

Introduction
In conventional SQL techniques, a column’s kind is set when the desk is created, and by no means adjustments whereas executing a question. If you happen to create a desk with an integer-valued column, the values in that column will all the time be integers (or presumably NULL).
Rockset, nonetheless, is dynamically typed, which implies that we frequently do not know the kind of a worth till we really execute the question. That is just like different dynamically typed programming languages, the place the identical variable could comprise values of various varieties at totally different deadlines:
$ python3
>>> a = 3
>>> kind(a)
<class 'int'>
>>> a="foo"
>>> kind(a)
<class 'str'>
Rockset’s kind system was initially based mostly on JSON, and has since been prolonged to assist different varieties as nicely:
bytes: taking a cue from Python, we distinguish between sequences of legitimate Unicode characters (string, which is internally represented as UTF-8) and sequences of arbitrary bytes (bytes)- date- and time-specific varieties (
date,time,datetime,timestamp,microsecond_interval,month_interval)
There are different varieties that we use internally (and are by no means uncovered to our customers); additionally, the sort system is extensible, with deliberate assist for decimal (base-10 floating-point), geometry / geography varieties, and others.
Within the following instance, assortment ivtest has paperwork containing one subject a, which takes quite a lot of varieties:
$ rock create assortment ivtest
Assortment "ivtest" was created efficiently in workspace "commons".
$ cat /tmp/a.docs
{"a": 2}
{"a": "good day"}
{"a": null}
{"a": {"b": 10}}
{"a": [2, "foo"]}
$ rock add ivtest /tmp/a.docs
{
"file_name":"a.docs",
"file_upload_id":"c5ccc261-0096-4a73-8dfe-d6db8b8d130e",
"uploaded_at":"2019-06-05T18:12:46Z"
}
$ rock sql
> choose typeof(a), a from ivtest order by a;
+-----------+------------+
| ?typeof | a |
|-----------+------------|
| null_type | <null> |
| int | 2 |
| string | good day |
| array | [2, 'foo'] |
| object | {'b': 10} |
+-----------+------------+
Time: 0.014s
This publish exhibits certainly one of many challenges that we encountered whereas constructing a totally dynamically typed SQL database: how we manipulate values of unknown varieties in our question execution backend (written in C++), whereas approaching the efficiency of utilizing native varieties immediately.
At first, we used protocol buffers just like the definition beneath (simplified to solely present integers, floats, strings, arrays, and objects; the precise oneof that we use has a number of further fields):
message Worth {
oneof value_union {
int64 int_value = 1;
double float_value = 2;
string string_value = 3;
ArrayValue array_value = 4;
ObjectValue object_value = 5;
}
}
message ArrayValue {
repeated Worth values = 1;
}
message ObjectValue {
repeated KeyValue kvs = 1;
}
message KeyValue {
string key = 1;
Worth worth = 2;
}
However we rapidly realized that that is inefficient, each by way of velocity and by way of reminiscence utilization. First, protobuf requires a heap reminiscence allocation for each object; making a Worth that accommodates an array of 10 integers would carry out:
- a reminiscence allocation for the top-level
Worth - an allocation for the
array_valuemember - an allocation for the listing of values (
ArrayValue.values, which is aRepeatedPtrField) - an allocation for every of the ten values within the array
for a complete of 13 reminiscence allocations.
Additionally, the ten values within the array should not allotted contiguously in reminiscence, which causes an additional lower in efficiency because of cache locality.
It was rapidly clear that we would have liked one thing higher, which we known as IValue. In comparison with the protobuf model, IValue is:
- Extra reminiscence environment friendly: whereas not as environment friendly as utilizing native varieties immediately,
IValueshould be small, and should keep away from heap allocations wherever doable.IValueis all the time 16 bytes, and doesn’t allocate heap reminiscence for integers, booleans, floating-point numbers, and brief strings. - Quicker: arrays of scalar
IValues are allotted contiguously in reminiscence, main to raised cache locality. This isn’t as environment friendly as utilizing native varieties immediately, however it’s a vital enchancment over protobuf.
Most of Rockset’s question execution engine operates on IValues (there are some components which have specialised implementation for particular varieties, and that is an space of lively enchancment).
We might wish to share an summary of the IValue design. Observe that IValue is optimized for Rockset’s wants and isn’t meant to be moveable — we use Linux and x86_64-specific methods, and assume a little-endian reminiscence format.
The concept is in itself not novel; the strategies that we use date again to at the least 1993, as surveyed in “Representing Kind Info in Dynamically Typed Languages”. We determined to make IValue 128 bits as a substitute of 64, because it permits us to keep away from heap allocations in additional instances (together with all 64-bit integers); utilizing the taxonomy outlined within the paper, IValue is a double-wrapper scheme with qualifiers.
Internally, IValue is represented as a 128-bit (16-byte) worth, consisting of:
- a 64-bit subject (known as
knowledge) - a 48-bit subject (known as
pointer, because it usually, however not all the time, shops a pointer) - two 8-bit discriminator fields (known as
tag0andtag1)

tag1 signifies the kind of the worth. tag0 is normally a subtype, and the which means of the opposite two fields adjustments relying on kind. The pointer subject is commonly a pointer to another knowledge construction, allotted on the heap, for the instances the place heap allocations cannot be prevented; as pointers are solely 48 bits on x86_64, we’re capable of match a pointer and the 2 discriminator fields in the identical uint64_t.
We acknowledge two kinds of IValues:
tag1 has bit 7 clear (tag1 < 0x80) for all quick values, and set (tag1 >= 0x80) for all non-immediate values. This enables us to tell apart between quick and non-immediate values in a short time, utilizing one easy bit operation. We will then copy, hash, and examine for equality quick values by treating them as a pair of uint64_t integers.
Scalar Varieties
The illustration for many scalar varieties is simple: tag0 is normally zero, tag1 identifies the sort, pointer is normally zero, and knowledge accommodates the worth.
SQL NULL is all zeros, which is handy (memset()ing a piece of reminiscence to zero makes it NULL when interpreted as IValue):

Booleans have knowledge = 0 for false and knowledge = 1 for true, tag1 = 0x01

Integers have the worth saved in knowledge (as int64_t) and tag1 = 0x02

And so forth. The layouts for different scalar varieties (floating level, date / time, and so on) are comparable.
Strings
We deal with character strings and byte strings equally; the worth of tag1 is the one distinction. For the remainder of the part, we’ll solely deal with character strings.
IValue strings are immutable, preserve the string’s size explicitly, and should not null-terminated. In keeping with our objective to attenuate heap allocations, IValue would not use any exterior reminiscence for brief strings (lower than 16 bytes).
As a substitute, we implement the small string optimization: we retailer the string contents (padded with nulls) within the knowledge, pointer, and tag0 fields; we retailer the string size within the tag1 subject: tag1 is 0x1n, the place n is the string’s size.
An empty string has tag1 = 0x10 and all different bytes zero:

And, for instance, the 11-byte string “Whats up world” has tag1 = 0x1b (notice the little-endian illustration; the byte 'H' is first):

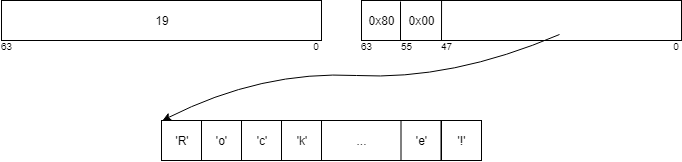
Strings longer than 15 bytes are saved out-of-line: tag1 is 0x80, pointer factors to the start of the string (allotted on the heap utilizing malloc()), and knowledge accommodates the string size. (There may be additionally the opportunity of referencing a “international” string, the place IValue would not personal the reminiscence however factors inside a preallocated buffer, however that’s past the scope of this publish.)
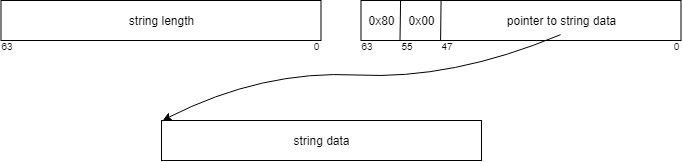
For instance, the 19-byte string “Rockset is superior!”:
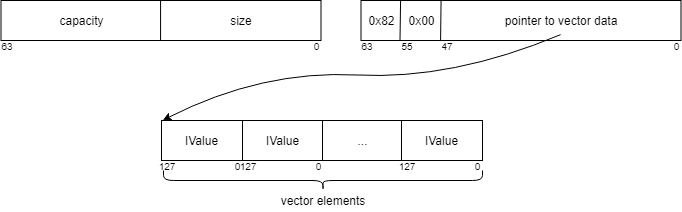
Vectors
Vectors (which we name “arrays”, adopting JSON’s terminology) are equally allotted on the heap: they’re just like vectors in most programming languages (together with C++’s std::vector). tag1 is 0x82, pointer factors to the start of the vector (allotted on the heap utilizing malloc()), and knowledge accommodates the vector’s measurement and capability (32 bits every). The vector itself is a contiguously allotted block of capability() IValues (capability() * 16 bytes); when reallocation is required, the vector grows exponentially (with an element that’s lower than 2, for the explanations described in Fb’s fbvector implementation.)
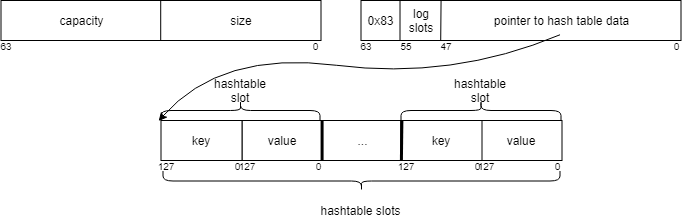
Hash Maps
Maps (which we name “objects”, adopting JSON’s terminology) are additionally allotted on the heap. We signify objects as open-addressing hash tables with quadratic probing; the scale of the desk is all the time an influence of two, which simplifies probing. We probe with triangular numbers, similar to Google’s sparsehash, which. as Knuth tells us in The Artwork of Laptop Programming (quantity 3, chapter 6.4, train 20), mechanically covers all slots.
Every hash desk slot is 32 bytes — two IValues, one for the important thing, one for the worth. As is normally the case with open-addressing hash tables, we’d like two particular keys — one to signify empty slots, and one to signify deleted parts (tombstones). We reserve two values of tag1 for that goal (0x06 and 0x05, respectively).
The pointer subject factors to the start of the hash desk (a contiguous array of slots, allotted on the heap utilizing malloc().) We retailer the present measurement of the hash desk within the least-significant 32 bits of the knowledge subject. The tag0 subject accommodates the variety of allotted slots (because it’s all the time an influence of two, we retailer log2(variety of slots) + 1, or zero if the desk is empty).
The capability subject (most vital 32 bits of knowledge) deserves additional curiosity: it’s the variety of slots accessible for storing person knowledge. Initially, it’s the identical as the entire variety of slots, however, as in all open-addressing hash tables, erasing a component from the desk marks the slot as “deleted” and renders it unusable till the following rehash. So erasing a component really decreases the desk’s capability.
Efficiency
IValue offers a considerable efficiency enchancment over the previous protobuf-based implementation:
- creating arrays of strings is between 2x and 7x sooner (relying on the string measurement; due to the small-string optimization,
IValueis considerably sooner for small strings) - creating arrays of integers can be 7x sooner (as a result of we not allocate reminiscence for each particular person array component)
- iterating over giant arrays of integers is 3x sooner (as a result of the values within the array are actually allotted contiguously)
Future Work
Though Rockset paperwork are allowed to comprise knowledge of a number of varieties in the identical subject, the state of affairs proven within the introduction is comparatively uncommon. In observe, a lot of the knowledge is of the identical kind (or NULL), and, to acknowledge this, we’re extending IValue to assist homogeneous arrays.
All parts in a homogeneous array are of the identical kind (or NULL). The construction is just like the common (heterogeneous) arrays (described above), however the pointer subject factors on to an array of the native kind (int64_t for an array of integers, double for an array of floating-point values, and so on). Much like techniques like Apache Arrow, we additionally preserve an non-obligatory bitmap that signifies whether or not a particular worth is NULL or not.
The question execution code acknowledges the frequent case the place it produces a column of values of the identical kind, through which case it can generate a homogeneous array. Now we have environment friendly, vectorized implementations of frequent database operations on homogeneous arrays, permitting us vital efficiency enhancements within the frequent case.
That is nonetheless an space of lively work, and benchmark outcomes are forthcoming.
Conclusion
We hope that you simply loved a quick look below the hood of Rockset’s engine. Sooner or later, we’ll share extra particulars about our approaches to constructing a totally dynamically typed SQL database; if you would like to provide us a attempt, join an account; if you would like to assist construct this, we’re hiring!

{kind=link}