
This publish outlines the way to use SQL for querying and becoming a member of uncooked knowledge units like nested JSON and CSV – for enabling quick, interactive knowledge science.
Information scientists and analysts cope with complicated knowledge. A lot of what they analyze may very well be third-party knowledge, over which there’s little management. As a way to make use of this knowledge, important effort is spent in knowledge engineering. Information engineering transforms and normalizes high-cardinality, nested knowledge into relational databases or into an output format that may then be loaded into knowledge science notebooks to derive insights. At many organizations, knowledge scientists or, extra generally, knowledge engineers implement knowledge pipelines to remodel their uncooked knowledge into one thing usable.
Information pipelines, nonetheless, often get in the best way of knowledge scientists and analysts attending to insights with their knowledge. They’re time-consuming to put in writing and preserve, particularly because the variety of pipelines grows with every new knowledge supply added. They’re typically brittle, do not deal with schema adjustments effectively, and add complexity to the information science course of. Information scientists are sometimes depending on others—knowledge engineering groups—to construct these pipelines as effectively, lowering their velocity to worth with their knowledge.

Analyzing Third-Get together Information to Help Funding Selections
I’ve had the chance to work with quite a lot of knowledge scientists and analysts in funding administration companies, who’re analyzing complicated knowledge units with a purpose to assist funding choices. They more and more herald various, third-party knowledge—app utilization, web site visits, individuals employed, and fundraising—to boost their analysis. They usually use this knowledge to judge their current portfolio and supply new funding alternatives. The standard pipeline for these knowledge units contains scripts and Apache Spark jobs to remodel knowledge, relational databases like PostgreSQL to retailer the reworked knowledge, and at last, dashboards that serve data from the relational database.
On this weblog, we take a particular instance the place an information scientist could mix two knowledge units—an App Annie nested JSON knowledge set that has statistics of cellular app utilization and engagement, and Crunchbase CSV knowledge set that tracks private and non-private corporations globally. The CSV knowledge to be queried is saved in AWS S3. We’ll use SQL to remodel the nested JSON and CSV knowledge units after which be a part of them collectively to derive some attention-grabbing insights within the type of interactive knowledge science, all with none prior preparation or transformation. We’ll use Rockset for operating SQL on the JSON and CSV knowledge units.
Understanding the form of the nested JSON knowledge set utilizing Jupyter pocket book
We start by loading the App Annie dataset right into a Rockset assortment named app_annie_monthly. App Annie knowledge is within the type of nested JSON, and has as much as 3 ranges of nested arrays in it. It has descriptions of fields in columns, together with statistics of Month-to-month Lively Customers (MAU) that we’ll be utilizing later. The rows comprise the information comparable to these columns within the description.
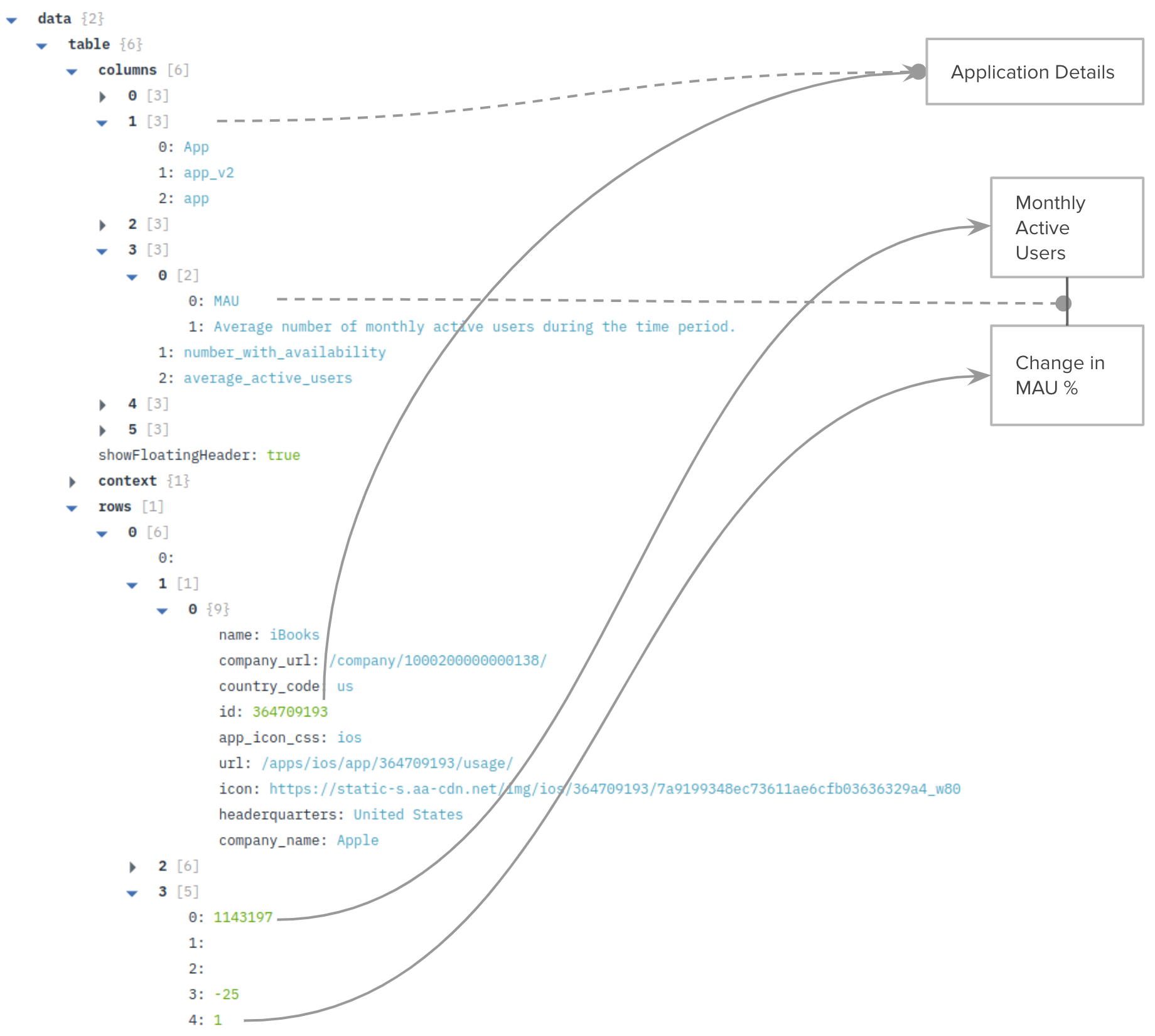
Following this, we are able to arrange our Jupyter pocket book configured to make use of our Rockset account. Instantly after setup, we are able to run some primary SQL queries on the nested JSON knowledge set that we’ve got loaded.
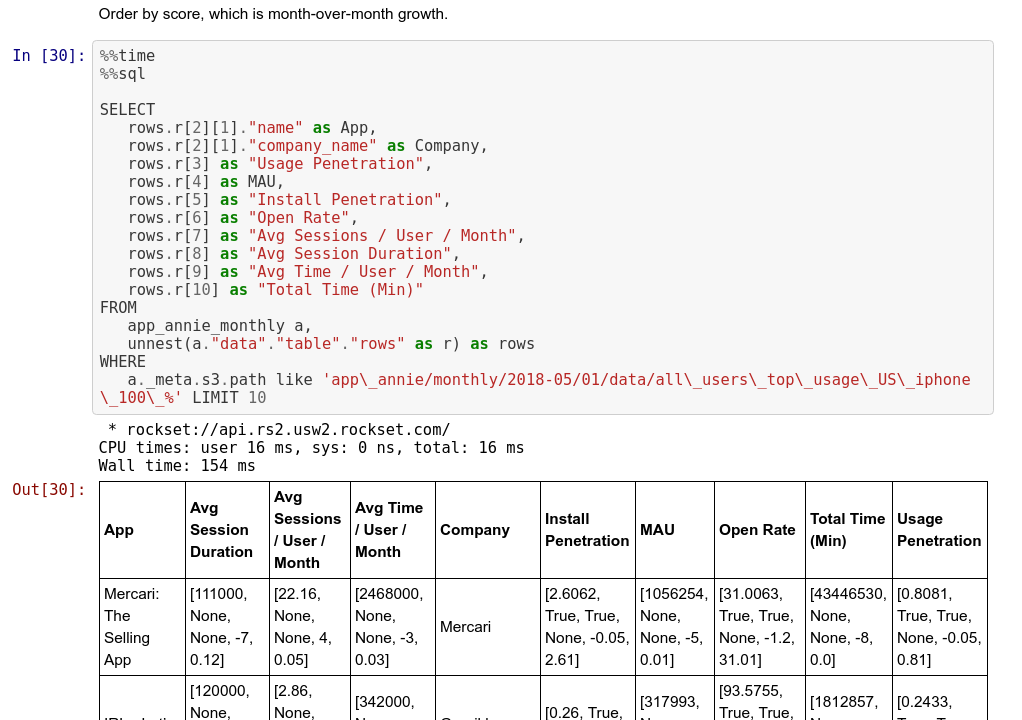
Operating SQL on nested JSON knowledge
As soon as we’ve got understood the general construction of the nested JSON knowledge set, we are able to begin unpacking the elements we’re fascinated with utilizing the UNNEST command in SQL. In our case, we care concerning the app identify, the share improve in MAU month over month, and the corporate that makes the app.
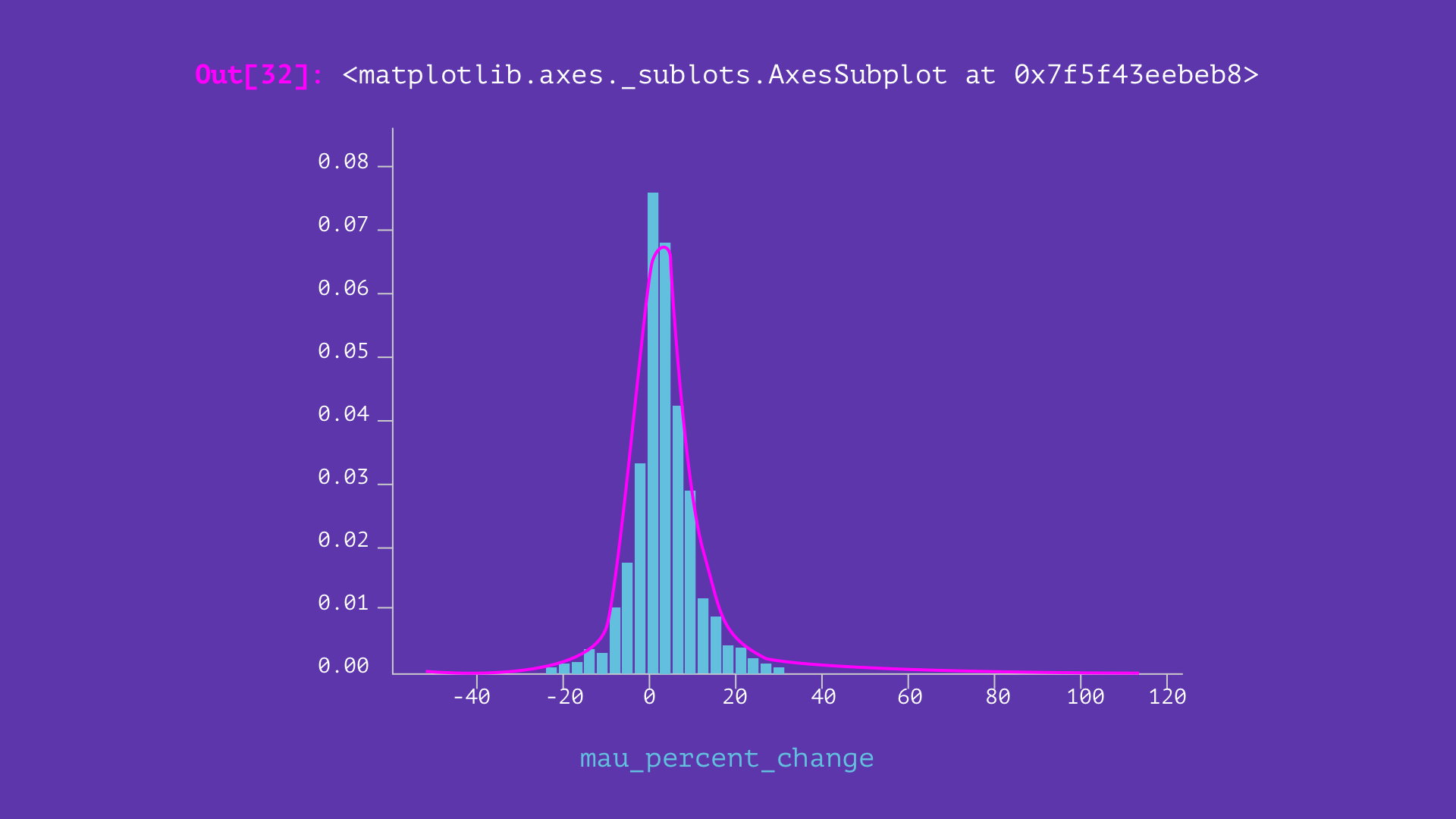
As soon as we’ve got gotten to this desk, we are able to do some primary statistical calculations by exporting the information to dataframes. Dataframes can be utilized to visualise the share development in MAU over the information set for a selected month.
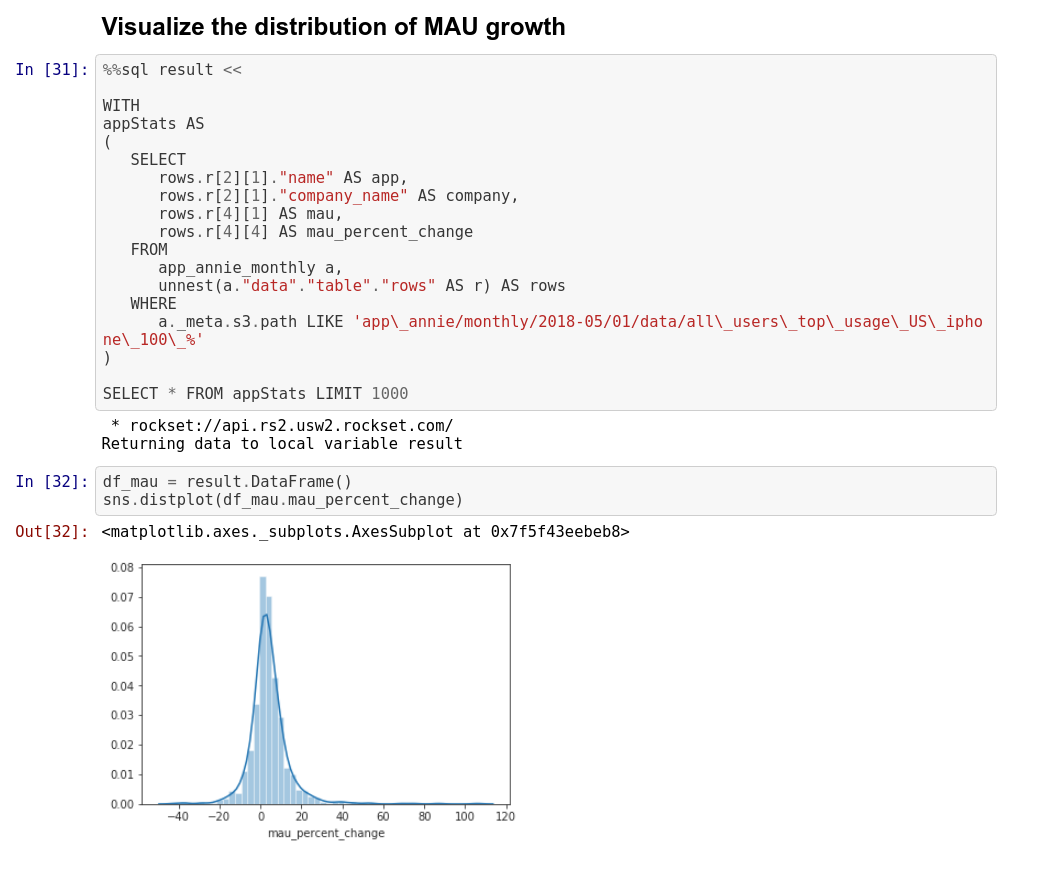
Utilizing SQL to hitch the nested JSON knowledge with CSV knowledge
Now we are able to create the crunchbase_funding_rounds assortment in Rockset from CSV recordsdata saved in Amazon S3 in order that we are able to question them utilizing SQL. It is a pretty easy CSV file with many fields. We’re significantly fascinated with some fields: company_name, country_code, investment_type, investor_names, and last_funding. These fields present us further details about the businesses. We are able to be a part of these on the company_name discipline, and apply a number of further filters to reach on the last record of prospects for funding, ranked from most to minimal improve in MAU.
%%time
%%sql
WITH
-- # compute software statistics, MAU and % change in MAU.
appStats AS
(
SELECT
rows.r[2][1]."identify" AS app,
rows.r[2][1]."company_name" AS firm,
rows.r[4][1] AS mau,
rows.r[4][4] AS mau_percent_change
FROM
app_annie_monthly a,
unnest(a."knowledge"."desk"."rows" AS r) AS rows
WHERE
a._meta.s3.path LIKE 'app_annie/month-to-month/2018-05/01/knowledge/all_users_top_usage_US_iphone_100_%'
),
-- # Get record of crunchbase orgs to hitch with.
crunchbaseOrgs AS
(
SELECT
founded_on AS founded_on,
uuid AS company_uuid,
short_description AS short_description,
company_name as company_name
FROM
"crunchbase_organizations"
),
-- # Get the JOINED relation from the above steps.
appStatsWithCrunchbaseOrgs as
(
SELECT
appStats.app as App,
appStats.mau as mau,
appStats.mau_percent_change as mau_percent_change,
crunchbaseOrgs.company_uuid as company_uuid,
crunchbaseOrgs.company_name as company_name,
crunchbaseOrgs.founded_on as founded_on,
crunchbaseOrgs.short_description as short_description
FROM
appStats
INNER JOIN
crunchbaseOrgs
ON appStats.firm = crunchbaseOrgs.company_name
),
-- # Compute companyStatus = (IPO|ACQUIRED|CLOSED|OPERATING)
-- # There could also be a couple of standing related to an organization, so, we do the Group By and Min.
companyStatus as
(
SELECT
company_name,
min(
case
standing
when
'ipo'
then
1
when
'acquired'
then
2
when
'closed'
then
3
when
'working'
then
4
finish
) as standing
FROM
"crunchbase_organizations"
GROUP BY
company_name
),
-- # JOIN with companyStatus == (OPERATING), name it ventureFunded
ventureFunded as (SELECT
appStatsWithCrunchbaseOrgs.App,
appStatsWithCrunchbaseOrgs.company_name,
appStatsWithCrunchbaseOrgs.mau_percent_change,
appStatsWithCrunchbaseOrgs.mau,
appStatsWithCrunchbaseOrgs.company_uuid,
appStatsWithCrunchbaseOrgs.founded_on,
appStatsWithCrunchbaseOrgs.short_description
FROM
appStatsWithCrunchbaseOrgs
INNER JOIN
companyStatus
ON appStatsWithCrunchbaseOrgs.company_name = companyStatus.company_name
AND companyStatus.standing = 4),
-- # Discover the newest spherical that every firm raised, grouped by firm UUID
latestRound AS
(
SELECT
company_uuid as cuid,
max(announced_on) as announced_on,
max(raised_amount_usd) as raised_amount_usd
FROM
"crunchbase_funding_rounds"
GROUP BY
company_uuid
),
-- # Be part of it again with crunchbase_funding_rounds to get different particulars about that firm
fundingRounds AS
(
SELECT
cfr.company_uuid as company_uuid,
cfr.announced_on as announced_on,
cfr.funding_round_uuid as funding_round_uuid,
cfr.company_name as company_name,
cfr.investment_type as investment_type,
cfr.raised_amount_usd as raised_amount_usd,
cfr.country_code as country_code,
cfr.state_code as state_code,
cfr.investor_names as investor_names
FROM
"crunchbase_funding_rounds" cfr
JOIN
latestRound
ON latestRound.company_uuid = cfr.company_uuid
AND latestRound.announced_on = cfr.announced_on
),
-- # Lastly, choose the dataset with all of the fields which might be attention-grabbing to us. ventureFundedAllRegions
ventureFundedAllRegions AS (
SELECT
ventureFunded.App as App,
ventureFunded.company_name as company_name,
ventureFunded.mau as mau,
ventureFunded.mau_percent_change as mau_percent_change,
ventureFunded.short_description as short_description,
fundingRounds.announced_on as last_funding,
fundingRounds.raised_amount_usd as raised_amount_usd,
fundingRounds.country_code as country_code,
fundingRounds.state_code as state_code,
fundingRounds.investor_names as investor_names,
fundingRounds.investment_type as investment_type
FROM
ventureFunded
JOIN
fundingRounds
ON fundingRounds.company_uuid = ventureFunded.company_uuid)
SELECT * FROM ventureFundedAllRegions
ORDER BY
mau_percent_change DESC LIMIT 10
This last massive question does a number of operations one after one other. So as, the operations that it performs and the intermediate SQL question names are:
appStats:UNNESToperation on the App Annie dataset that extracts the attention-grabbing fields right into a format resembling a flat desk.crunchbaseOrgs: Extracts related fields from the crunchbase assortment.appStatsWithCrunchbaseOrgs: Joins the App Annie and Crunchbase knowledge on the corporate identify.companyStatus: Units up filtering for corporations based mostly on their present standing – IPO/Acquired/Closed/Working. Every firm could have a number of information however the ordering ensures that the newest standing is captured.ventureFunded: Makes use of the above metric to filter out organizations that aren’t presently privately held and working.latestRound: Finds the newest funding spherical—in complete sum invested (USD) and the date when it was introduced.fundingRounds&ventureFundedAllRegions: Wrap all of it collectively and extract different particulars of relevance that we are able to use.
Information Science Insights on Potential Investments
We are able to run one last question on the named question we’ve got, ventureFundedAllRegions to generate the most effective potential investments for the funding administration agency.
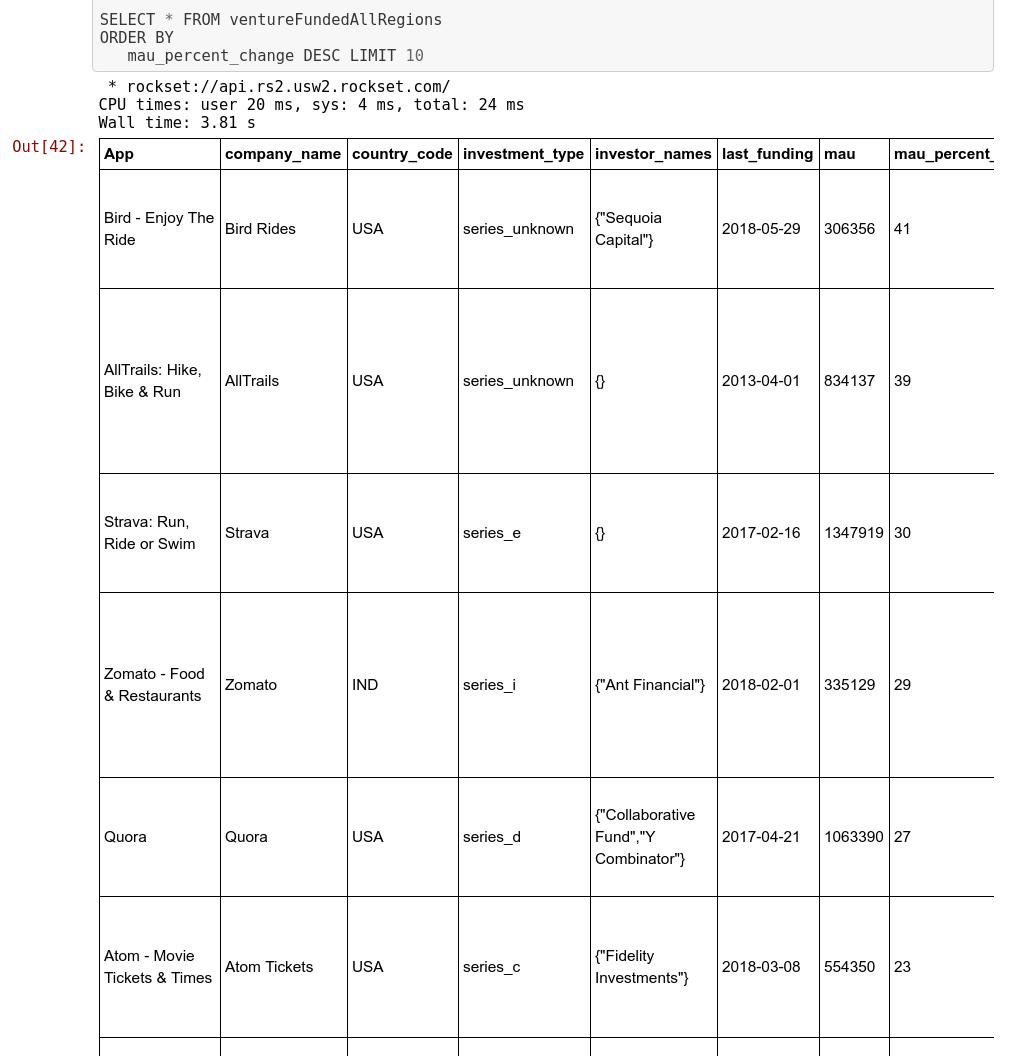
As we see above, we get knowledge that may assist with choice making from an funding perspective. We began with purposes which have posted important development in lively customers month over month. Then we carried out some filtering to impose some constraints to enhance the relevance of our record. Then we additionally extracted different particulars concerning the corporations that created these purposes and got here up with a last record of prospects above. On this complete course of, we didn’t make use of any ETL processes that remodel the information from one format to a different or wrangle it. The final question which was the longest took lower than 4 seconds to run, resulting from Rockset’s indexing of all fields and utilizing these indexes to hurry up the person queries.

{kind=link}