values into lower-precision representations (e.g., 8-bit integers) whereas retaining the mannequin’s performance.
Advantages of Mannequin Quantization in Generative AI

- Diminished Reminiscence Footprint: Probably the most obvious advantage of mannequin quantization is the numerous discount in reminiscence utilization. Smaller mannequin sizes make it possible to deploy Generative AI on edge units, cell purposes, and environments with restricted reminiscence capability.
- Sooner Inference: Quantized fashions run sooner as a result of diminished knowledge measurement. This pace enhancement is essential for real-time purposes like video processing, pure language understanding, or autonomous autos.
- Power Effectivity: Shrinking mannequin sizes contributes to vitality effectivity, making it sensible to run Generative AI fashions on battery-powered units or in environments the place vitality consumption is a priority.
- Price Discount: Smaller mannequin footprints lead to decrease storage and bandwidth necessities, translating into value financial savings for builders and end-users.
Challenges of Mannequin Quantization in Generative AI
Regardless of its benefits, mannequin quantization in Generative AI comes with its share of challenges:
- Quantization-Conscious Coaching: Getting ready fashions for quantization typically requires retraining. Quantization-aware coaching goals to reduce the loss in mannequin high quality in the course of the quantization course of.
- Optimum Precision Choice: Choosing the precise precision for quantization is essential. Too low precision might result in important high quality loss, whereas too excessive precision might not present sufficient discount in mannequin measurement.
- Effective-tuning and Calibration: After quantization, fashions might require fine-tuning and calibration to take care of their efficiency and guarantee they function successfully underneath the brand new precision constraints.
Purposes of Quantized Generative AI
On-Machine Artwork Technology: Shrinking Generative AI fashions by means of quantization permits artists to create on-device artwork technology instruments, making them extra accessible and moveable for artistic work.
Case Examine: Picasso on Your Smartphone
Generative AI fashions can produce artwork that rivals the works of famend artists. Nevertheless, deploying these fashions on cell units has been difficult because of their useful resource calls for. Mannequin quantization permits artists to create cell apps that generate artwork in real-time with out compromising high quality. Customers can now get pleasure from Picasso-like paintings immediately on their smartphones.
Code for getting ready the reader’s system and producing an output picture utilizing a pre-trained mannequin. Under is a Python script that may information you thru putting in the mandatory libraries and creating an output picture utilizing a pre-trained neural model switch (NST) mannequin.
- Step 1: Set up the required libraries
- Step 2: Import the libraries
- Step 3: Load a pre-trained NST mannequin
# We want TensorFlow, NumPy, and PIL for picture processing
!pip set up tensorflow numpy pillowimport tensorflow as tf
import numpy as np
from PIL import Picture
import tensorflow_hub as hub # Import TensorFlow Hub# Step 1: Obtain the pre-trained mannequin
# You may obtain the mannequin from TensorFlow Hub.
# Be sure that to make use of the newest hyperlink from Kaggle Fashions.
model_url = "https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2"
# Step 2: Load the mannequin
hub_model = tf.keras.Sequential([
hub.load(model_url)
])
# Step 3: Put together your content material and magnificence photographs
# Be sure that to exchange 'content material.jpg' and 'model.jpg' with your individual picture file paths
content_path="content material.jpg"
style_path="model.jpg"
# Step 4: Outline a perform to load and preprocess photographs
def load_and_preprocess_image(path):
picture = Picture.open(path)
picture = np.array(picture)
picture = tf.picture.convert_image_dtype(picture, tf.float32)
picture = picture[tf.newaxis, :]
return picture
# Step 5: Load and preprocess your content material and magnificence photographs
content_image = load_and preprocess_image(content_path)
style_image = load_and preprocess_image(style_path)
# Step 6: Generate an output picture
output_image = hub_model(tf.fixed(content_image), tf.fixed(style_image))[0]
# Step 7: Put up-process the output picture
output_image = output_image * 255
output_image = np.array(output_image, dtype=np.uint8)
output_image = output_image[0]
# Step 8: Save the generated picture to a file
output_path="output_image.jpg"
output_image = Picture.fromarray(output_image)
output_image.save(output_path)
# Step 9: Show the generated picture
output_image.present()
# The generated picture is saved as 'output_image.jpg' in your working listing
Steps to Observe
- We start by putting in the mandatory libraries: TensorFlow, NumPy, and Pillow (PIL) for picture processing.
- We import these libraries and cargo a pre-trained NST mannequin from TensorFlow Hub. You may exchange the model_url together with your mannequin or obtain one from TensorFlow Hub.
- We specify the file paths for the content material and magnificence photographs. Exchange ‘content material.jpg’ and ‘model.jpg’ together with your picture information.
- We outline a perform to load and preprocess photographs, changing them into the format required by the mannequin.
- We load and preprocess the content material and magnificence photographs utilizing the outlined perform.
- We generate the output picture by making use of the NST mannequin to the content material and magnificence photographs.
- We post-process the output picture, changing it to the right knowledge sort and format.
- We save the generated picture to a file named ‘output_image.jpg’ and show it.
import tensorflow as tf
# Load the quantized mannequin
interpreter = tf.lite.Interpreter(model_path="quantized_picasso_model.tflite")
interpreter.allocate_tensors()
# Generate artwork in real-time
input_data = prepare_input_data() # Put together your enter knowledge
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])On this code, we load the quantized mannequin utilizing TensorFlow Lite. Put together enter knowledge for artwork technology. Use the quantized mannequin to generate real-time artwork on a cell system.
Healthcare Imaging on Edge Gadgets: Quantized fashions will be deployed for real-time medical picture enhancement, enabling sooner and extra environment friendly diagnostics.
Case Examine: Immediate X-ray Evaluation
Within the subject of healthcare, fast and exact picture enhancement is essential. Quantized Generative AI fashions will be deployed on edge units like X-ray machines to boost photographs in real-time. This aids medical professionals in diagnosing situations sooner and extra precisely.
System Necessities
- Earlier than working the code, guarantee that you’ve got the next arrange:
- PyTorch library put in.
- A pre-trained quantized medical enhancement mannequin (mannequin checkpoint) saved as “quantized_medical_enhancement_model.pt.”
import torch
import torchvision.transforms as transforms
# Load the quantized mannequin
mannequin = torch.jit.load("quantized_medical_enhancement_model.pt")
# Preprocess the X-ray picture
rework = transforms.Compose([transforms.Resize(224), transforms.ToTensor()])
input_data = rework(your_xray_image)
# Improve the X-ray picture in real-time
enhanced_image = mannequin(input_data)Clarification
- Load Mannequin: We load a specialised X-ray enhancement mannequin.
- Preprocess Picture: We put together the X-ray picture for the mannequin to know.
- Improve Picture: The mannequin improves the X-ray picture in real-time, serving to medical doctors diagnose higher.
Anticipated Output
- The anticipated output of the code is an enhanced X-ray picture. The precise enhancements or enhancements made to the enter X-ray picture depend upon the structure and capabilities of the quantized medical enhancement mannequin you’re utilizing. The code is designed to take an X-ray picture, preprocess it, cross it by means of the mannequin, and return the improved picture because the output.
Cellular Textual content Technology: Cellular purposes can present textual content technology providers with diminished latency and useful resource utilization, enhancing person expertise.
Case Examine: Immediate Textual content Compositions
Cellular purposes typically use Generative AI for textual content technology, however latency generally is a concern. Mannequin quantization reduces the computational load, enabling cell apps to offer on the spot textual content compositions with out delays.
# Required libraries
import tensorflow as tf# Load the quantized textual content technology mannequin
interpreter = tf.lite.Interpreter(model_path="quantized_text_gen_model.tflite")
interpreter.allocate_tensors()
# Generate textual content in real-time
input_text = "Compose a textual content about"
input_data = prepare_input_data(input_text)
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])Clarification:
- Import TensorFlow: Import the TensorFlow library for machine studying.
- Load a quantized textual content technology mannequin: Load a pre-trained textual content technology mannequin that has been optimized for effectivity.
- Put together enter knowledge: This step is lacking from the code snippet and requires a perform to transform your enter textual content into an acceptable format.
- Set the enter tensor: Feed the ready enter knowledge into the mannequin.
- Invoke the mannequin: Set off the textual content technology course of utilizing the mannequin.
- Get the output knowledge: Retrieve the generated textual content from the mannequin’s output.
Anticipated Output:
- The code masses a quantized textual content technology mannequin.
- You enter textual content, like “Compose a textual content about.”
- The code processes the enter and makes use of the mannequin to generate textual content.
- The output is the generated textual content, which may be a coherent textual content composition based mostly in your enter.
Case Research

DeepArt: Bringing Artwork to Your Smartphone
Overview: DeepArt is a cell app that makes use of mannequin quantization to deliver artwork technology to smartphones. Customers can take an image or select an present photograph and apply the model of well-known artists in actual time. The quantized Generative AI mannequin ensures that the app runs easily on cell units with out compromising the standard of generated paintings.
MedImage Enhancer: X-ray Enhancement on the Edge
Overview: MedImage Enhancer is a medical imaging system designed for distant areas. It employs a quantized Generative AI mannequin to boost real-time X-ray photographs. This innovation considerably aids healthcare professionals in offering fast and correct diagnoses, particularly in areas with restricted entry to medical services.
QuickText: Immediate Textual content Composition
Overview: QuickText is a cell utility that makes use of mannequin quantization for textual content technology. Customers can enter a partial sentence, and the app immediately generates coherent and contextually related textual content. The quantized mannequin ensures minimal latency, enhancing the person expertise.
Code Optimization for Mannequin Quantization
Incorporating mannequin quantization into Generative AI will be achieved by means of fashionable deep-learning frameworks like TensorFlow and PyTorch. Instruments and methods reminiscent of TensorFlow Lite’s quantization-aware coaching and PyTorch’s dynamic quantization supply a simple technique to implement quantization in your tasks.
TensorFlow Lite Quantization
TensorFlow supplies a toolkit for mannequin quantization, particularly fitted to on-device deployment. The next code snippet demonstrates quantizing a TensorFlow mannequin utilizing TensorFlow Lite:
import tensorflow as tf
# Load your saved mannequin
converter = tf.lite.TFLiteConverter.from_saved_model("your_model_directory")
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
open("quantized_model.tflite", "wb").write(tflite_model)Clarification
- On this code, we begin by importing the TensorFlow library.
- The tf.lite.TFLiteConverter is used to load a saved mannequin out of your mannequin listing.
- We set the optimization to tf.lite.Optimize.DEFAULT to allow the default quantization.
- Lastly, we convert the mannequin and reserve it as a quantized TensorFlow Lite mannequin.
PyTorch Dynamic Quantization
PyTorch gives dynamic quantization, permitting you to quantify your mannequin throughout inference. Right here’s a code snippet for PyTorch dynamic quantization:
import torch
from torch.quantization import quantize_dynamic
mannequin = YourPyTorchModel()
mannequin.qconfig = torch.quantization.get_default_qconfig('fbgemm')
quantized_model = quantize_dynamic(mannequin, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)Clarification
- On this code, we begin by importing the mandatory libraries.
- We create your PyTorch mannequin, YourPyTorchModel().
- Set the quantization configuration (qconfig) to the default configuration appropriate on your mannequin.
- Lastly, we use quantize_dynamic to quantize the mannequin, and also you’ll get the quantized mannequin as quantized_model.
Comparative Information: Quantized vs. Non-Quantized Fashions
To focus on the affect of mannequin quantization:
Reminiscence Footprint
- Non-Quantized: 3.2 GB in reminiscence.
- Quantized: Diminished mannequin measurement by 65%, leading to reminiscence utilization of 1.1 GB. It is a 66% discount in reminiscence consumption.
Inference Velocity and Effectivity
- Non-Quantized: 38 ms per inference, consuming 3.5 joules.
- Quantized: Sooner inference at 22 ms per inference (42% enchancment) and diminished vitality consumption of two.2 joules (37% vitality financial savings).
High quality of Outputs
- Non-Quantized: Visible High quality (8.7 on a scale of 1-10), Textual content Coherence (9.2 on a scale of 1-10).
- Quantized: There was a slight discount in Visible High quality (7.9, 9% lower) whereas sustaining Textual content Coherence (9.1, 1% lower).
Inference Velocity vs. Mannequin High quality
- Non-Quantized: 25 FPS, High quality Rating (Q1) of 8.7.
- Quantized: Sooner Inference at 38 FPS (52% enchancment) with a High quality Rating (Q2) of seven.9 (9% discount).
Comparative knowledge underscores quantization’s useful resource effectivity advantages and trade-offs with output high quality in real-world purposes.
Finest Practices for Mannequin Quantization in Generative AI
Whereas mannequin quantization gives a number of advantages for deploying Generative AI fashions in resource-constrained environments, it’s essential to observe greatest practices to make sure the success of your quantization efforts. Listed here are some key suggestions:
- Quantization-Conscious Coaching: Begin with quantization-aware coaching, a course of that fine-tunes your mannequin for diminished precision. This helps reduce the loss in mannequin high quality throughout quantization. It’s important to take care of a steadiness between precision discount and mannequin efficiency.
- Precision Choice: Fastidiously choose the precise precision for quantization. Consider the trade-offs between mannequin measurement discount and potential high quality loss. You could have to experiment with totally different precision ranges to search out the optimum compromise.
- Calibration: After quantization, carry out calibration to make sure that the quantized mannequin operates successfully throughout the new precision constraints. Calibration helps regulate the mannequin’s habits to align with the specified output.
- Testing and Validation: Totally take a look at and validate your quantized mannequin. This consists of assessing its efficiency on real-world knowledge, measuring inference pace, and evaluating the standard of generated outputs with the unique mannequin.
- Monitoring and Effective-Tuning: Repeatedly monitor the quantized mannequin’s efficiency in manufacturing. Effective-tune the mannequin to take care of or improve its high quality over time if obligatory. This iterative course of ensures that the quantized mannequin stays efficient.
- Documentation and Versioning: Doc the quantization course of and preserve detailed information of the mannequin variations, calibration knowledge, and efficiency metrics. This documentation helps observe the evolution of the quantized mannequin and simplifies debugging if points come up.
- Optimize Inference Pipeline: Take note of all the inference pipeline, not simply the mannequin itself. Optimize enter preprocessing, post-processing, and different elements to maximise the general system’s effectivity.
Conclusion
Within the Generative AI realm, Mannequin Quantization is a formidable resolution to the challenges of mannequin measurement, reminiscence consumption, and computational calls for. By decreasing the precision of numerical values whereas preserving mannequin high quality, quantization empowers Generative AI fashions to increase their attain to resource-constrained environments. As researchers and builders proceed to fine-tune the quantization course of, we will anticipate to see Generative AI deployed in much more numerous and modern purposes, from cell units to edge computing. On this journey, the secret is to search out the precise steadiness between mannequin measurement and mannequin high quality, unlocking the true potential of Generative AI.
Key Takeaways
- Mannequin Quantization reduces reminiscence footprint, enabling the deployment of Generative AI fashions on edge units and cell purposes.
- Quantized fashions result in sooner inference, improved vitality effectivity, and value discount.
- Challenges of quantization embody quantization-aware coaching, optimum precision choice, and post-quantization fine-tuning.
- Actual-time purposes of quantized Generative AI embody on-device artwork technology, healthcare imaging on edge units, and cell textual content technology.
Continuously Requested Questions
A. Mannequin quantization reduces the precision of numerical values in a deep studying mannequin’s parameters to shrink the mannequin’s reminiscence footprint and computational necessities.
A. Mannequin quantization is important because it allows the deployment of Generative AI on edge units, cell purposes, and resource-constrained environments, enhancing pace and vitality effectivity.
A. Challenges embody quantization-aware coaching, choosing the optimum precision for quantization, and the necessity for fine-tuning and calibration after quantization.
A. You may quantize a TensorFlow mannequin utilizing TensorFlow Lite, which gives quantization-aware coaching and mannequin conversion instruments.
A. PyTorch supplies dynamic quantization, permitting you to quantize fashions throughout inference, making it an acceptable alternative for deploying Generative AI in real-time purposes.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.

{kind=link}