
Once we launched the idea of knowledge observability 4 years in the past, it resonated with organizations that had unlocked new worth…and new issues because of the trendy knowledge stack.
Now, 4 years later, we’re seeing organizations grapple with the large potential…and large challenges posed by generative AI.
The reply immediately is identical because it was then: enhance knowledge product reliability by getting full context and visibility into your knowledge programs. Nonetheless, the programs and processes are evolving on this new AI period and so knowledge observability should evolve with them, too.
Maybe one of the simplest ways to consider it’s to think about AI one other knowledge product and knowledge observability because the dwelling, respiratory system that displays ALL of your knowledge merchandise. The necessity for reliability and visibility into what’s a very black field is simply as crucial for constructing belief in LLMs because it was in constructing belief for analytics and ML.
For GenAI specifically, this implies knowledge observability should prioritize decision, pipeline effectivity, and streaming/vector infrastructures. Let’s take a more in-depth have a look at what which means.
Going past anomalies
Software program engineers have lengthy since gotten a deal with on utility downtime, thanks partially to observability options like New Relic and Datadog (who by the best way simply reported a shocking quarter).
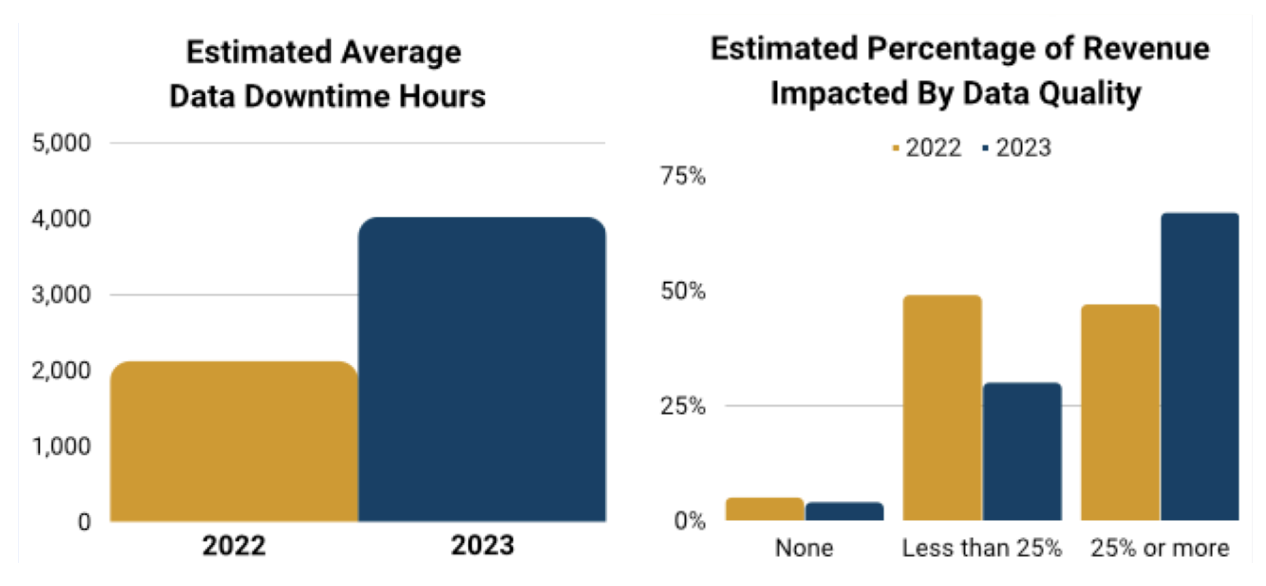
Knowledge groups, then again, just lately reported that knowledge downtime almost doubled 12 months over 12 months and that every hour was getting costlier.
Picture courtesy of Monte Carlo.
For contemporary software program purposes, reliability preceded adoption and worth era. Nobody would use a cell banking or navigation app that crashed each 4 hours.
Knowledge products-analytical, ML and AI applications-need to develop into simply as dependable as these purposes to really develop into enmeshed inside crucial enterprise operations. How?
Effectively, whenever you dig deeper into the knowledge downtime survey, a development begins to emerge: the typical time-to-resolution (as soon as detected) for an incident rose from 9 to fifteen hours.
In our expertise, most knowledge groups (maybe influenced by the frequent apply of knowledge testing) begin the dialog round detection. Whereas early detection is critically vital, groups vastly underestimate the importance of constructing incident triage and determination environment friendly. Simply think about leaping round between dozens of instruments making an attempt to hopelessly determine how an anomaly got here to be or whether or not it even issues. That usually finally ends up with fatigued groups that ignore alerts and undergo from knowledge downtime. We spent numerous time at Monte Carlo ensuring this does not occur to our clients.
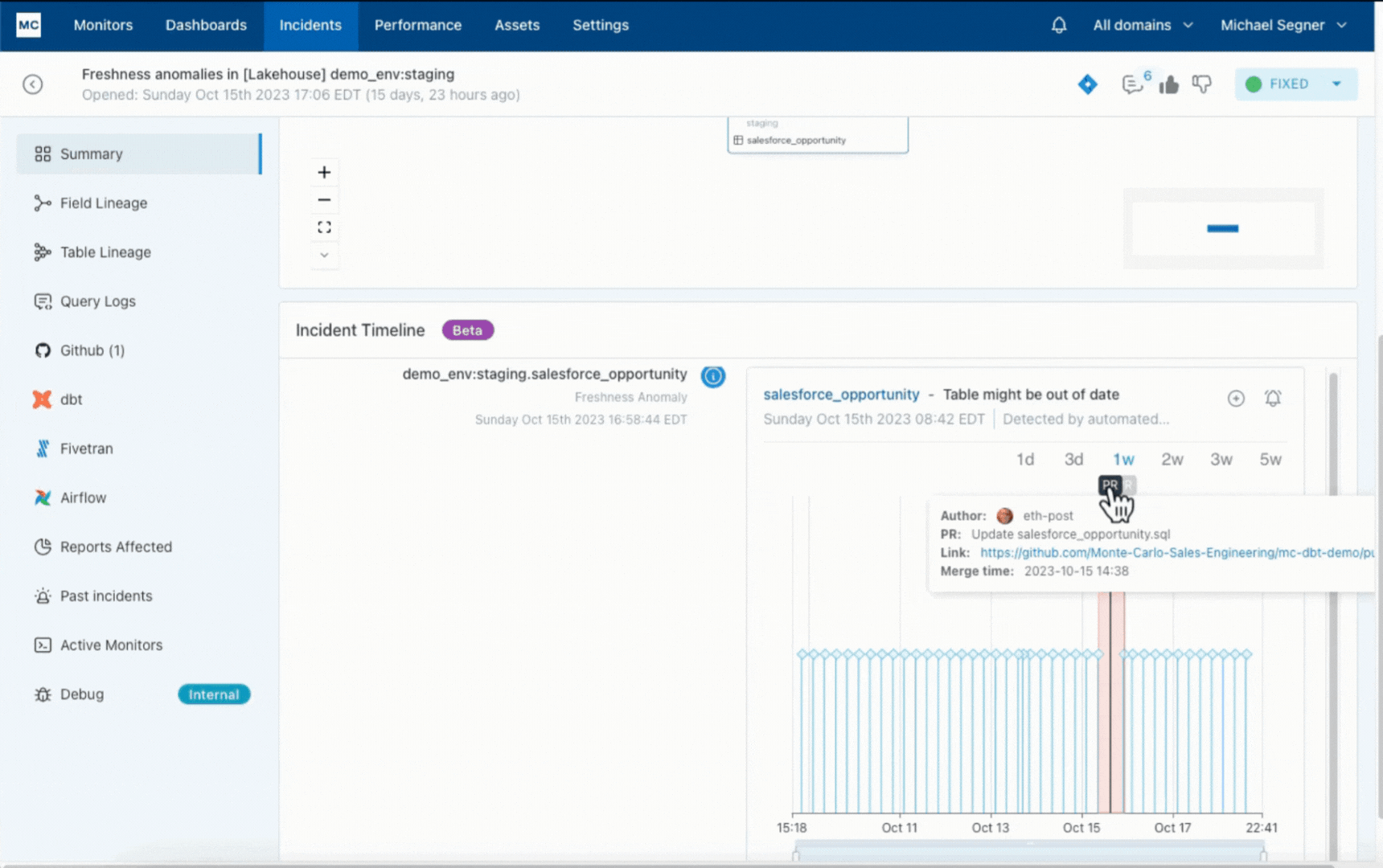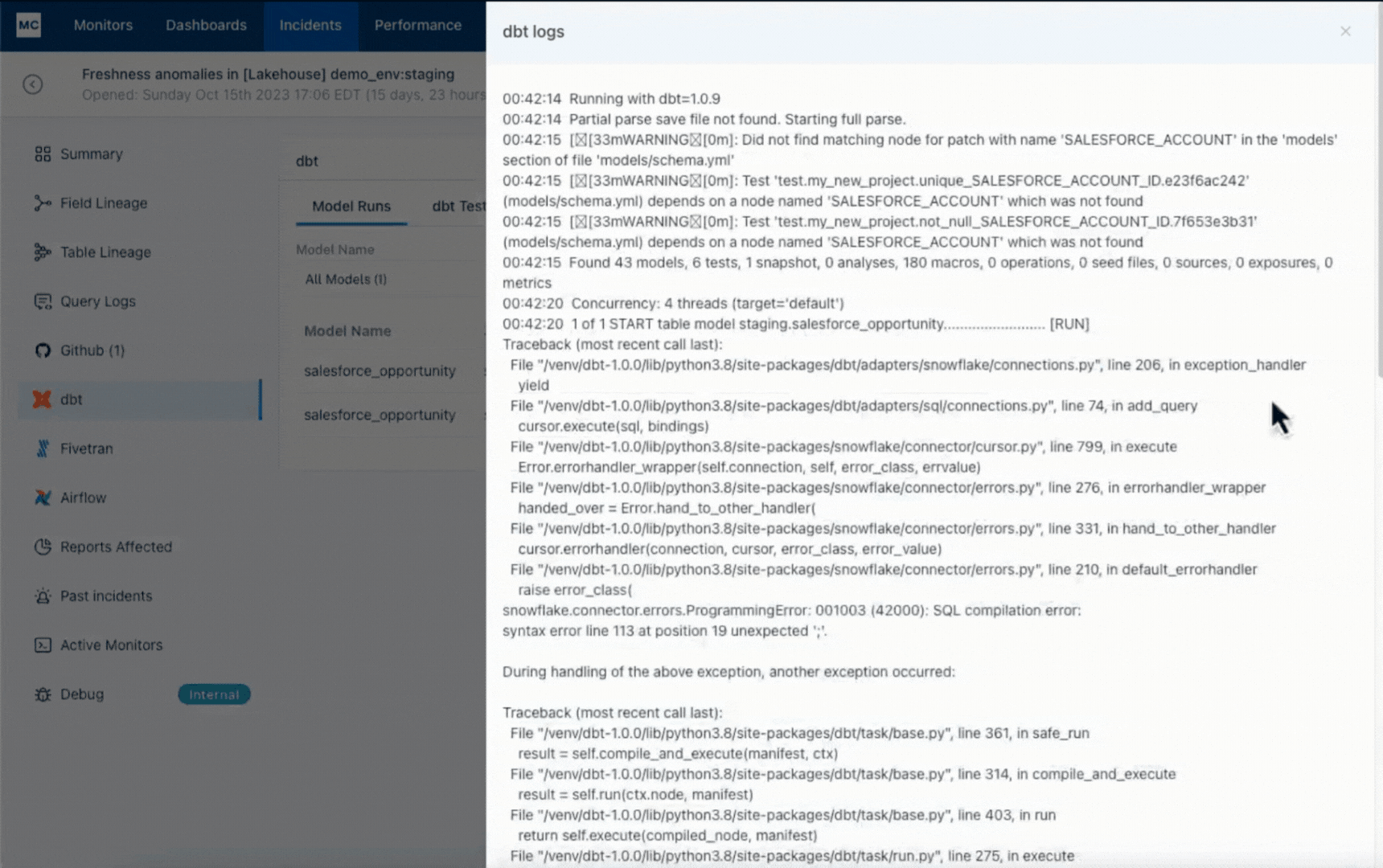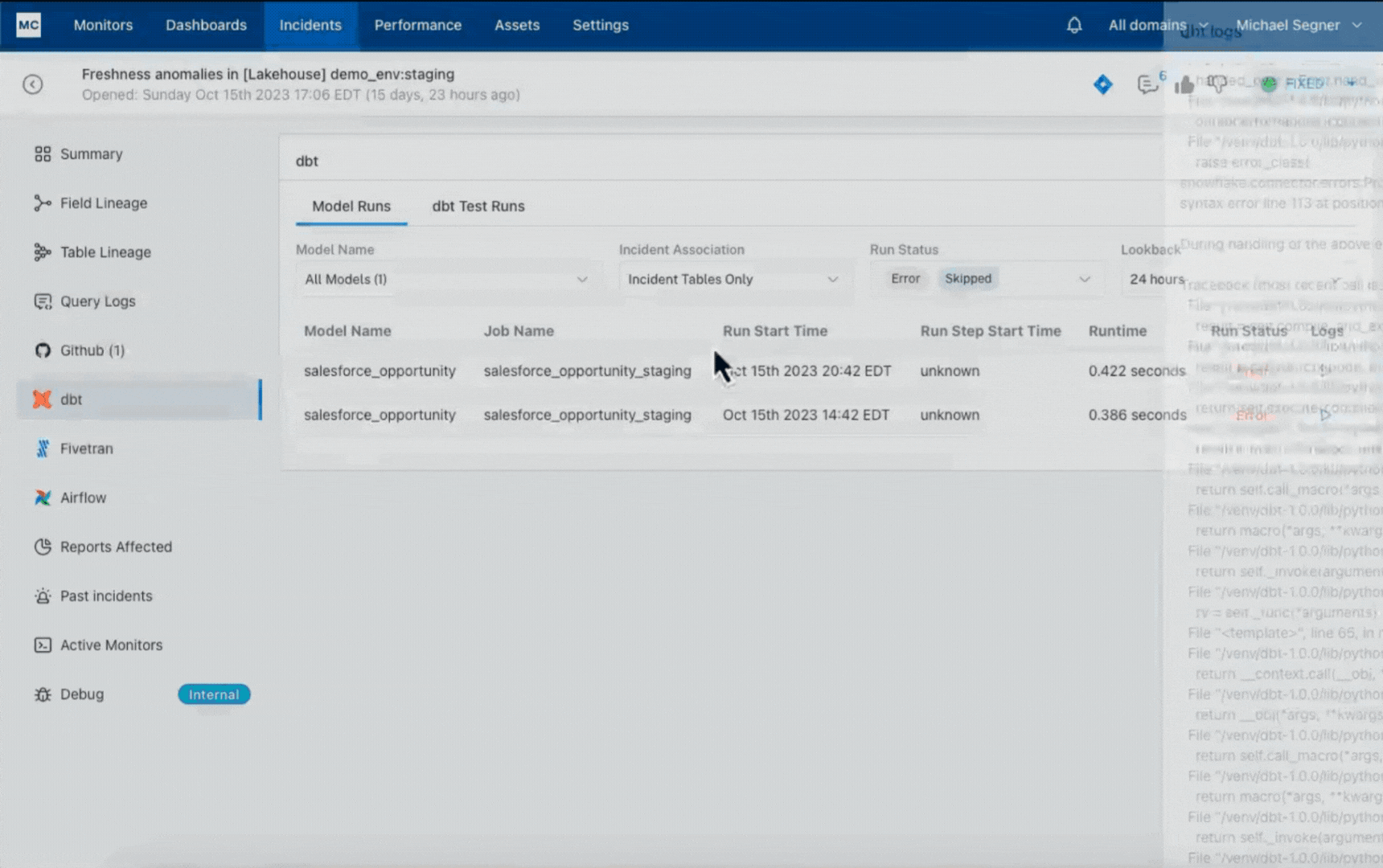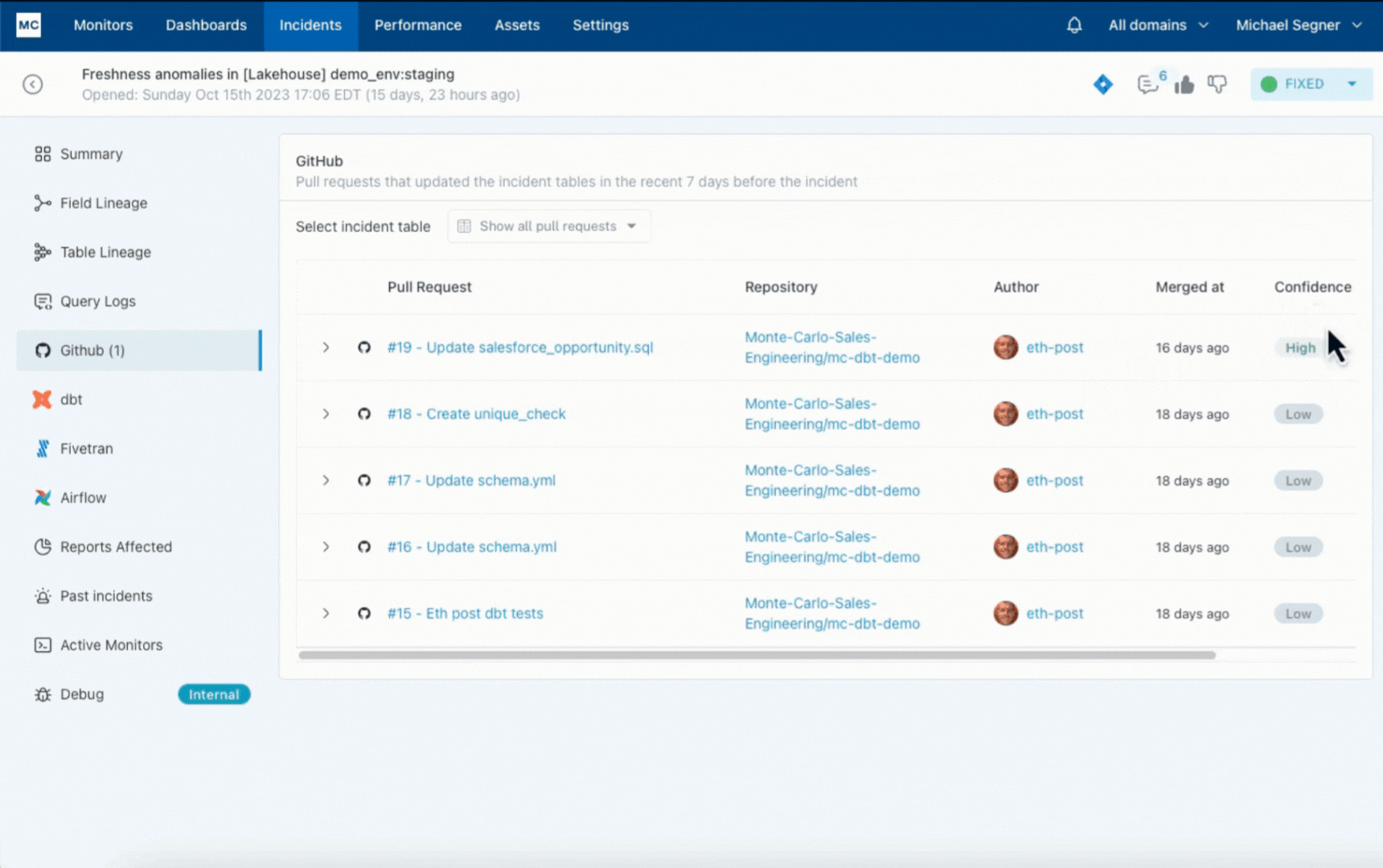 Monte Carlo has accelerated the foundation trigger evaluation of this knowledge freshness incident by correlating it to a dbt mannequin error ensuing from a GitHub pull request the place the mannequin code was incorrectly modified with the insertion of a semi-colon on line 113.
Monte Carlo has accelerated the foundation trigger evaluation of this knowledge freshness incident by correlating it to a dbt mannequin error ensuing from a GitHub pull request the place the mannequin code was incorrectly modified with the insertion of a semi-colon on line 113.
Knowledge observability is characterised by the power to speed up root trigger evaluation throughout knowledge, system, and code and to proactively set knowledge well being SLAs throughout the group, area, and knowledge product ranges.
The necessity for pace (and effectivity)
Knowledge engineers are going to be constructing extra pipelines sooner (thanks Gen AI!) and tech debt goes to be accumulating proper alongside it. Meaning degraded question, DAG, and dbt mannequin efficiency.
Gradual working knowledge pipelines price extra, are much less dependable, and ship poor knowledge shopper expertise. That will not reduce it within the AI period when knowledge is required as quickly as doable. Particularly not when the economic system is forcing everybody to take a even handed strategy with expense.
Meaning pipelines have to be optimized and monitored for efficiency. Knowledge observability has to cater for it.
We constructed Efficiency to assist. It permits customers to set alerts for queries that run too lengthy or burn too many credit. Customers can then drill down to know how modifications to the code, DAG, partitioning, warehouse configuration and different elements might have contributed to the difficulty, serving to optimize the pipeline. It additionally delivers wealthy and highly effective analytics to assist determine the least performant and costliest bottlenecks in any atmosphere or dbt/Airflow DAG.
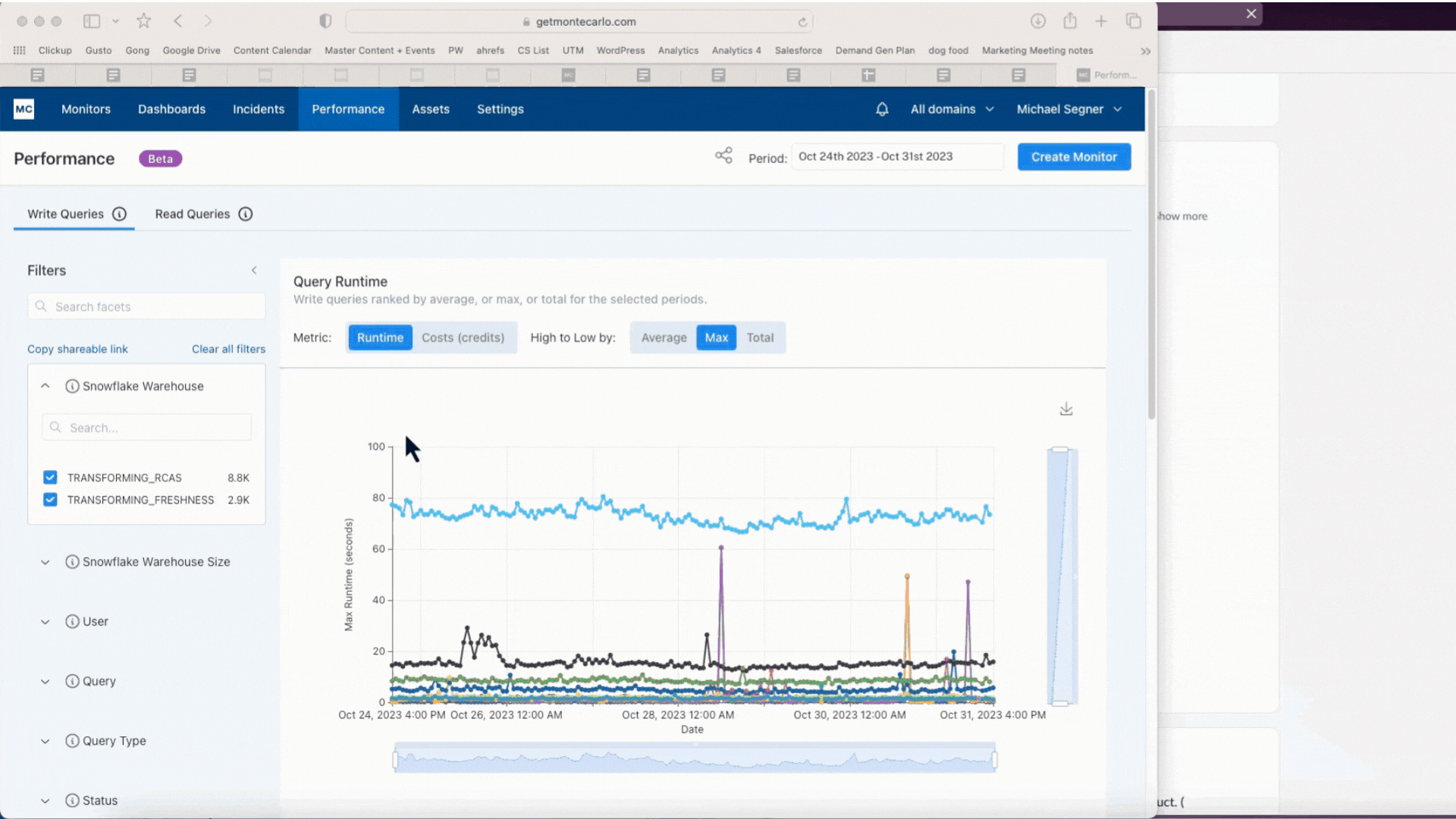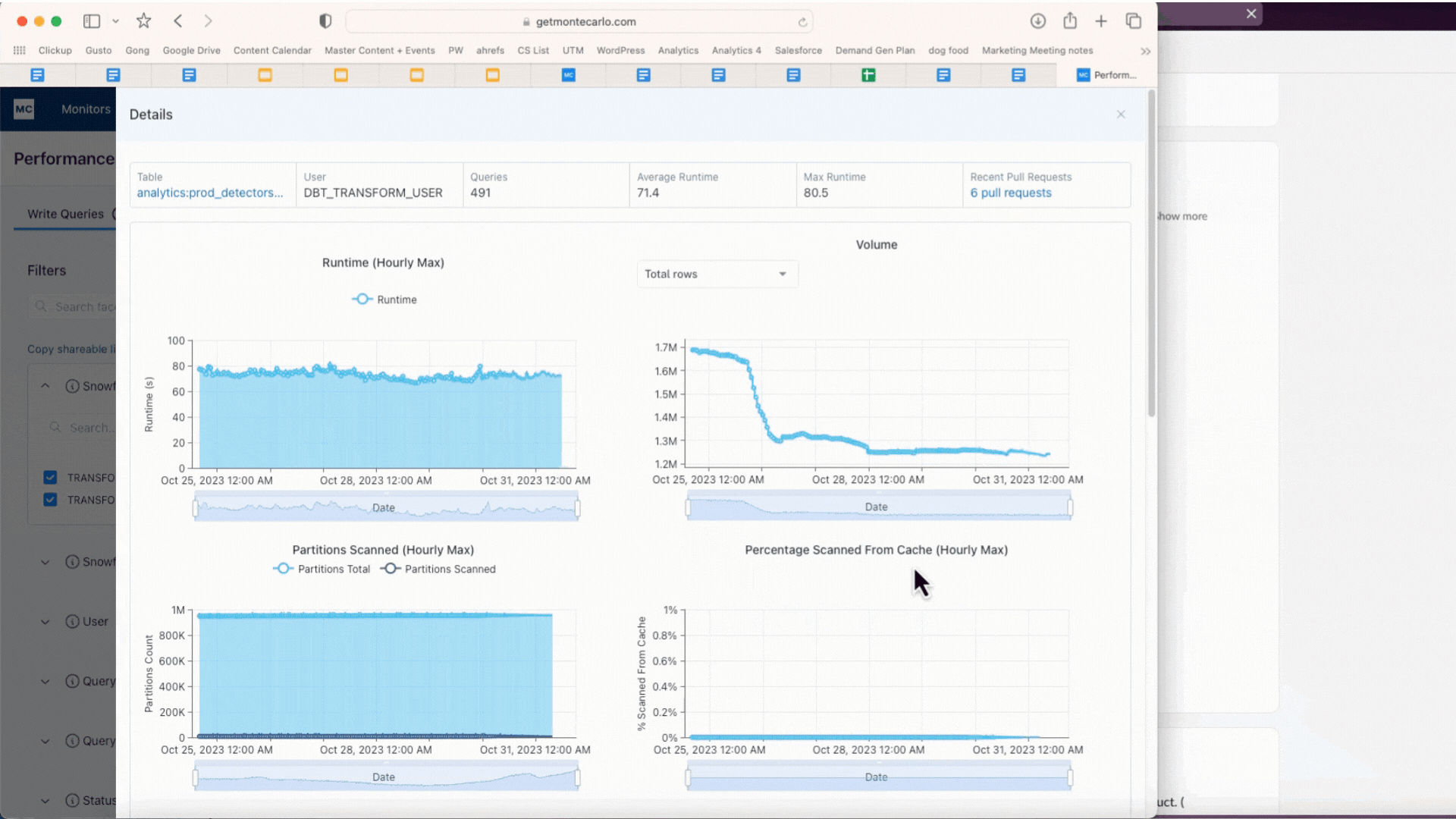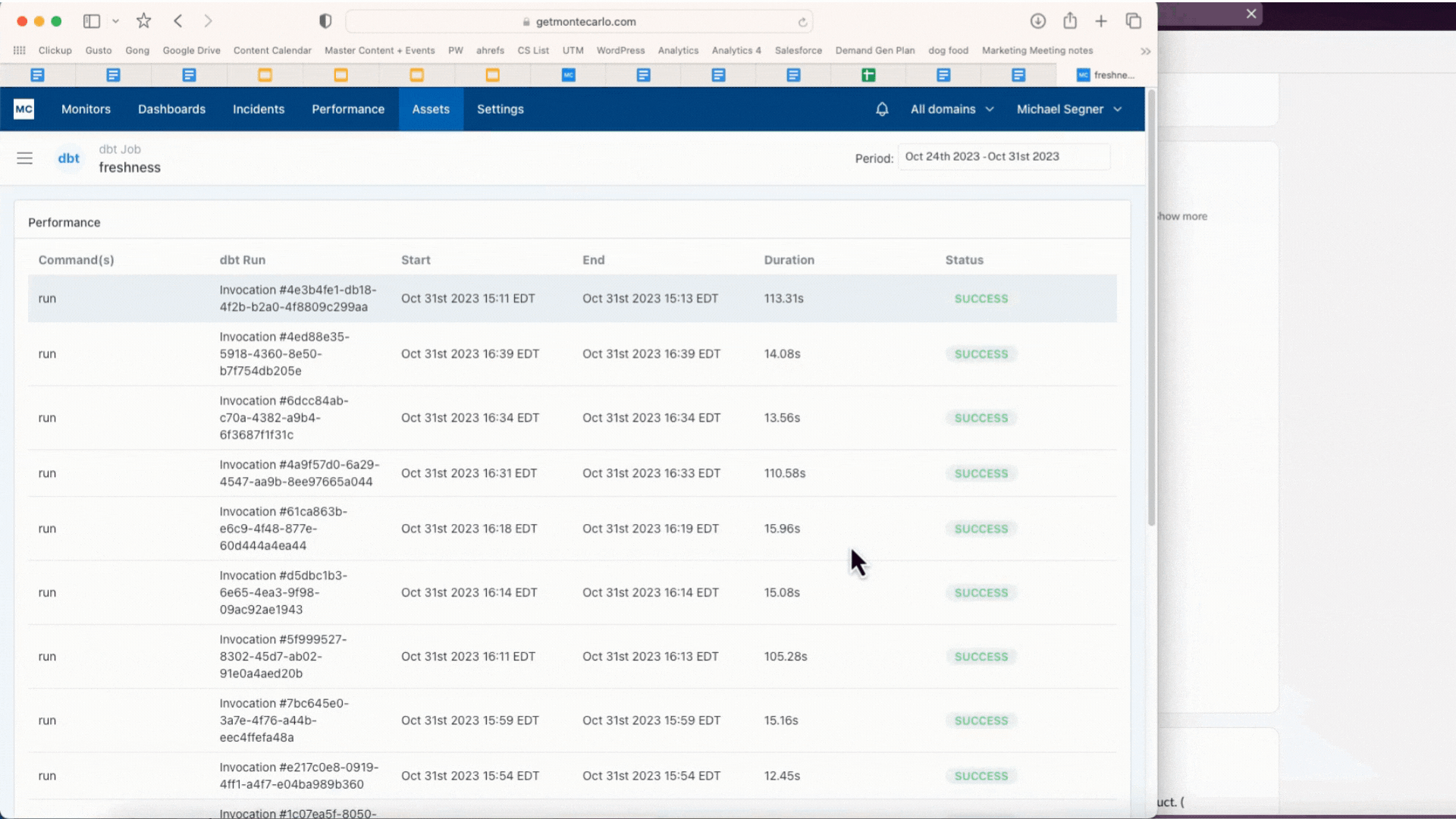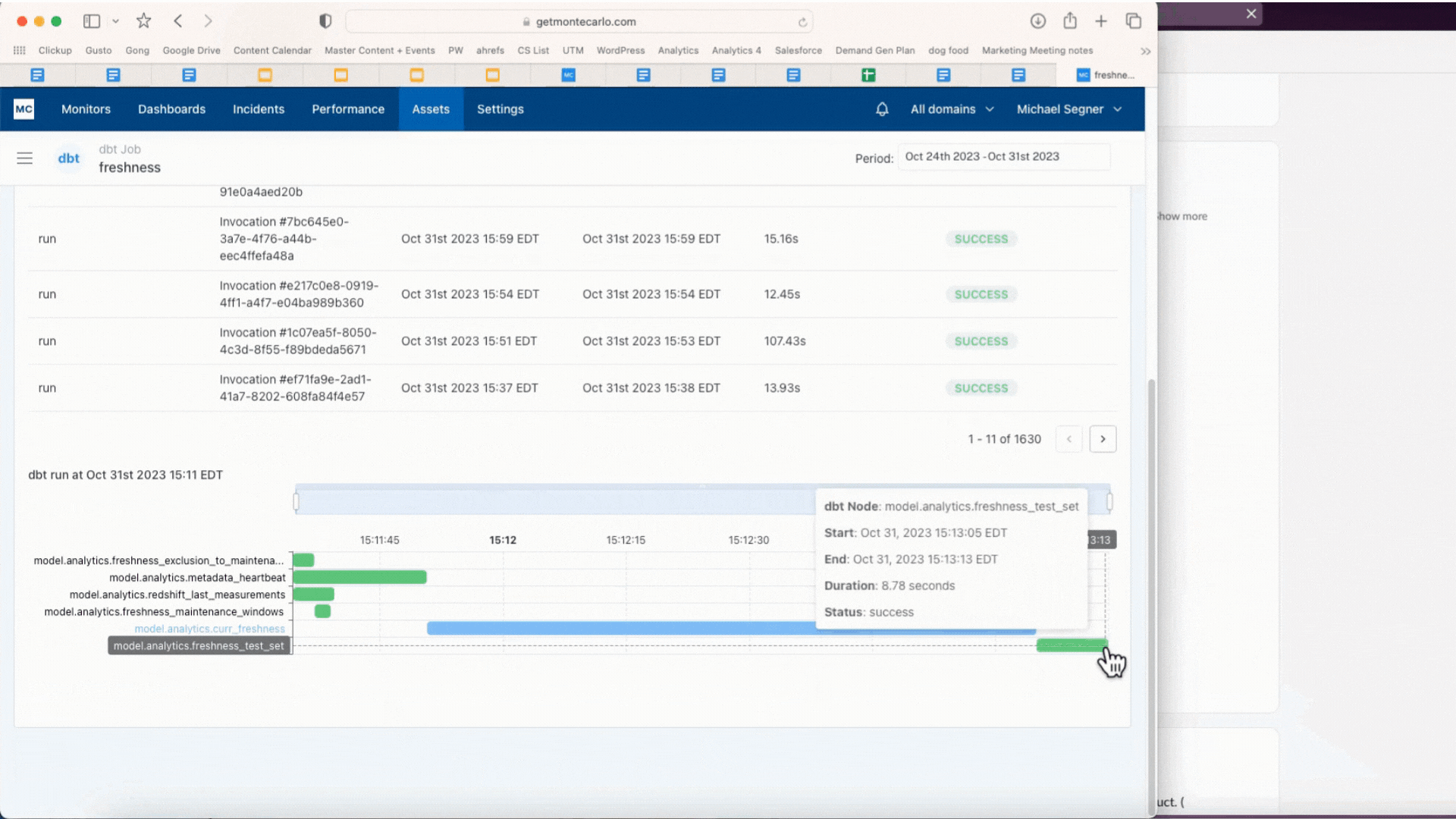 Figuring out a protracted working question which may be bottlenecking the bigger dbt job utilizing Efficiency. Picture courtesy of Monte Carlo.
Figuring out a protracted working question which may be bottlenecking the bigger dbt job utilizing Efficiency. Picture courtesy of Monte Carlo.
Observing the GenAI knowledge stack
This may shock nobody who has been within the knowledge engineering or machine studying area for the previous couple of years, however LLMs carry out higher in areas the place the knowledge is well-defined, structured, and correct.
To not point out, there are few enterprise issues to be solved that do not require at the very least some context of the enterprise. That is usually proprietary knowledge – whether or not it’s consumer ids, transaction historical past, transport instances or unstructured knowledge from inner paperwork, photographs and movies. These are usually held in a knowledge warehouse/lakehouse. I can not inform a Gen AI chatbot to cancel my order if it would not have any concept of who I’m, my previous interactions, or the corporate cancellation coverage.
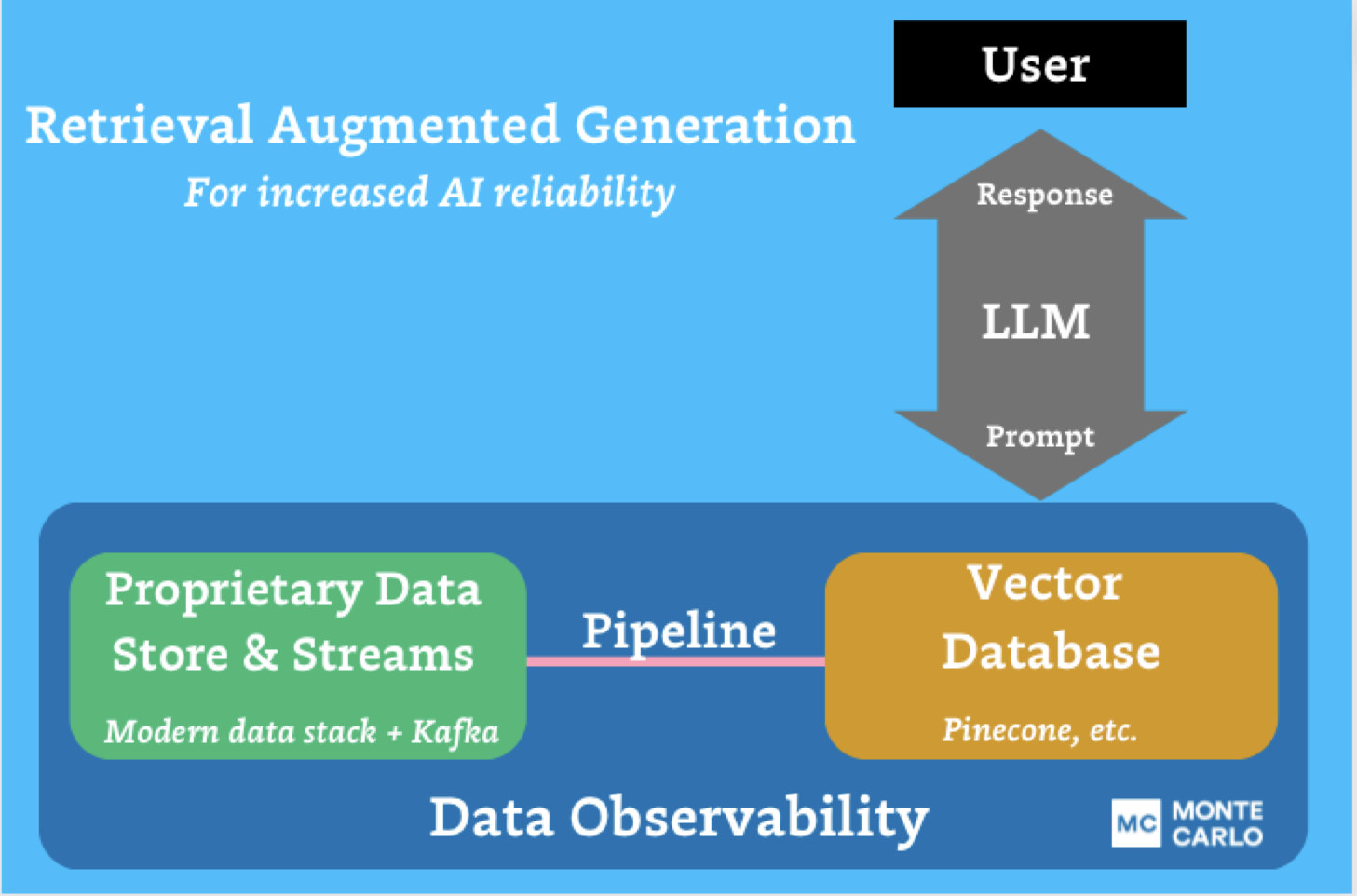
To resolve these challenges, organizations are usually turning to RAG or pre-training/effective tuning approaches, each of which require good and dependable knowledge pipelines. In an (oversimplified) nutshell, RAG includes offering the LLM further context by a database (oftentimes a vector database…) that’s commonly ingesting knowledge from a pipeline, whereas effective tuning or pre-training includes tailoring how the LLM performs on particular or specialised forms of requests by offering it a coaching corpus of comparable knowledge factors.
Knowledge observability wants to assist knowledge groups ship reliability and belief on this rising stack. Monte Carlo is main the best way by serving to to watch the pipelines utilized in RAG/effective tuning. To totally understand our imaginative and prescient of finish to finish protection of the stack knowledge groups use, we had been excited to announce upcoming direct assist for vector databases like Pinecone. This may be sure that knowledge groups can function dependable RAG architectures. We had been additionally proud to announce that, by the tip of the 12 months, Monte Carlo will combine with Apache Kafka by Confluent Cloud. This may allow knowledge groups to make sure that the traditionally tough to watch real-time knowledge feeding their AI and ML fashions is each correct and dependable for enterprise use instances.
Within the period of AI, knowledge engineering is extra vital than ever
Knowledge engineering has by no means been a slowly evolving subject. If we began speaking to you ten years in the past about Spark clusters you’d have politely nodded your head after which crossed the road.
To paraphrase a Greek knowledge engineer thinker, the one fixed is change. To this we’d add, the one constants in knowledge engineering are the everlasting necessities for extra. Extra knowledge, extra reliability, and extra pace (however at much less price please and thanks).
Gen AI shall be no completely different, and we see knowledge observability as a vital bridge to this future that’s immediately right here.
This text was initially printed right here.
The publish Knowledge Observability: Reliability In The AI Period appeared first on Datafloq.

{kind=link}