
For the reason that launch of ChatGPT in November 2022, the GenAI
panorama has undergone speedy cycles of experimentation, enchancment, and
adoption throughout a variety of use circumstances. Utilized to the software program
engineering business, GenAI assistants primarily assist engineers write code
sooner by offering autocomplete options and producing code snippets
primarily based on pure language descriptions. This method is used for each
producing and testing code. Whereas we recognise the super potential of
utilizing GenAI for ahead engineering, we additionally acknowledge the numerous
problem of coping with the complexities of legacy programs, along with
the truth that builders spend much more time studying code than writing it.
By modernizing quite a few legacy programs for our shoppers, we have now discovered that an evolutionary method makes
legacy displacement each safer and more practical at attaining its worth objectives. This technique not solely reduces the
dangers of modernizing key enterprise programs but in addition permits us to generate worth early and incorporate frequent
suggestions by regularly releasing new software program all through the method. Regardless of the optimistic outcomes we have now seen
from this method over a “Huge Bang” cutover, the associated fee/time/worth equation for modernizing giant programs is commonly
prohibitive. We consider GenAI can flip this example round.
For our half, we have now been experimenting during the last 18 months with
LLMs to sort out the challenges related to the
modernization of legacy programs. Throughout this time, we have now developed three
generations of CodeConcise, an inside modernization
accelerator at Thoughtworks . The motivation for
constructing CodeConcise stemmed from our statement that the modernization
challenges confronted by our shoppers are comparable. Our aim is for this
accelerator to grow to be our wise default in
legacy modernization, enhancing our modernization worth stream and enabling
us to understand the advantages for our shoppers extra effectively.
We intend to make use of this text to share our expertise making use of GenAI for Modernization. Whereas a lot of the
content material focuses on CodeConcise, that is just because we have now hands-on expertise
with it. We don’t counsel that CodeConcise or its method is the one solution to apply GenAI efficiently for
modernization. As we proceed to experiment with CodeConcise and different instruments, we
will share our insights and learnings with the neighborhood.
GenAI period: A timeline of key occasions
One major purpose for the
present wave of hype and pleasure round GenAI is the
versatility and excessive efficiency of general-purpose LLMs. Every new technology of those fashions has persistently
proven enhancements in pure language comprehension, inference, and response
high quality. We’re seeing plenty of organizations leveraging these highly effective
fashions to satisfy their particular wants. Moreover, the introduction of
multimodal AIs, comparable to text-to-image generative fashions like DALL-E, alongside
with AI fashions able to video and audio comprehension and technology,
has additional expanded the applicability of GenAIs. Furthermore, the
newest AI fashions can retrieve new info from real-time sources,
past what’s included of their coaching datasets, additional broadening
their scope and utility.
Since then, we have now noticed the emergence of latest software program merchandise designed
with GenAI at their core. In different circumstances, current merchandise have grow to be
GenAI-enabled by incorporating new options beforehand unavailable. These
merchandise usually make the most of basic objective LLMs, however these quickly hit limitations when their use case goes past
prompting the LLM to generate responses purely primarily based on the info it has been educated with (text-to-text
transformations). For example, in case your use case requires an LLM to grasp and
entry your group’s information, probably the most economically viable resolution usually
entails implementing a Retrieval-Augmented Era (RAG) method.
Alternatively, or together with RAG, fine-tuning a general-purpose mannequin is likely to be acceptable,
particularly if you happen to want the mannequin to deal with advanced guidelines in a specialised
area, or if regulatory necessities necessitate exact management over the
mannequin’s outputs.
The widespread emergence of GenAI-powered merchandise may be partly
attributed to the supply of quite a few instruments and improvement
frameworks. These instruments have democratized GenAI, offering abstractions
over the complexities of LLM-powered workflows and enabling groups to run
fast experiments in sandbox environments with out requiring AI technical
experience. Nevertheless, warning have to be exercised in these comparatively early
days to not fall into traps of comfort with frameworks to which
Thoughtworks’ latest expertise radar
attests.
Issues that make modernization costly
After we started exploring using “GenAI for Modernization”, we
centered on issues that we knew we’d face repeatedly – issues
we knew have been those inflicting modernization to be time or value
prohibitive.
- How can we perceive the prevailing implementation particulars of a system?
- How can we perceive its design?
- How can we collect data about it with out having a human knowledgeable obtainable
to information us? - Can we assist with idiomatic translation of code at scale to our desired tech
stack? How? - How can we reduce dangers from modernization by bettering and including
automated checks as a security internet? - Can we extract from the codebase the domains, subdomains, and
capabilities? - How can we offer higher security nets in order that variations in conduct
between previous programs and new programs are clear and intentional? How will we allow
cut-overs to be as headache free as attainable?
Not all of those questions could also be related in each modernization
effort. We’ve intentionally channeled our issues from probably the most
difficult modernization eventualities: Mainframes. These are a few of the
most important legacy programs we encounter, each by way of dimension and
complexity. If we will resolve these questions on this situation, then there
will definitely be fruit born for different expertise stacks.
The Structure of CodeConcise
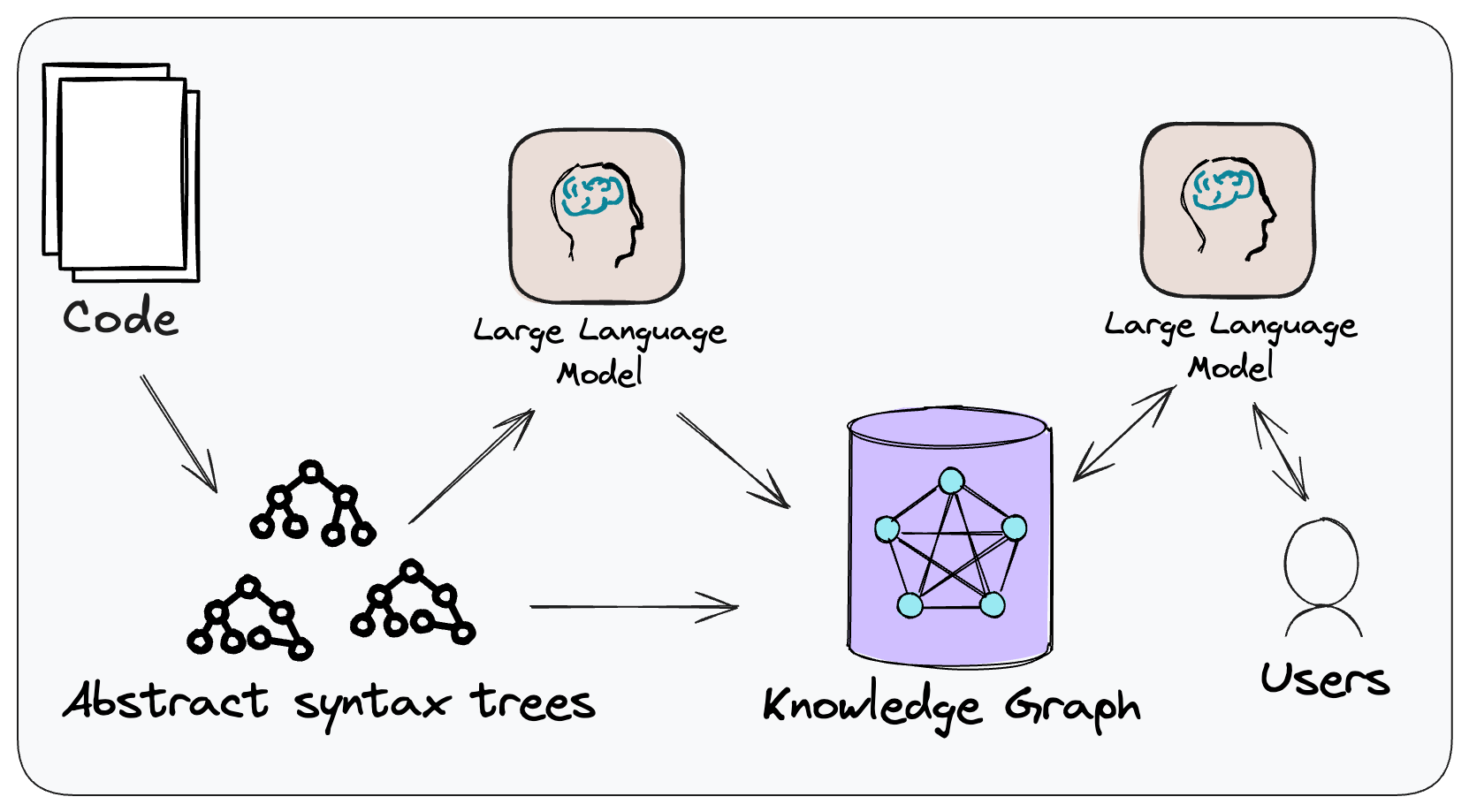
Determine 1: The conceptual method of CodeConcise.
CodeConcise is impressed by the Code-as-data
idea, the place code is
handled and analyzed in methods historically reserved for information. This implies
we’re not treating code simply as textual content, however by way of using language
particular parsers, we will extract its intrinsic construction, and map the
relationships between entities within the code. That is executed by parsing the
code right into a forest of Summary Syntax Timber (ASTs), that are then
saved in a graph database.

Determine 2: An ingestion pipeline in CodeConcise.
Edges between nodes are then established, for instance an edge is likely to be saying
“the code on this node transfers management to the code in that node”. This course of
doesn’t solely enable us to grasp how one file within the codebase may relate
to a different, however we additionally extract at a a lot granular degree, for instance, which
conditional department of the code in a single file transfers management to code within the
different file. The power to traverse the codebase at such a degree of granularity
is especially vital because it reduces noise (i.e. pointless code) from the
context offered to LLMs, particularly related for recordsdata that don’t include
extremely cohesive code. Primarily, there are two advantages we observe from this
noise discount. First, the LLM is extra prone to keep focussed on the immediate.
Second, we use the restricted area within the context window in an environment friendly method so we
can match extra info into one single immediate. Successfully, this enables the
LLM to research code in a method that isn’t restricted by how the code is organized in
the primary place by builders. We discuss with this deterministic course of because the ingestion pipeline.
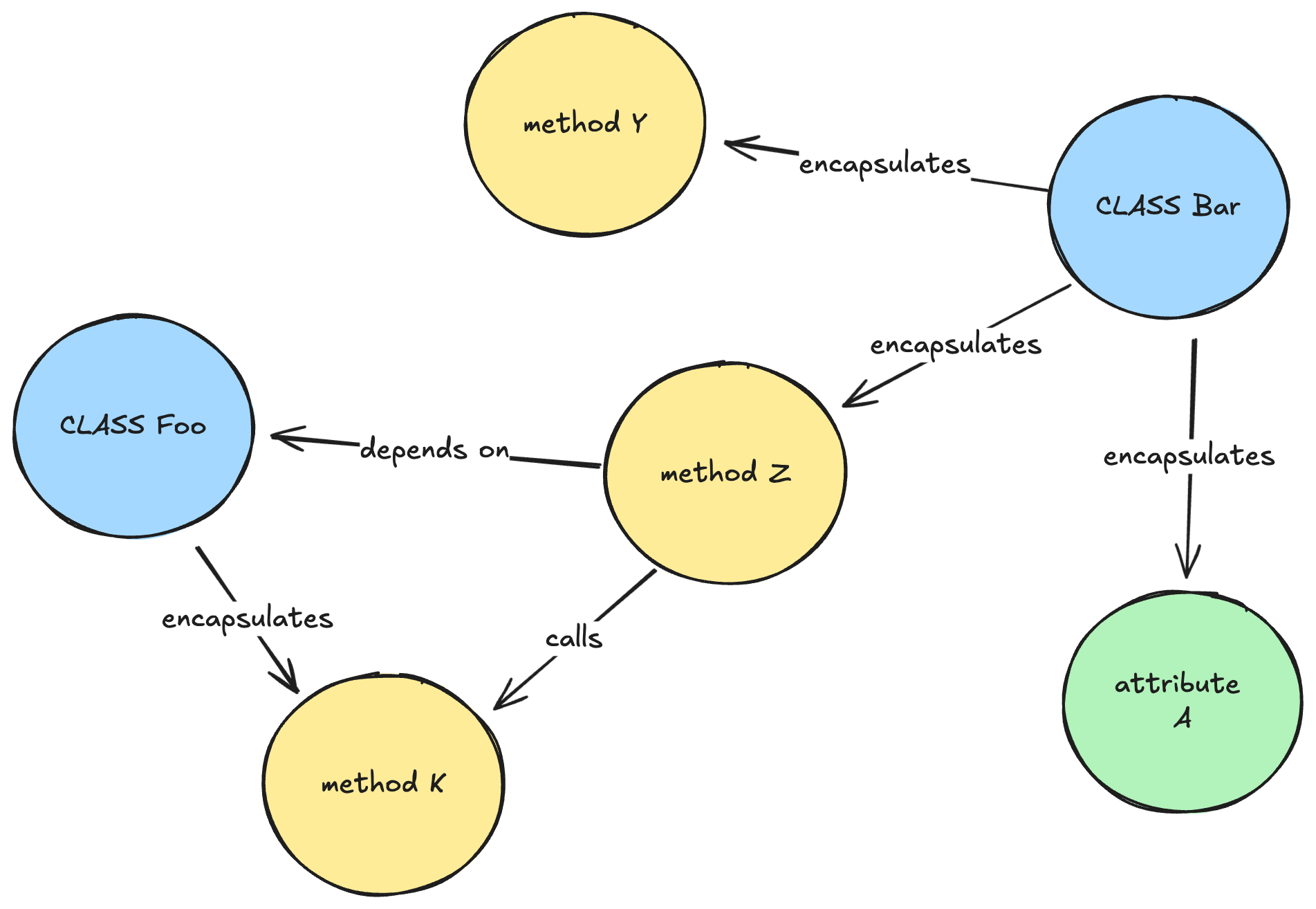
Determine 3: A simplified illustration of how a data graph may appear to be for a Java codebase.
Subsequently, a comprehension pipeline traverses the graph utilizing a number of
algorithms, comparable to Depth-first Search with
backtracking in post-order
traversal, to counterpoint the graph with LLM-generated explanations at varied depths
(e.g. strategies, courses, packages). Whereas some approaches at this stage are
widespread throughout legacy tech stacks, we have now additionally engineered prompts in our
comprehension pipeline tailor-made to particular languages or frameworks. As we started
utilizing CodeConcise with actual, manufacturing shopper code, we recognised the necessity to
preserve the comprehension pipeline extensible. This ensures we will extract the
data most beneficial to our customers, contemplating their particular area context.
For instance, at one shopper, we found {that a} question to a selected database
desk applied in code can be higher understood by Enterprise Analysts if
described utilizing our shopper’s enterprise terminology. That is significantly related
when there may be not a Ubiquitous
Language shared between
technical and enterprise groups. Whereas the (enriched) data graph is the primary
product of the comprehension pipeline, it isn’t the one precious one. Some
enrichments produced throughout the pipeline, comparable to routinely generated
documentation in regards to the system, are precious on their very own. When offered
on to customers, these enrichments can complement or fill gaps in current
programs documentation, if one exists.
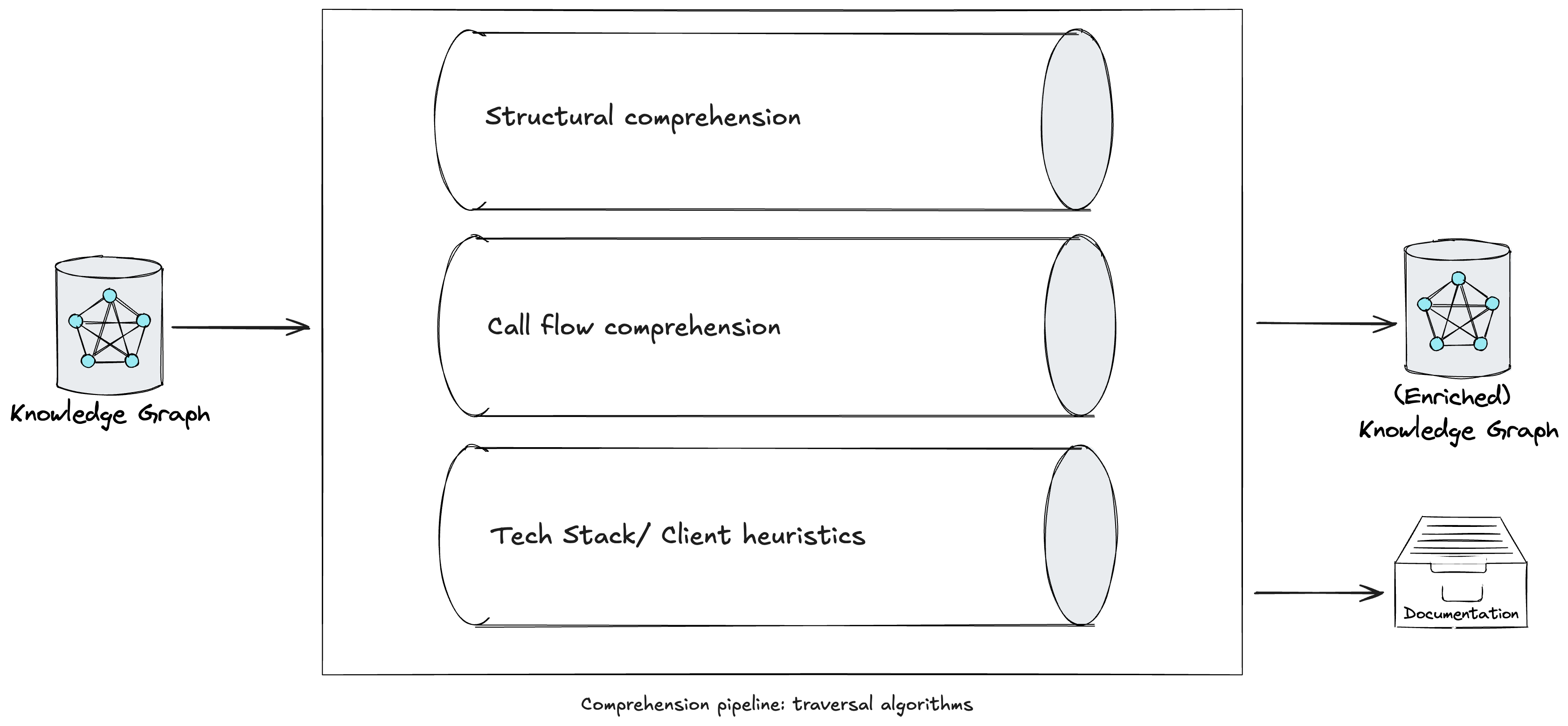
Determine 4: A comprehension pipeline in CodeConcise.
Neo4j, our graph database of selection, holds the (enriched) Information Graph.
This DBMS options vector search capabilities, enabling us to combine the
Information Graph into the frontend software implementing RAG. This method
gives the LLM with a a lot richer context by leveraging the graph’s construction,
permitting it to traverse neighboring nodes and entry LLM-generated explanations
at varied ranges of abstraction. In different phrases, the retrieval part of RAG
pulls nodes related to the consumer’s immediate, whereas the LLM additional traverses the
graph to collect extra info from their neighboring nodes. For example,
when on the lookout for info related to a question about “how does authorization
work when viewing card particulars?” the index might solely present again outcomes that
explicitly take care of validating consumer roles, and the direct code that does so.
Nevertheless, with each behavioral and structural edges within the graph, we will additionally
embrace related info in referred to as strategies, the encircling bundle of code,
and within the information buildings which were handed into the code when offering
context to the LLM, thus frightening a greater reply. The next is an instance
of an enriched data graph for AWS Card
Demo,
the place blue and inexperienced nodes are the outputs of the enrichments executed within the
comprehension pipeline.

Determine 5: An (enriched) data graph for AWS Card Demo.
The relevance of the context offered by additional traversing the graph
finally relies on the factors used to assemble and enrich the graph within the
first place. There isn’t any one-size-fits-all resolution for this; it should depend upon
the particular context, the insights one goals to extract from their code, and,
finally, on the ideas and approaches that the event groups adopted
when setting up the answer’s codebase. For example, heavy use of
inheritance buildings may require extra emphasis on INHERITS_FROM edges vs
COMPOSED_OF edges in a codebase that favors composition.
For additional particulars on the CodeConcise resolution mannequin, and insights into the
progressive studying we had by way of the three iterations of the accelerator, we
will quickly be publishing one other article: Code comprehension experiments with
LLMs.
Within the subsequent sections, we delve deeper into particular modernization
challenges that, if solved utilizing GenAI, may considerably influence the associated fee,
worth, and time for modernization – elements that usually discourage us from making
the choice to modernize now. In some circumstances, we have now begun exploring internally
how GenAI may handle challenges we have now not but had the chance to
experiment with alongside our shoppers. The place that is the case, our writing is
extra speculative, and we have now highlighted these situations accordingly.

{kind=link}