

Latest information present that the variety of recall campaigns attributable to product deficiencies retains rising, whereas every identified recorded case is a multi-million Greenback harm on common. Further reputational- in addition to enterprise continuity- dangers exhibit the draw back potential of every recall being “a bottomless pit”. Product recollects aren’t solely a matter of conventional manufacturing firms of all sizes, they’re related for each firm that produces a product, e.g. pharmaceutical firms. On this article, we argue why a central Delta Lake on prime of a number of manufacturing crops dramatically helps scale back affected harm by shortening problem-solving cycle instances. We additional current an answer accelerator that offers exact examples for traversing course of graphs to detect operational deficiencies.
Challenges and Probabilities of Knowledge Evaluation for Efficient Administration of Recollects
A Word on Recollects
In a scenario by which a producer produces and ships merchandise to a buyer, a product recall is a request from both celebration to return a product after the invention of extreme high quality issues. For instance, Mercedes recalled roughly 144,000 automobiles due to a defect within the gas pump (see right here) and BSH recalled 170,000 fuel stoves that might explode (see right here). Recollects can have an effect on a protracted vary of the worth chain, together with the product’s producer, its clients in addition to its suppliers. Potential damages are:
- Nonconformance prices (NCC): NCCs are the direct prices ensuing from high quality points. Examples are scrap prices, downtime prices, guarantee claims, or recall prices.
- Reputational dangers: Because of a high quality challenge, the producer will be downgraded within the buyer’s high quality notion. This may occasionally end in misplaced gross sales.
- Enterprise continuity dangers: Within the problem-solving section, the producer would possibly resolve to cease producing and transport merchandise to their clients to forestall additional harm. Word that this isn’t fully orthogonal to NCC.
In accordance with Statista, recollects in a manufacturing-intensive economic system like Germany elevated in recent times. Moreover, a research by Allianz (see right here) exhibits {that a} “main” recall results in harm of 10.5 Million Euros. Nonetheless, domino results might make this harm a lot bigger. Examples span a variety of affected industries, like Automotive, Meals and Beverage of IT / Electronics.
Managing recollects will be twofold.
- If the product is already shipped to the shopper, the producer of the affected product should remove and clarify the operational downside as quick as potential to make sure the continuity of their operations. Moreover, a buyer typically recollects an entire time vary though solely a few barcodes are affected. Explaining the difficulty with information and thereby proving which barcodes are affected can dramatically scale back the harm.
- In case of a difficulty within the manufacturing course of or a identified defect with one of many provider’s uncooked supplies the producer of the affected product should establish affected manufacturing steps and barcodes as quick as potential and remove the operational downside.
Each instances require traversing the manufacturing worth chain on a barcode degree both back- or forwards and explaining the difficulty with operational information. Knowledge is the important thing to efficient and quick recall administration!
The Downside With Discovering and Analyzing the “Proper” Knowledge
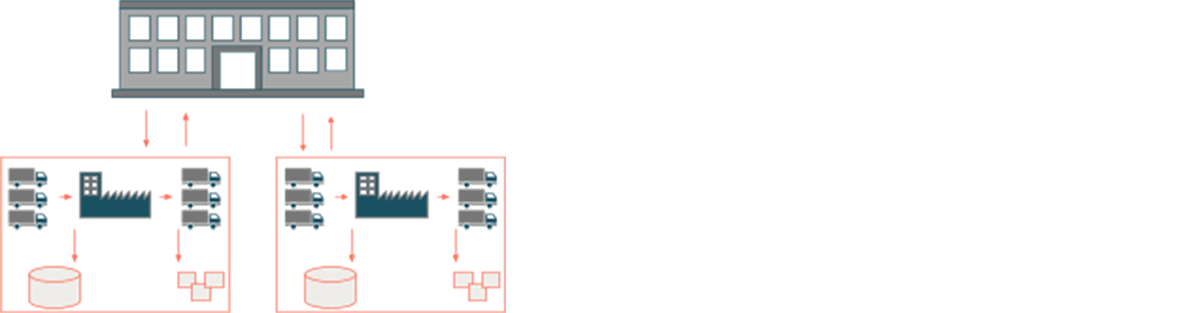
The information panorama in an organizational construction with a number of crops which might be managed by a central division will be problematic. Let’s assume that every plant is equipped with uncooked supplies (indicated with vans coming in) earlier than a product is assembled and the completed product is shipped to the shopper (indicated with vans going out). Two operational programs matter. On the one hand, there’s a Manufacturing Execution System (MES) that controls the method of producing items from uncooked supplies to completed merchandise and then again there’s a planning system (typically SAP) that controls the logistics steps of the completed product. Two totally different programs introduce challenges when traversing the worth chain inside one plant. A number of crops multiply the magnitude of this downside by the variety of crops. Extra exactly:
- No central view – Plant-local MES construct information silos the central division should traverse merchandise of every plant independently, as an alternative of drilling down from a central degree to the plant degree in an computerized trend.
- Lacking information literacy – There’s a small variety of plant-local specialists to investigate the information. The central division is commonly alien to the specifics of every plant and finds it obscure and analyze the plant’s operational information.
- Lacking scalability – The aforementioned operational programs are sometimes topic to on-prem databases because the minimal degree of belief emigrate to the cloud (given identified outages in some areas) isn’t given. Then again, the storage and computational assets of conventional on-premises programs aren’t independently scaleable, which hinders the onboarding of data-centric use instances.
- Blind spot – On-prem programs have issues with unstructured and streaming information, introducing an operational blind spot.
The Lakehouse On High of A number of Vegetation

To mitigate the aforementioned challenges, many producers use Databricks to construct a Lakehouse on prime of a number of manufacturing crops. The “Lakehouse on prime of a number of manufacturing crops” is a standardized “copy” of the plant-local operational programs. It consists primarily of Parquet information on cloud-object storage, which is cost-efficient and extremely scalable. A metadata layer on prime of those information permits for performant information queries and transformations. Knowledge governance options like information entry controls and audibility are simply relevant with the assistance of the Unity Catalog. This structure represents a unified platform for data-intensive manufacturing use instances, together with information warehousing, dashboarding, machine studying, information science or information engineering. For a producer, this gives important advantages:
- It gives a central view by amassing manufacturing information of all crops. A drill-down from the central to the plant degree is definitely potential in an automatic trend.
- The standardized information copy reduces the dependency on particular assets inside one plant.
- The cloud itself gives impartial scalability of storage and computational assets which dramatically facilitates onboarding of data-intensive use instances.
- All information of all codecs will be saved in a cost-efficient manner on cloud object storage.
- Streaming occasions will be ingested within the Delta Lake in low-latency
Whereas this text focuses on recollects, the benefits of the Lakehouse on prime of a number of manufacturing crops are a lot bigger. Examples embrace multi-plant general tools effectivity, energetic manufacturing high quality monitoring, or product supply monitoring. On this article, we concentrate on combining the best information on the proper time for every manufactured barcode, which is the central methodology for structured downside fixing, i.e. barcode traceability.
Three Examples of Barcode Traceability and a Easy Knowledge Mannequin to Sort out Them
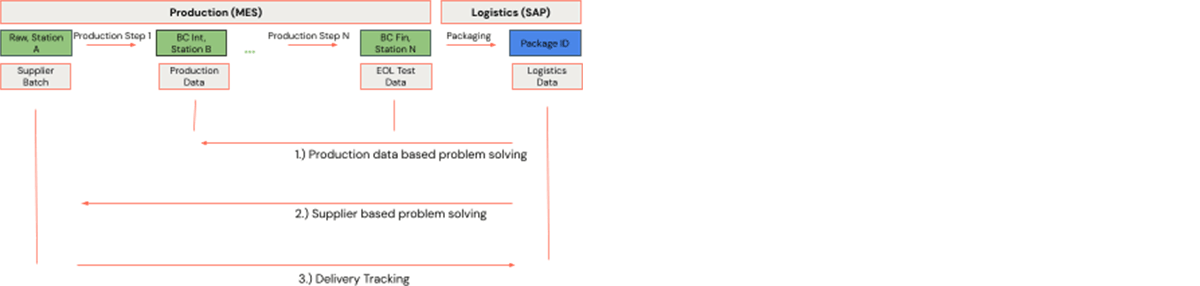
The manufacturing course of consists of stations, by which merchandise are being processed. The merchandise are represented by barcodes. Every barcode is exclusive in a single station inside one plant. The producer’s manufacturing course of begins with uncooked supplies that come from a provider. Barcodes might change alongside the manufacturing course of, for instance because of an meeting step. At every station, additional information is generated, e.g. provider batches, machine information, or take a look at information. The above course of is simplified, as it might include splits or merges. Logistics steps will be seen in precisely this manner, simply that the operational steps could be particular to logistics, e.g. packaging, and a bundle ID would enter the method. The sequence of manufacturing and logistics steps kind a producing course of graph. On this setting, we take into account three examples:
- Manufacturing data-based downside fixing: The producer produces and ships barcodes to a buyer. The shopper finds {that a} significantly giant variety of merchandise have a difficulty and recollects an entire manufacturing time vary. The producer should remove the manufacturing deficiency and clarify ideally with information {that a} restricted variety of barcodes are literally affected. For this function, the producer takes a restricted variety of barcodes which have a identified challenge and analyzes related manufacturing information in its manufacturing course of. The related information is recognized by traversing the operational manufacturing course of backward. That is backward traceability.
- Provider-based downside fixing: That is much like the primary instance, simply that the backward traceability is carried out to the very starting of the manufacturing course of the place the uncooked supplies enter manufacturing. If the evaluation reveals that every one points will be traced again to 1 and the identical provider batch, that is suspicious and may result in additional provider high quality evaluation.
- Supply monitoring: A provider ships uncooked supplies that enter a producer’s manufacturing course of earlier than the ensuing completed merchandise are shipped to the shoppers. The provider finds that a few barcodes don’t meet the specified specs. Unluckily, the affected uncooked materials is already assembled within the producer’s merchandise. The producer should establish the affected barcodes and manufacturing steps as quickly as potential. The related barcodes are recognized by traversing the operational manufacturing course of ahead. That is ahead traceability.
Fortunately, the operational manufacturing course of generates information. We will mannequin these information in varied methods. This text demonstrates modeling the information with the assistance of a quite simple desk which is ready to resolve the aforementioned three instance use instances.
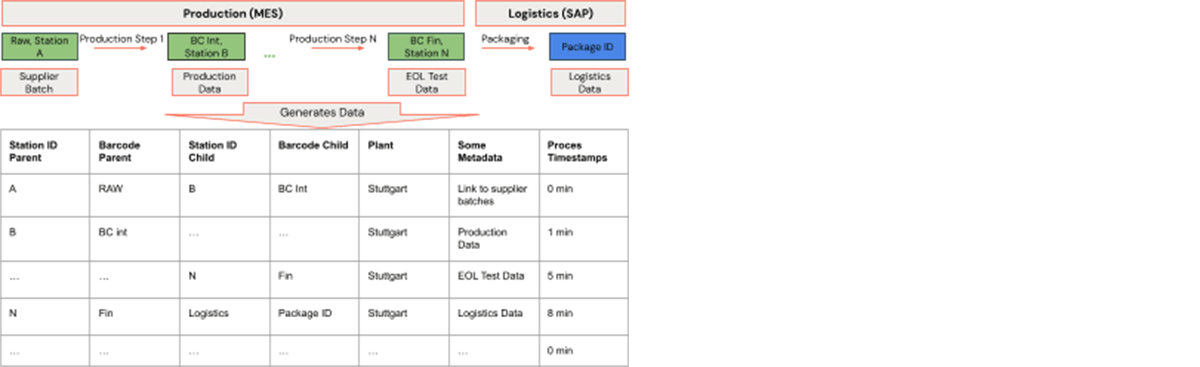
In every course of step, the mix of station ID, barcode, and plant varieties a novel mother or father, which is assembled into one other mixture of those three gadgets. The method has time stamps and different manufacturing information, e.g. press match curves, will be linked. In graph terminology, every row is an edge. The mixture of barcode, station ID, and plant kind a vertex. All vertices can simply be created for the set of edges. This vertex and edge information kind an information illustration of the manufacturing course of graph. By this implies, barcode traceability is a matter of discovering neighborhoods of particular vertices in a graph.
The Barcode Traceability Resolution Accelerator
The Databricks Resolution Accelerators are purpose-built guides tailor-made to speed up clients’ use case improvement. They include absolutely useful notebooks and finest practices with an answer and industry-specific focus.
On this article, we briefly current a resolution accelerator for barcode traceability. Word that many extra explanations and code will be discovered within the Git Repo. Right here, we stroll by the fundamental steps, i.e. the code snippets associated to every of the three examples described above. In every instance, we current a distinct methodology for traversing the graph. This isn’t crucial however demonstrates totally different strategies for traversing a graph. A dialogue concerning the possibilities and limitations of every methodology is printed within the notebooks of the answer accelerator.
Word that the answer accelerator relies on an actual manufacturing instance. On this article, we summary away from the particular manufacturing steps and merchandise and as an alternative concentrate on the code and methodology that may be utilized to sort out barcode traceability.
Creating the Manufacturing Course of Graph
The method steps are as follows
show(edge_df.choose("src","dst","Link_to_data","Start_Time", "End_Time"))
The columns “src” and “dst” are the mother or father and youngster for the graph. They’re product of a string concatenation of the barcode, the station id, and the plant. Different information are linked in a column. The method begin and finish instances are recorded as a timestamp. The graph body can then simply be created.
g = GraphFrame(vertices_df, edge_df)Instance 1: Manufacturing Knowledge-Primarily based Downside Fixing
This instance has a set of barcodes coming from the shopper as enter and we want to hint again to a selected station, i.e. the turning station. We’ll apply Motif Discovering to do that. First, we derive a search sample from a few barcodes utilizing Breadth-first search.
example_path = g_reverted.bfs(
fromExpr = "id = '" + start_search_nodes.accumulate()[0][0] + "'",
toExpr = "SID = 'Turning_Blank_Station'",
maxPathLength = 10)The end result can simply be reworked to a sound search sample which is an abstraction of the particular subgraph we seek for and described by vertices which might be linked by edges.
'(from)-[e0]->(v1);(v1)-[e1]->(v2);(v2)-[e2]->(v3);(v3)-[e3]->(v4);(v4)-[e4]->(v5);(v5)-[e5]->(to)'The subsequent step is to derive a filter expression. That is simple, provided that the shopper solely reported on a few barcodes for which the difficulty was noticed.
'to.id in ('MW4EE3C/At_Customer/1',...)'All suspicious manufacturing chains can then be discovered utilizing
chain = g.discover(motif_search_expression).filter(in_expression)Choosing related components of this output yields a desk with all suspicious barcodes on the turning station for each suspicious barcode that the shopper reported, in addition to the beginning and finish instances of the turning course of. Because the turning station information an limitless time sequence, the timestamps can be utilized to derive the suspicious components of the sequence and problem-solving boils right down to a visible inspection of those sequence.

Instance 2: Provider-Primarily based Downside Fixing
This instance is much like the primary instance. The distinction is that we’ll hint again all the best way to the provider. We may apply the Motif Discovering methodology once more. To exhibit totally different methodologies we apply parallelizing single-threaded Python code with Pandas UDFs. If we handle to decompose the graph into parts which might be linked inside however not throughout, it suffices to carry out traceability inside every element independently. Having discovered all of the parts we first subset to the related parts which massively reduces the graph dimension. Within the subsequent step, we apply a single-threaded Python perform to do traceability inside every element and parallelize utilizing Pandas UDF’s.
We first discover all linked parts.
connected_components_df = g.connectedComponents()Subsetting to related parts is a matter of an interior be part of with the desk that lists all suspicious barcodes row-wise.
relevant_components = (connected_components_df.
be part of(start_search_nodes, on = "id", how="interior").
choose("id", "element").
withColumnRenamed("id",
"search_id_in_this_component").
distinct()
)Say, we’ve a Python perform that does the backwards traceability in every element
def ego_graph_on_component(pdf: pd.DataFrame) -> pd.DataFrame:
...
return resMaking use of the Pandas UDF will be executed with
backwards_traceability_df = (
relevnat_edges
.groupBy("element")
.applyInPandas(ego_graph_on_component, output_schema)
)The result’s a desk with all suspicious barcodes on the provider and the respective batches which is then used for additional problem-solving.
Instance 3: Supply Monitoring
Supply monitoring is tracing the worth chain forwards. The provider on the very starting of the worth chain studies on a few suspicious barcodes and the producer has probably already assembled the uncooked materials in its merchandise. This use case is about figuring out the furthermost barcodes within the producer’s worth chain. We may resolve this use case with Motif Discovering or with the Pandas UDFs and Python features as outlined within the two earlier subsections. Within the Resolution Accelerator, we apply the methodology of Message passing by way of AggregateMessages. It’s a primer to ship messages between vertices, and combination messages for every vertex. We first outline the message to be despatched between vertices.
msgToDst = AM.edge["aggregated_parents"]By iteratively sending and aggregating messages alongside the vertices we are able to traverse the entire graph.
agg = g_for_loop.aggregateMessages(
f.collect_set(AM.msg).alias("aggregated_parents"),
sendToSrc=None,
sendToDst=msgToDst
)This simply yields a desk with all related barcodes for every uncooked materials.
Get Began with Barcode Traceability
Latest information present that the variety of recollects elevated, whereas every identified recorded case is a multi-million harm on common. This confirms the demand for managing recollects in the best manner. Totally different crops with totally different operational programs introduce information silos that hinder barcode traceability and due to this fact an efficient evaluation. A central Delta Lake on prime of a number of crops opens the door to a centralized evaluation of product deficiencies. Strive our resolution accelerator to construct barcode traceability at your group, and enhance the effectiveness of your information evaluation for product deficiencies by dramatically lowering problem-solving cycle instances.
Strive our resolution accelerator to construct barcode traceability at your group, and enhance the effectiveness of your information evaluation for product deficiencies by dramatically lowering problem-solving cycle instances.

{kind=link}