
[*]
The aim of this weblog put up is to supply finest practices on how one can use terraform to configure Rockset to ingest the info into two collections, and how one can setup a view and question lambdas which might be utilized in an software, plus to indicate the workflow of later updating the question lambdas. This mimics how we use terraform at Rockset to handle Rockset sources.
Terraform is essentially the most standard used DevOps software for infrastructure administration, that permits you to outline your infrastructure as code, after which the software will take the configuration and compute the steps wanted to take it from the present state to the specified state.
Final we’ll have a look at how one can use GitHub actions to routinely run terraform plan for pull requests, and as soon as the pull request are permitted and merged, it’s going to run terraform apply to make the required modifications.
The complete terraform configuration used on this weblog put up is offered right here.
Terraform
To comply with alongside by yourself, you’ll need:
and also you additionally have to set up terraform in your pc, which is so simple as this on macOS.
$ brew faucet hashicorp/faucet
$ brew set up hashicorp/faucet/terraform
(directions for different working techniques can be found within the hyperlink above)
Supplier setup
Step one to utilizing terraform is to configure the suppliers we might be utilizing, Rockset and AWS. Create a file referred to as _provider.tf with the contents.
terraform {
required_providers {
aws = {
supply = "hashicorp/aws"
model = "~> 4"
}
rockset = {
supply = "rockset/rockset"
model = "0.6.2"
}
}
}
supplier rockset {}
supplier aws {
area = "us-west-2"
}
Each suppliers use surroundings variables to learn the credentials they require to entry the respective companies.
- Rockset:
ROCKSET_APIKEYandROCKSET_APISERVER - AWS:
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEY, orAWS_PROFILE
Backend configuration
Terraform saves details about the managed infrastructure and configuration in a state file. To share this state between native runs in your pc, and automatic runs from GitHub actions, we use a so referred to as backend configuration, which shops the state in an AWS S3 bucket, so all invocations of terraform can use it.
backend "s3" {
bucket = "rockset-community-terraform"
key = "weblog/state"
area = "us-west-2"
}
 For a manufacturing deployment, be certain to configure state locking too.
For a manufacturing deployment, be certain to configure state locking too.
AWS IAM Position
To permit Rockset to ingest the contents of an S3 bucket, we first need to create an AWS IAM position which Rockset will use to entry the contents of the bucket. It makes use of a information supply to learn details about your Rockset group, so it may configure AWS appropriately.
information rockset_account present {}
useful resource "aws_iam_policy" "rockset-s3-integration" {
title = var.rockset_role_name
coverage = templatefile("${path.module}/information/coverage.json", {
bucket = var.bucket
prefix = var.bucket_prefix
})
}
useful resource "aws_iam_role" "rockset" {
title = var.rockset_role_name
assume_role_policy = information.aws_iam_policy_document.rockset-trust-policy.json
}
information "aws_iam_policy_document" "rockset-trust-policy" {
assertion {
sid = ""
impact = "Enable"
actions = [
"sts:AssumeRole"
]
principals {
identifiers = [
"arn:aws:iam::${data.rockset_account.current.account_id}:root"
]
kind = "AWS"
}
situation {
take a look at = "StringEquals"
values = [
data.rockset_account.current.external_id
]
variable = "sts:ExternalId"
}
}
}
useful resource "aws_iam_role_policy_attachment" "rockset_s3_integration" {
position = aws_iam_role.rockset.title
policy_arn = aws_iam_policy.rockset-s3-integration.arn
}
This creates an AWS IAM cross-account position which Rockset is allowed to make use of to ingest information.
Rockset S3 integration
Now we will create the mixing that allows Rockset to ingest information from S3, utilizing the IAM position above.
useful resource "time_sleep" "wait_30s" {
depends_on = [aws_iam_role.rockset]
create_duration = "15s"
}
useful resource "rockset_s3_integration" "integration" {
title = var.bucket
aws_role_arn = aws_iam_role.rockset.arn
depends_on = [time_sleep.wait_30s]
}
You may get an AWS cross-account position error should you skip the time_sleep useful resource, as a result of it takes a number of seconds for the newly created AWS position to propagate, so this protects you from having to rerun terraform apply once more.
Rockset assortment
With the mixing we at the moment are capable of create a workspace to carry all sources we are going to add, after which setup a assortment which ingest information utilizing the above S3 integration.
useful resource rockset_workspace weblog {
title = "weblog"
}
useful resource "rockset_s3_collection" "assortment" {
title = var.assortment
workspace = rockset_workspace.weblog.title
retention_secs = var.retention_secs
supply {
format = "json"
integration_name = rockset_s3_integration.integration.title
bucket = var.bucket
sample = "public/films/*.json"
}
}
Kafka Assortment
Subsequent we’ll setup a set from a Confluent Cloud supply, and add an ingest transformation that summarizes the info.
useful resource "rockset_kafka_integration" "confluent" {
title = var.bucket
aws_role_arn = aws_iam_role.rockset.arn
use_v3 = true
bootstrap_servers = var.KAFKA_REST_ENDPOINT
security_config = {
api_key = var.KAFKA_API_KEY
secret = var.KAFKA_API_SECRET
}
}
useful resource "rockset_kafka_collection" "orders" {
title = "orders"
workspace = rockset_workspace.weblog.title
retention_secs = var.retention_secs
supply {
integration_name = rockset_kafka_integration.confluent.title
}
field_mapping_query = file("information/transformation.sql")
}
The SQL for the ingest transformation is saved in a separate file, which terraform injects into the configuration.
SELECT
COUNT(i.orderid) AS orders,
SUM(i.orderunits) AS models,
i.handle.zipcode,
i.handle.state,
-- bucket information in 5 minute buckets
TIME_BUCKET(MINUTES(5), TIMESTAMP_MILLIS(i.ordertime)) AS _event_time
FROM
_input AS i
WHERE
-- drop all data with an incorrect state
i.handle.state != 'State_'
GROUP BY
_event_time,
i.handle.zipcode,
i.handle.state
View
With the info ingested into a set we will create a view, which limits which paperwork in a set might be accessed by means of that view.
useful resource rockset_view english-movies {
title = "english-movies"
question = file("information/view.sql")
workspace = rockset_workspace.weblog.title
depends_on = [rockset_alias.movies]
}
The view wants an specific depends_on meta-argument as terraform doesn’t interpret the SQL for the view which resides in a separate file.
Alias
An alias is a option to discuss with an present assortment by a special title. This can be a handy manner to have the ability to change the which assortment a set of queries use, with out having to replace the SQL for all of them.
useful resource rockset_alias films {
collections = ["${rockset_workspace.blog.name}.${rockset_s3_collection.movies.name}"]
title = "films"
workspace = rockset_workspace.weblog.title
}
As an example, if we began to ingest films from a Kafka stream, we will replace the alias to reference the brand new assortment and all queries begin utilizing it instantly.
Position
We create a job which is proscribed to solely executing question lambdas solely within the weblog workspace, after which save the API key within the AWS Methods Supervisor Parameter Retailer for later retrieval by the code which can execute the lambda. This manner the credentials won’t ever need to be uncovered to a human.
useful resource rockset_role read-only {
title = "blog-read-only"
privilege {
motion = "EXECUTE_QUERY_LAMBDA_WS"
cluster = "*ALL*"
resource_name = rockset_workspace.weblog.title
}
}
useful resource "rockset_api_key" "ql-only" {
title = "blog-ql-only"
position = rockset_role.read-only.title
}
useful resource "aws_ssm_parameter" "api-key" {
title = "/rockset/weblog/apikey"
kind = "SecureString"
worth = rockset_api_key.ql-only.key
}
Question Lambda
The question lambda shops the SQL in a separate file, and has a tag that makes use of the terraform variable stable_version which when set, is used to pin the secure tag to that model of the question lambda, and if not set it’s going to level to the most recent model.
Inserting the SQL in a separate file isn’t a requirement, but it surely makes for simpler studying and you’ll copy/paste the SQL into the Rockset console to manually strive the modifications. One other profit is that reviewing modifications to the SQL is less complicated when it isn’t intermingled with different modifications, like it might if it was positioned in-line with the terraform configuration.
SELECT
title,
TIME_BUCKET(
YEARS(1),
PARSE_TIMESTAMP('%Y-%m-%d', release_date)
) as 12 months,
recognition
FROM
weblog.films AS m
the place
release_date != ''
AND recognition > 10
GROUP BY
12 months,
title,
recognition
order by
recognition desc
useful resource "rockset_query_lambda" "top-rated" {
title = "top-rated-movies"
workspace = rockset_workspace.weblog.title
sql {
question = file("information/top-rated.sql")
}
}
useful resource "rockset_query_lambda_tag" "secure" {
title = "secure"
query_lambda = rockset_query_lambda.top-rated.title
model = var.stable_version == "" ? rockset_query_lambda.top-rated.model : var.stable_version
workspace = rockset_workspace.weblog.title
}
Making use of the configuration
With all configuration recordsdata in place, it’s time to “apply” the modifications, which implies that terraform will learn the configuration recordsdata, and interrogate Rockset and AWS for the present configuration, after which calculate what steps it must take to get to the top state.
Step one is to run terraform init, which can obtain all required terraform suppliers and configure the S3 backend.
$ terraform init
Initializing the backend...
Efficiently configured the backend "s3"! Terraform will routinely
use this backend until the backend configuration modifications.
Initializing supplier plugins...
- Discovering hashicorp/aws variations matching "~> 4.0"...
- Discovering rockset/rockset variations matching "~> 0.6.2"...
- Putting in hashicorp/aws v4.39.0...
- Put in hashicorp/aws v4.39.0 (signed by HashiCorp)
- Putting in hashicorp/time v0.9.1...
- Put in hashicorp/time v0.9.1 (signed by HashiCorp)
- Putting in rockset/rockset v0.6.2...
- Put in rockset/rockset v0.6.2 (signed by a HashiCorp associate, key ID DB47D0C3DF97C936)
Companion and group suppliers are signed by their builders.
If you would like to know extra about supplier signing, you may examine it right here:
https://www.terraform.io/docs/cli/plugins/signing.html
Terraform has created a lock file .terraform.lock.hcl to file the supplier
picks it made above. Embody this file in your model management repository
in order that Terraform can assure to make the identical picks by default when
you run "terraform init" sooner or later.
Terraform has been efficiently initialized!
You could now start working with Terraform. Attempt operating "terraform plan" to see
any modifications which might be required on your infrastructure. All Terraform instructions
ought to now work.
In the event you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working listing. In the event you neglect, different
instructions will detect it and remind you to take action if mandatory.
Subsequent we run terraform plan to get a listing of which sources terraform goes to create, and to see the order by which it’s going to create it.
$ terraform plan
information.rockset_account.present: Studying...
information.rockset_account.present: Learn full after 0s [id=318212636800]
information.aws_iam_policy_document.rockset-trust-policy: Studying...
information.aws_iam_policy_document.rockset-trust-policy: Learn full after 0s [id=2982727827]
Terraform used the chosen suppliers to generate the next execution plan. Useful resource actions are indicated with the next symbols:
+ create
Terraform will carry out the next actions:
# aws_iam_policy.rockset-s3-integration might be created
+ useful resource "aws_iam_policy" "rockset-s3-integration" {
+ arn = (identified after apply)
+ id = (identified after apply)
+ title = "rockset-s3-integration"
+ path = "/"
+ coverage = jsonencode(
{
+ Id = "RocksetS3IntegrationPolicy"
+ Assertion = [
+ {
+ Action = [
+ "s3:ListBucket",
]
+ Impact = "Enable"
+ Useful resource = [
+ "arn:aws:s3:::rockset-community-datasets",
]
+ Sid = "BucketActions"
},
+ {
+ Motion = [
+ "s3:GetObject",
]
+ Impact = "Enable"
+ Useful resource = [
+ "arn:aws:s3:::rockset-community-datasets/*",
]
+ Sid = "ObjectActions"
},
]
+ Model = "2012-10-17"
}
)
+ policy_id = (identified after apply)
+ tags_all = (identified after apply)
}
...
# rockset_workspace.weblog might be created
+ useful resource "rockset_workspace" "weblog" {
+ created_by = (identified after apply)
+ description = "created by Rockset terraform supplier"
+ id = (identified after apply)
+ title = "weblog"
}
Plan: 15 so as to add, 0 to vary, 0 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Observe: You did not use the -out possibility to avoid wasting this plan, so Terraform cannot assure to take precisely these actions should you run "terraform apply" now. 7s 665ms 13:53:32
Assessment the output and confirm that it’s doing what you count on, after which you’re prepared to use the modifications utilizing terraform apply. This repeats the plan output, and asks you to confirm that you’re prepared to use the modifications
$ terraform apply
information.rockset_account.present: Studying...
information.rockset_account.present: Learn full after 0s [id=318212636800]
information.aws_iam_policy_document.rockset-trust-policy: Studying...
information.aws_iam_policy_document.rockset-trust-policy: Learn full after 0s [id=2982727827]
Terraform used the chosen suppliers to generate the next execution plan. Useful resource actions are indicated with the next symbols:
+ create
Terraform will carry out the next actions:
...
# time_sleep.wait_30s might be created
+ useful resource "time_sleep" "wait_30s" {
+ create_duration = "15s"
+ id = (identified after apply)
}
Plan: 16 so as to add, 0 to vary, 0 to destroy.
Do you need to carry out these actions?
Terraform will carry out the actions described above.
Solely 'sure' might be accepted to approve.
Enter a price: sure
rockset_workspace.weblog: Creating...
rockset_kafka_integration.confluent: Creating...
rockset_workspace.weblog: Creation full after 0s [id=blog]
rockset_role.read-only: Creating...
rockset_query_lambda.top-rated: Creating...
rockset_role.read-only: Creation full after 1s [id=blog-read-only]
rockset_api_key.ql-only: Creating...
rockset_api_key.ql-only: Creation full after 0s [id=blog-ql-only]
rockset_query_lambda.top-rated: Creation full after 1s [id=blog.top-rated-movies]
rockset_query_lambda_tag.secure: Creating...
rockset_query_lambda_tag.secure: Creation full after 0s [id=blog.top-rated-movies.stable]
rockset_kafka_integration.confluent: Creation full after 1s [id=confluent-cloud-blog]
rockset_kafka_collection.orders: Creating...
aws_ssm_parameter.api-key: Creating...
aws_iam_role.rockset: Creating...
aws_iam_policy.rockset-s3-integration: Creating...
aws_ssm_parameter.api-key: Creation full after 1s [id=/rockset/blog/apikey]
aws_iam_policy.rockset-s3-integration: Creation full after 1s [id=arn:aws:iam::459021908517:policy/rockset-s3-integration]
aws_iam_role.rockset: Creation full after 2s [id=rockset-s3-integration]
aws_iam_role_policy_attachment.rockset_s3_integration: Creating...
time_sleep.wait_30s: Creating...
aws_iam_role_policy_attachment.rockset_s3_integration: Creation full after 0s [id=rockset-s3-integration-20221114233744029000000001]
rockset_kafka_collection.orders: Nonetheless creating... [10s elapsed]
time_sleep.wait_30s: Nonetheless creating... [10s elapsed]
time_sleep.wait_30s: Creation full after 15s [id=2022-11-14T23:37:58Z]
rockset_s3_integration.integration: Creating...
rockset_s3_integration.integration: Creation full after 0s [id=rockset-community-datasets]
rockset_s3_collection.films: Creating...
rockset_kafka_collection.orders: Nonetheless creating... [20s elapsed]
rockset_s3_collection.films: Nonetheless creating... [10s elapsed]
rockset_kafka_collection.orders: Nonetheless creating... [30s elapsed]
rockset_kafka_collection.orders: Creation full after 34s [id=blog.orders]
rockset_s3_collection.films: Nonetheless creating... [20s elapsed]
rockset_s3_collection.films: Nonetheless creating... [30s elapsed]
rockset_s3_collection.films: Nonetheless creating... [40s elapsed]
rockset_s3_collection.films: Creation full after 43s [id=blog.movies-s3]
rockset_alias.films: Creating...
rockset_alias.films: Creation full after 1s [id=blog.movies]
rockset_view.english-movies: Creating...
rockset_view.english-movies: Creation full after 1s [id=blog.english-movies]
Apply full! Sources: 16 added, 0 modified, 0 destroyed.
Outputs:
latest-version = "0eb04bfed335946d"
So in about 1 minute it created all required sources (and 30 seconds have been spent ready for the AWS IAM position to propagate).
Updating sources
As soon as the preliminary configuration has been utilized, we’d need to make modifications to a number of sources, e.g. replace the SQL for a question lambda. Terraform will assist us plan these modifications, and solely apply what has modified.
SELECT
title,
TIME_BUCKET(
YEARS(1),
PARSE_TIMESTAMP('%Y-%m-%d', release_date)
) as 12 months,
recognition
FROM
weblog.films AS m
the place
release_date != ''
AND recognition > 11
GROUP BY
12 months,
title,
recognition
order by
recognition desc
We’ll additionally replace the variables.tf file to pin the secure tag to the present model, in order that the secure doesn’t change till we’ve correctly examined it.
variable "stable_version" {
kind = string
default = "0eb04bfed335946d"
description = "Question Lambda model for the secure tag. If empty, the most recent model is used."
}
Now we will go forward and apply the modifications.
$ terraform apply
information.rockset_account.present: Studying...
rockset_workspace.weblog: Refreshing state... [id=blog]
rockset_kafka_integration.confluent: Refreshing state... [id=confluent-cloud-blog]
rockset_role.read-only: Refreshing state... [id=blog-read-only]
rockset_query_lambda.top-rated: Refreshing state... [id=blog.top-rated-movies]
rockset_kafka_collection.orders: Refreshing state... [id=blog.orders]
rockset_api_key.ql-only: Refreshing state... [id=blog-ql-only]
rockset_query_lambda_tag.secure: Refreshing state... [id=blog.top-rated-movies.stable]
information.rockset_account.present: Learn full after 1s [id=318212636800]
information.aws_iam_policy_document.rockset-trust-policy: Studying...
aws_iam_policy.rockset-s3-integration: Refreshing state... [id=arn:aws:iam::459021908517:policy/rockset-s3-integration]
aws_ssm_parameter.api-key: Refreshing state... [id=/rockset/blog/apikey]
information.aws_iam_policy_document.rockset-trust-policy: Learn full after 0s [id=2982727827]
aws_iam_role.rockset: Refreshing state... [id=rockset-s3-integration]
aws_iam_role_policy_attachment.rockset_s3_integration: Refreshing state... [id=rockset-s3-integration-20221114233744029000000001]
time_sleep.wait_30s: Refreshing state... [id=2022-11-14T23:37:58Z]
rockset_s3_integration.integration: Refreshing state... [id=rockset-community-datasets]
rockset_s3_collection.films: Refreshing state... [id=blog.movies-s3]
rockset_alias.films: Refreshing state... [id=blog.movies]
rockset_view.english-movies: Refreshing state... [id=blog.english-movies]
Terraform used the chosen suppliers to generate the next execution plan. Useful resource actions are indicated with the next symbols:
~ replace in-place
Terraform will carry out the next actions:
# rockset_query_lambda.top-rated might be up to date in-place
~ useful resource "rockset_query_lambda" "top-rated" {
id = "weblog.top-rated-movies"
title = "top-rated-movies"
~ model = "0eb04bfed335946d" -> (identified after apply)
# (3 unchanged attributes hidden)
- sql {
- question = <<-EOT
SELECT
title,
TIME_BUCKET(
YEARS(1),
PARSE_TIMESTAMP('%Y-%m-%d', release_date)
) as 12 months,
recognition
FROM
weblog.films AS m
the place
release_date != ''
AND recognition > 10
GROUP BY
12 months,
title,
recognition
order by
recognition desc
EOT -> null
}
+ sql {
+ question = <<-EOT
SELECT
title,
TIME_BUCKET(
YEARS(1),
PARSE_TIMESTAMP('%Y-%m-%d', release_date)
) as 12 months,
recognition
FROM
weblog.films AS m
the place
release_date != ''
AND recognition > 11
GROUP BY
12 months,
title,
recognition
ORDER BY
recognition desc
EOT
}
}
Plan: 0 so as to add, 1 to vary, 0 to destroy.
Do you need to carry out these actions?
Terraform will carry out the actions described above.
Solely 'sure' might be accepted to approve.
Enter a price: sure
rockset_query_lambda.top-rated: Modifying... [id=blog.top-rated-movies]
rockset_query_lambda.top-rated: Modifications full after 0s [id=blog.top-rated-movies]
Apply full! Sources: 0 added, 1 modified, 0 destroyed.
Outputs:
latest-version = "2e268a64224ce9b2"
As you may see it up to date the question lambda model because the SQL modified.
Executing the Question Lambda
You may execute the question lambda from the command line utilizing curl. This reads the apikey from the AWS SSM Parameter Retailer, after which executes the lambda utilizing the newest tag.
$ curl --request POST
--url https://api.usw2a1.rockset.com/v1/orgs/self/ws/weblog/lambdas/top-rated-movies/tags/newest
-H "Authorization: ApiKey $(aws ssm get-parameters --with-decryption --query 'Parameters[*].{Worth:Worth}' --output=textual content --names /rockset/weblog/apikey)"
-H 'Content material-Sort: software/json'
When we’ve verified that the question lambda returns the proper outcomes, we will go forward and replace the secure tag to the output of the final terraform apply command.
variable "stable_version" {
kind = string
default = "2e268a64224ce9b2"
description = "Question Lambda model for the secure tag. If empty, the most recent model is used."
}
Lastly apply the modifications once more to replace tag.
$ terraform apply
rockset_workspace.weblog: Refreshing state... [id=blog]
information.rockset_account.present: Studying...
rockset_kafka_integration.confluent: Refreshing state... [id=confluent-cloud-blog]
rockset_query_lambda.top-rated: Refreshing state... [id=blog.top-rated-movies]
rockset_role.read-only: Refreshing state... [id=blog-read-only]
rockset_kafka_collection.orders: Refreshing state... [id=blog.orders]
rockset_api_key.ql-only: Refreshing state... [id=blog-ql-only]
rockset_query_lambda_tag.secure: Refreshing state... [id=blog.top-rated-movies.stable]
information.rockset_account.present: Learn full after 1s [id=318212636800]
aws_iam_policy.rockset-s3-integration: Refreshing state... [id=arn:aws:iam::459021908517:policy/rockset-s3-integration]
information.aws_iam_policy_document.rockset-trust-policy: Studying...
aws_ssm_parameter.api-key: Refreshing state... [id=/rockset/blog/apikey]
information.aws_iam_policy_document.rockset-trust-policy: Learn full after 0s [id=2982727827]
aws_iam_role.rockset: Refreshing state... [id=rockset-s3-integration]
aws_iam_role_policy_attachment.rockset_s3_integration: Refreshing state... [id=rockset-s3-integration-20221114233744029000000001]
time_sleep.wait_30s: Refreshing state... [id=2022-11-14T23:37:58Z]
rockset_s3_integration.integration: Refreshing state... [id=rockset-community-datasets]
rockset_s3_collection.films: Refreshing state... [id=blog.movies-s3]
rockset_alias.films: Refreshing state... [id=blog.movies]
rockset_view.english-movies: Refreshing state... [id=blog.english-movies]
Terraform used the chosen suppliers to generate the next execution plan. Useful resource actions are indicated with the next symbols:
~ replace in-place
Terraform will carry out the next actions:
# rockset_query_lambda_tag.secure might be up to date in-place
~ useful resource "rockset_query_lambda_tag" "secure" {
id = "weblog.top-rated-movies.secure"
title = "secure"
~ model = "0eb04bfed335946d" -> "2af51ce4d09ec319"
# (2 unchanged attributes hidden)
}
Plan: 0 so as to add, 1 to vary, 0 to destroy.
Do you need to carry out these actions?
Terraform will carry out the actions described above.
Solely 'sure' might be accepted to approve.
Enter a price: sure
rockset_query_lambda_tag.secure: Modifying... [id=blog.top-rated-movies.stable]
rockset_query_lambda_tag.secure: Modifications full after 1s [id=blog.top-rated-movies.stable]
Apply full! Sources: 0 added, 1 modified, 0 destroyed.
Outputs:
latest-version = "2e268a64224ce9b2"
Now the secure tag refers back to the newest question lambda model.
GitHub Motion
To utilize Infrastructure as Code, we’re going to place all terraform configurations in a git repository hosted by GitHub, and make the most of the pull request workflow for terraform modifications.
We’ll setup a GitHub motion to routinely run terraform plan for every pull request, and put up a touch upon the PR displaying the deliberate modifications.
As soon as the pull request is permitted and merged, it’s going to run terraform apply to make the modifications in your pull request to Rockset.
Setup
This part is a shortened model of Automate Terraform with GitHub Actions, which can speak you thru all steps in a lot larger element.
Save the beneath file as .github/workflows/terraform.yml
title: "Terraform"
on:
push:
branches:
- grasp
pull_request:
jobs:
terraform:
title: "Terraform"
runs-on: ubuntu-latest
steps:
- title: Checkout
makes use of: actions/checkout@v3
- title: Setup Terraform
makes use of: hashicorp/setup-terraform@v1
with:
# terraform_version: 0.13.0:
cli_config_credentials_token: ${{ secrets and techniques.TF_API_TOKEN }}
- title: Terraform Format
id: fmt
run: terraform fmt -check
working-directory: terraform/weblog
- title: Terraform Init
id: init
run: terraform init
working-directory: terraform/weblog
- title: Terraform Validate
id: validate
run: terraform validate -no-color
working-directory: terraform/weblog
- title: Terraform Plan
id: plan
if: github.event_name == 'pull_request'
run: terraform plan -no-color -input=false
working-directory: terraform/weblog
continue-on-error: true
- makes use of: actions/github-script@v6
if: github.event_name == 'pull_request'
env:
PLAN: "terraformn${{ steps.plan.outputs.stdout }}"
with:
github-token: ${{ secrets and techniques.GITHUB_TOKEN }}
script: |
const output = `#### Terraform Format and Fashion  `${{ steps.fmt.consequence }}`
#### Terraform Initialization
`${{ steps.fmt.consequence }}`
#### Terraform Initialization  `${{ steps.init.consequence }}`
#### Terraform Validation
`${{ steps.init.consequence }}`
#### Terraform Validation  `${{ steps.validate.consequence }}`
#### Terraform Plan
`${{ steps.validate.consequence }}`
#### Terraform Plan  `${{ steps.plan.consequence }}`
<particulars><abstract>Present Plan</abstract>
```n
${course of.env.PLAN}
```
</particulars>
*Pushed by: @${{ github.actor }}, Motion: `${{ github.event_name }}`*`;
github.relaxation.points.createComment({
issue_number: context.challenge.quantity,
proprietor: context.repo.proprietor,
repo: context.repo.repo,
physique: output
})
working-directory: terraform/weblog
- title: Terraform Plan Standing
if: steps.plan.consequence == 'failure'
run: exit 1
- title: Terraform Apply
if: github.ref == 'refs/heads/grasp' && github.event_name == 'push'
run: terraform apply -auto-approve -input=false
working-directory: terraform/weblog
`${{ steps.plan.consequence }}`
<particulars><abstract>Present Plan</abstract>
```n
${course of.env.PLAN}
```
</particulars>
*Pushed by: @${{ github.actor }}, Motion: `${{ github.event_name }}`*`;
github.relaxation.points.createComment({
issue_number: context.challenge.quantity,
proprietor: context.repo.proprietor,
repo: context.repo.repo,
physique: output
})
working-directory: terraform/weblog
- title: Terraform Plan Standing
if: steps.plan.consequence == 'failure'
run: exit 1
- title: Terraform Apply
if: github.ref == 'refs/heads/grasp' && github.event_name == 'push'
run: terraform apply -auto-approve -input=false
working-directory: terraform/weblog
Observe that this can be a simplified setup, for a manufacturing grade configuration you need to run terraform plan -out FILE and save the file, so it may be used as enter to terraform apply FILE, so solely the precise permitted modifications within the pull request are utilized. Extra info might be discovered right here.
Pull Request
While you create a pull request that modifications the terraform config, the workflow will run terraform plan and remark on the PR, which incorporates the plan output.
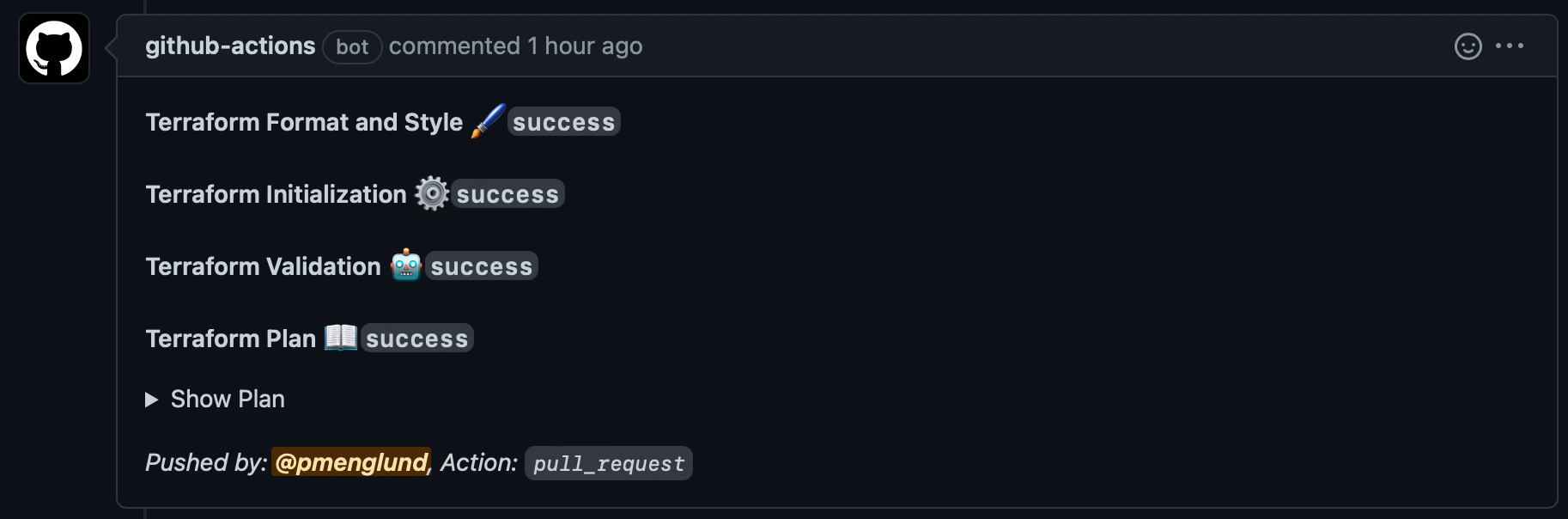
This lets the reviewer see that the change might be utilized, and by clicking on “Present Plan” they will see precisely what modifications are going to be made.
When the PR is permitted and merged into the principle department, it’s going to set off one other GitHub motion workflow run which applies the change.
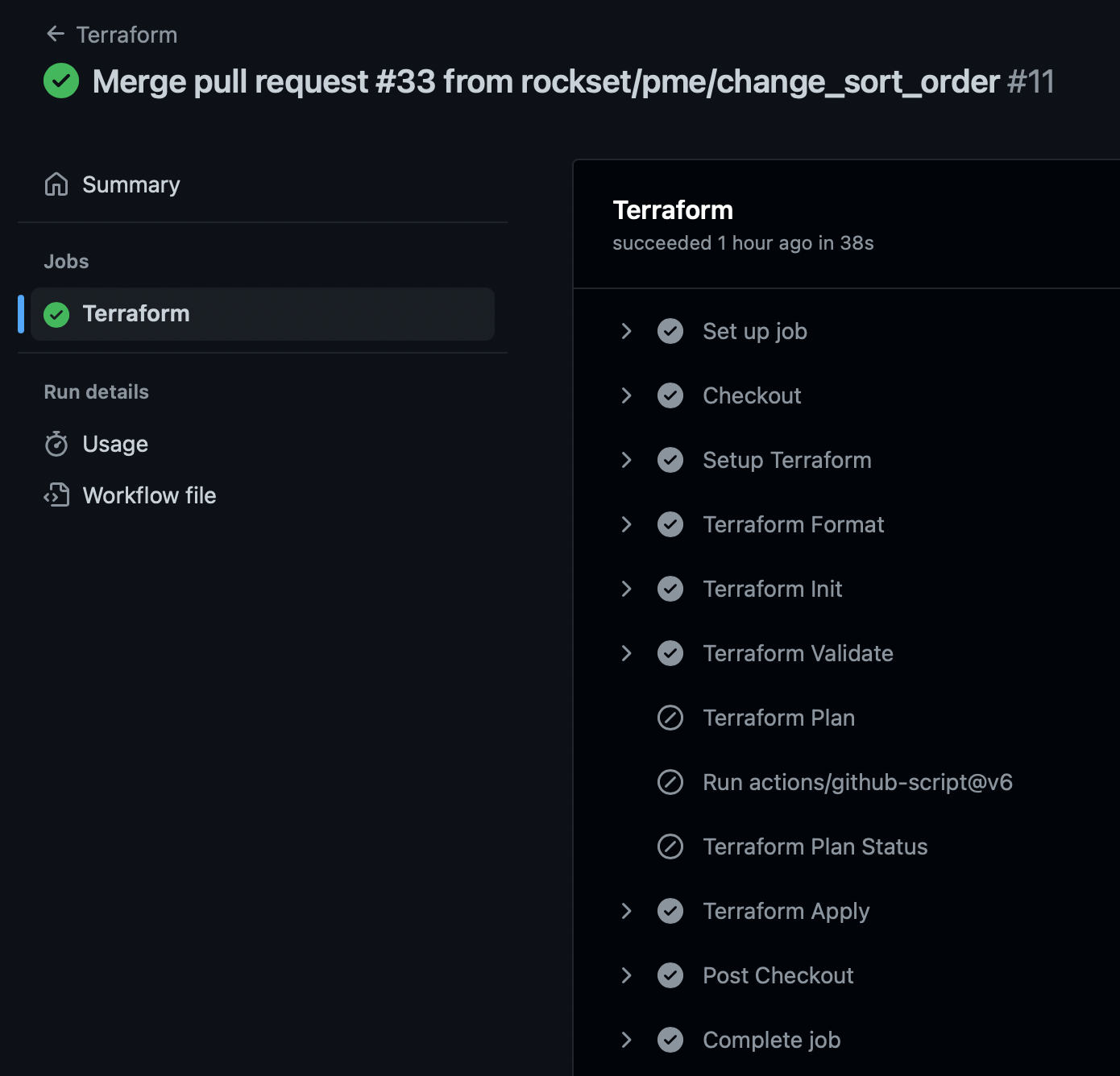
Remaining phrases
Now we’ve a totally practical Infrastructure as Code setup that may deploy modifications to your Rockset configuration routinely after peer evaluate.
[*]
[*]Supply hyperlink

{kind=link}