

Pulling again the curtain
One factor that makes Rockset so magical is the truth that it “simply works”. After years of fastidiously provisioning, managing, and tuning their knowledge programs, clients really feel that Rockset’s serverless providing is just too good to be true (we’ve heard this precise phrase from many purchasers!). We pleasure ourselves on having abstracted away the Rube Goldberg-like complexities inherent in sustaining indexes and ETL pipelines. Offering visibility into this complexity is a essential step to assist our customers get probably the most out of our product.
As our customers more and more depend on Rockset to energy their functions, the identical questions come up:
- How do I do know after I have to improve to a bigger Digital Occasion?
- Can I combine Rockset into my monitoring and alerting toolkit?
- How can I measure my knowledge and question latencies?
To assist reply these questions, we got down to present our customers every thing they might presumably wish to see, avoiding the overly difficult.
We needed to offer a 360 diploma overview for each customers within the extra exploratory, constructing section, in addition to these able to take Rockset into manufacturing. With this in thoughts, we constructed two new options:
- Monitoring and metrics instantly constructed into the Rockset Console
- The means to combine with current third-party monitoring providers
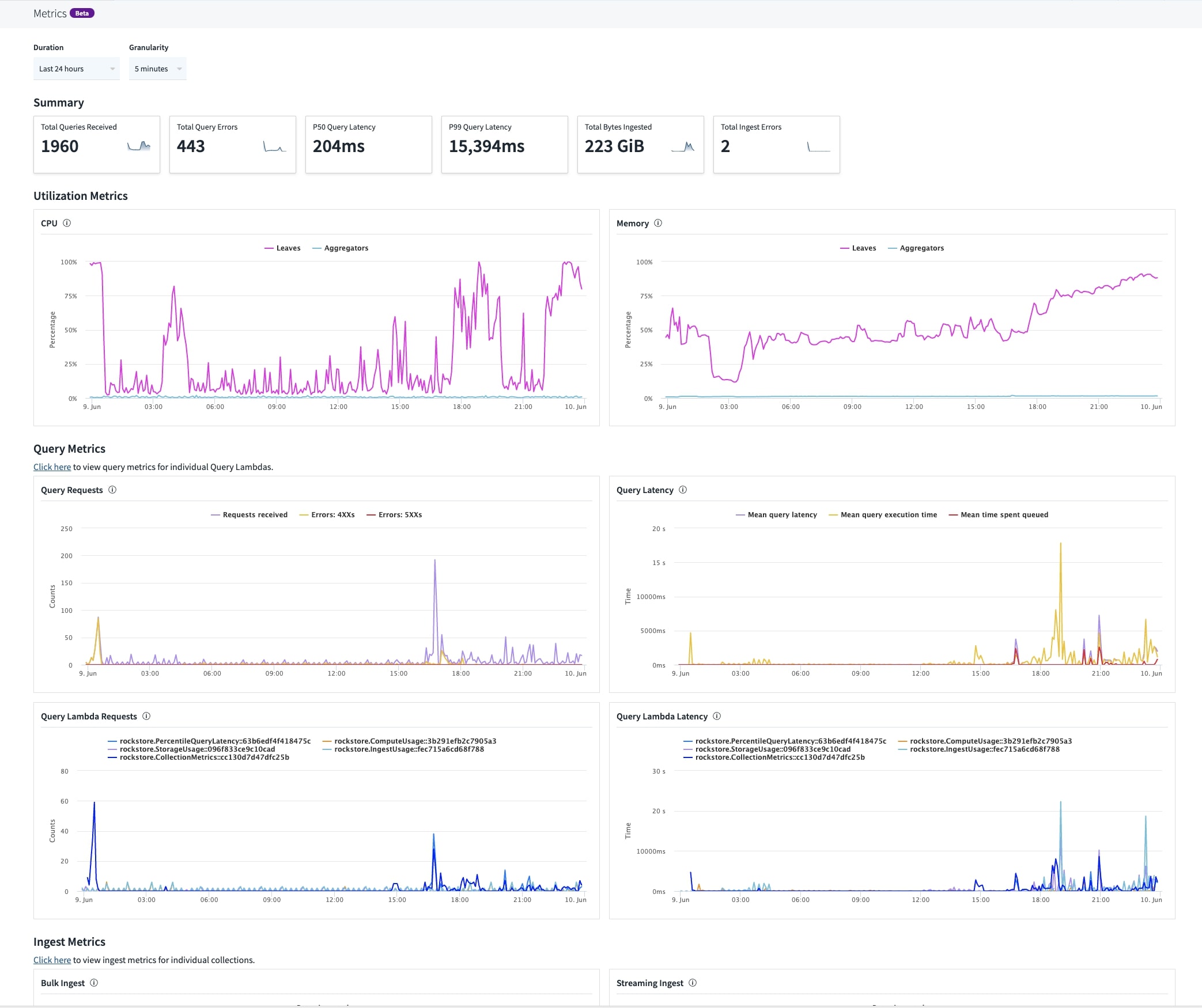
Bringing our customers real-time metrics on the well being of their Rockset assets felt like the proper alternative for dogfooding, and so dogfood we did. Our new Metrics Dashboard is totally powered by Rockset!
Selecting metrics
At a excessive degree, integrating Rockset into your utility consists of:
- Selecting a Digital Occasion
- Ingesting knowledge into collections
- Querying your knowledge
The metrics we offer mirror this move, and holistically cowl any issues chances are you’ll come throughout when constructing with Rockset. They fall into 4 classes:
-
Digital Occasion
- CPU utilization (by leaf / aggregator)
- Allotted compute (by leaf / aggregator)
- Reminiscence utilization (by leaf / aggregator)
- Allotted reminiscence (by leaf / aggregator)
-
Question
- Rely (whole rely, and by Question Lambda)
- Latency (latency throughout all queries, and by Question Lambda)
- 4XX, and 5XX errors (whole rely)
-
Ingest
- Replication lag (by assortment)
- Ingest errors (whole throughout all collections)
- Streaming ingest (whole throughout all collections)
- Bulk ingest (whole throughout all collections)
-
Storage
- Whole storage dimension (whole throughout all collections, and by assortment)
- Whole doc rely (whole throughout all collections, and by assortment)
In selecting what metrics to point out, our baseline purpose was to assist customers reply probably the most recurring questions, resembling:
-
How can I measure my question latencies? What latencies have my Question Lambda’s been seeing? Have there been any question errors? Why did my question latency spike?
- Question latencies and errors throughout all queries can be found, in addition to latencies and errors per Question Lambda in Question Lambda particulars.
- In case your question latency spiked within the final 24 hours, you may drill down by taking a look at question latency by Question Lambda if relevant.
-
What is the knowledge latency between my exterior supply and my Rockset assortment? Have there been any parse errors?
- Now you can view replication lag, in addition to ingest parse errors per assortment in assortment particulars.
-
How do I do know after I have to improve to a bigger Digital Occasion?
- Should you see spikes in CPU or reminiscence utilization to your Digital Occasion, you must most likely stagger your question load, or improve to a bigger Digital Occasion. Test your question rely / latency for the corresponding timestamp for additional affirmation.
Take a look at the brand new dashboard within the Metrics tab of the Rockset Console!
Integrating with current monitoring providers
When you’ve executed your due diligence and have determined that Rockset is the appropriate match to your utility wants, you’ll probably wish to combine Rockset into your current monitoring and alerting workflows.
Each group has distinctive monitoring and alerting wants, and employs an enormous array of third-party instruments and frameworks. As an alternative of reinventing the wheel and making an attempt to construct our personal framework, we needed to construct a mechanism that may allow customers to combine Rockset into any current device in the marketplace.
Metrics Endpoint
We expose metrics knowledge in a Prometheus scraping suitable format, already an open commonplace, enabling you to combine with lots of the hottest monitoring providers, together with however not restricted to:
- Prometheus (and Alertmanager)
- Grafana
- Graphite
- Datadog
- AppDynamics
- Dynatrace
- New Relic
- Amazon CloudWatch
- …and plenty of extra
$ curl https://api.rs2.usw2.rockset.com/v1/orgs/self/metrics -u {API key}:
# HELP rockset_collections Variety of collections.
# TYPE rockset_collections gauge
rockset_collections{virtual_instance_id="30",workspace_name="commons",} 20.0
rockset_collections{virtual_instance_id="30",workspace_name="myWorkspace",} 2.0
rockset_collections{virtual_instance_id="30",workspace_name="myOtherWorkspace",} 1.0
# HELP rockset_collection_size_bytes Assortment dimension in bytes.
# TYPE rockset_collection_size_bytes gauge
rockset_collection_size_bytes{virtual_instance_id="30",workspace_name="commons",collection_name="_events",} 3.74311622E8
...
With this endpoint and the instruments it integrates with, you may:
- Programmatically monitor the state of your Rockset manufacturing metrics
- Configure motion gadgets, like alerts primarily based on CPU utilization thresholds
- Arrange auto remediation by altering Digital Occasion sizes primarily based on manufacturing hundreds
This endpoint is disabled by default, and might be switched on within the Metrics tab (https://console.rockset.com/metrics) within the Rockset Console.

At Rockset, Grafana and Prometheus are two of our important monitoring pillars. For the rollout of our visibility efforts, we arrange our inner Prometheus scraper to hit our personal metrics endpoint. From there, we created charts and alerts which we use in tandem with current metrics and alerts to observe the brand new characteristic!
Get began
An in depth breakdown of the metrics we export via our new endpoint is out there in our documentation.
We have now a primary Prometheus configuration file and an Alertmanager guidelines template in our group Github repository that will help you get began.

{kind=link}