

In right this moment’s data-driven world, organizations face the problem of successfully ingesting and processing information at an unprecedented scale. With the quantity and number of business-critical information continuously being generated, the architectural prospects are practically infinite – and that may be overwhelming. The excellent news? This additionally means there may be all the time potential to optimize your information structure additional – for throughput, latency, value, and operational effectivity.
Many information professionals affiliate phrases like “information streaming” and “streaming structure” with hyper-low-latency information pipelines that appear complicated, pricey, and impractical for many workloads. Nevertheless, groups that make use of a streaming information structure on the Databricks Lakehouse Platform virtually all the time profit from improved throughput, much less operational overhead, and drastically decreased prices. A few of these customers function at real-time, subsecond latency; whereas others run jobs as sometimes as as soon as per day. Some assemble their very own Spark Structured Streaming pipelines; others use DLT pipelines, a declarative strategy constructed on Spark Structured Streaming the place all of the infrastructure and operational overhead is routinely managed (many groups use a mixture of each).
It doesn’t matter what your workforce’s necessities and SLAs are, we’re keen to guess a lakehouse streaming structure for centralized information processing, information warehousing, and AI will ship extra worth than different approaches. On this weblog we’ll talk about widespread architectural challenges, how Spark Structured Streaming is particularly designed to handle them, and why the Databricks Lakehouse Platform affords the perfect context for operationalizing a streaming structure that saves money and time for information groups right this moment.
Transitioning from Batch to Streaming
Historically, information processing was completed in batches, the place information was collected and processed at scheduled intervals. Nevertheless, this strategy is not enough within the age of massive information, the place information volumes, velocity, and selection proceed to develop exponentially. With 90% of the world’s information generated within the final two years alone, the standard batch processing framework struggles to maintain tempo.
That is the place information streaming comes into play. Streaming architectures allow information groups to course of information incrementally because it arrives, eliminating the necessity to anticipate a big batch of knowledge to build up. When working at terabyte and petabyte scales, permitting information to build up turns into impractical and dear. Streaming has provided a imaginative and prescient and a promise for years that right this moment it’s lastly in a position to ship on.
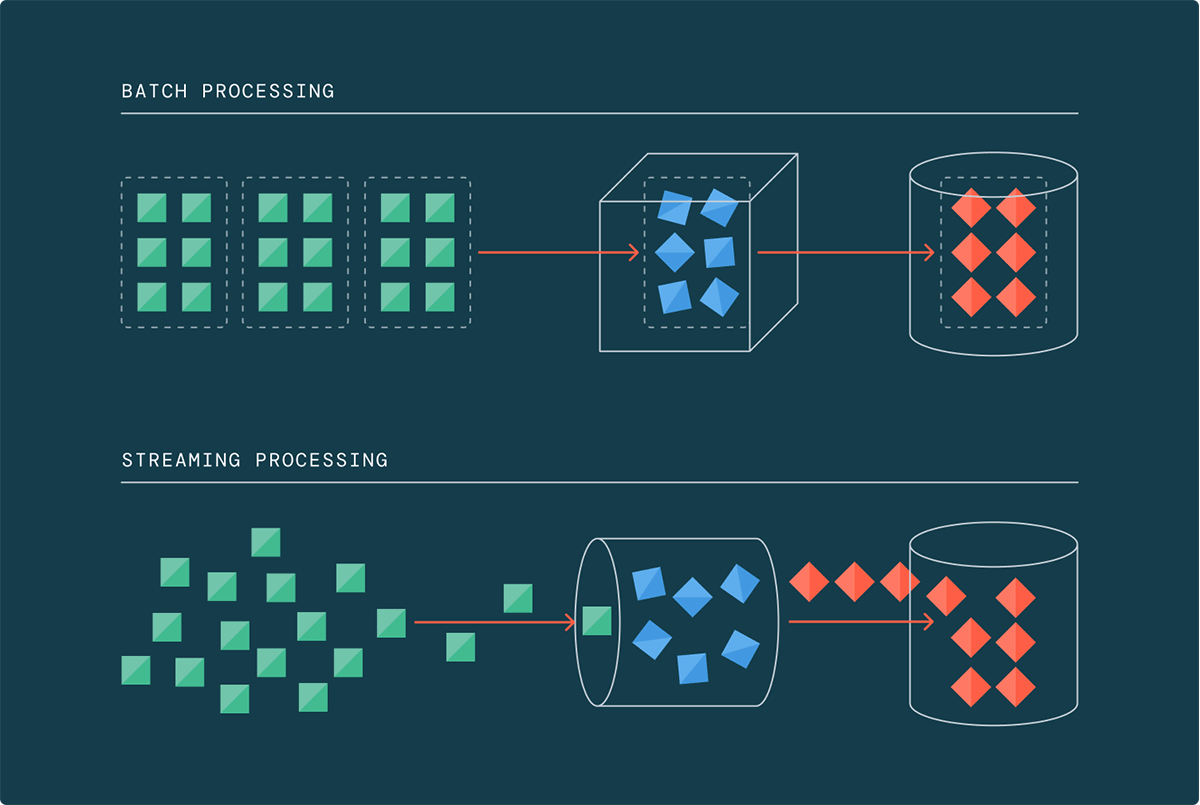
Rethinking Widespread Use Instances: Streaming Is the New Regular
The world is more and more reliant on real-time information, and information freshness could be a vital aggressive benefit. However, the brisker you need your information, the dearer it usually turns into. We discuss to a whole lot of prospects who categorical a want for his or her pipelines to be “as real-time as potential” – however once we dig into their particular use case, it seems they might be lots glad to cut back their pipeline runs from 6 hours to beneath quarter-hour. Different prospects actually do want latency that you could solely measure in seconds or milliseconds.

Moderately than categorizing use circumstances as batch or streaming, it is time to view each workload by means of the lens of streaming structure. Consider it as a single slider that may be adjusted to optimize for efficiency at one finish, or for value effectivity on the different. In essence, streaming lets you set the slider to the optimum place for every workload, from ultra-low latency to minutes and even hours.
Our very personal Dillon Bostwick stated it higher than I ever might: “We should get out of the mindset of reserving streaming for complicated “real-time” use circumstances. As an alternative, we must always use it for “Proper-time processing.”

Spark Structured Streaming affords a unified framework that allows you to modify this slider, offering a large aggressive benefit for companies and information engineers. Information freshness can adapt to satisfy enterprise necessities with out the necessity for vital infrastructure adjustments.
Opposite to many in style definitions, information streaming doesn’t all the time imply steady information processing. Streaming is basically incrementalization. You’ll be able to select when to allow incremental processing – all the time on or triggered at particular intervals. Whereas streaming is sensible for ultra-fresh information, it is also relevant to information historically thought of as batch.
Future-Proofing With Streaming on the Lakehouse
Take into account future-proofing your information structure. Streaming architectures provide flexibility to regulate latency, value, or throughput necessities as they evolve. Listed here are some advantages of totally streaming architectures and why Spark Structured Streaming on the Databricks Lakehouse Platform is designed for them:
- Scalability and throughput: Streaming architectures inherently scale and deal with various information volumes with out main infrastructure adjustments. Spark Structured Streaming excels in scalability and efficiency, particularly on high of Databricks leveraging Photon.
For a lot of use circumstances, so long as groups are hitting an appropriate latency SLA, the power to deal with excessive throughput is much more vital. Spark Structured Streaming can hit subsecond latency at thousands and thousands of occasions per second, which is why enterprises like AT&T and Akamai which can be often dealing with petabytes of knowledge belief Databricks for his or her streaming workloads.
“Databricks has helped Comcast scale to processing billions of transactions and terabytes of [streaming] information day-after-day.”
— Jan Neumann, VP Machine Studying, Comcast“Delta Reside Tables has helped our groups save effort and time in managing information on the multi-trillion-record scale and constantly bettering our AI engineering functionality.”
— Dan Jeavons, GM Information Science, Shell“We did not need to do something to get DLT to scale. We give the system extra information, and it copes. Out of the field, it is given us the arrogance that it’ll deal with no matter we throw at it.”
— Dr. Chris Inkpen, World Options Architect, Honeywell - Simplicity: If you’re operating a batch job that performs incremental updates, you usually need to cope with determining what information is new, what it’s best to course of, and what you shouldn’t. Structured Streaming already does all this for you, dealing with bookkeeping, fault tolerance, and stateful operations, offering an “precisely as soon as” assure with out guide oversight. Organising and operating streaming jobs, notably by means of Delta Reside Tables, is extremely simple.
“With the Databricks Lakehouse Platform, the precise streaming mechanics have been abstracted away… this has made ramping up on streaming a lot less complicated.”
— Pablo Beltran, Software program Engineer, Statsig“I like Delta Reside Tables as a result of it goes past the capabilities of Auto Loader to make it even simpler to learn information. My jaw dropped once we had been in a position to arrange a streaming pipeline in 45 minutes… we simply pointed the answer at a bucket of knowledge and had been up and operating.”
— Kahveh Saramout, Senior Information Engineer, Labelbox“DLT is the best approach to create a consumption information set; it does all the pieces for you. We’re a smaller workforce, and DLT saves us a lot time.”
— Ivo Van de Grift, Information Staff Tech Lead, Etos (an Ahold-Delhaize model) - Information Freshness for Actual-Time Use Instances: Streaming architectures guarantee up-to-date information, an important benefit for real-time decision-making and anomaly detection. To be used circumstances the place low latency is essential, Spark Structured Streaming (and by extension, DLT pipelines) can ship inherent subsecond latency at scale.
Even use circumstances that do not require ultra-low latency can profit from decreased latency variability. Streaming architectures present extra constant processing occasions, making it simpler to satisfy service-level agreements and guarantee predictable efficiency. Spark Structured Streaming on Databricks lets you configure the precise latency/throughput/value tradeoff that is proper on your use case.
“Our enterprise necessities demanded elevated freshness of knowledge, which solely a streaming structure might present.”
— Parveen Jindal, Software program Engineering Director, Vizio“We use Databricks for high-speed information in movement. It actually helps us rework the velocity at which we are able to reply to our sufferers’ wants both in-store or on-line.”
— Sashi Venkatesan, Product Engineering Director, Walgreens“We have seen main enhancements within the velocity now we have information accessible for evaluation. We now have a lot of jobs that used to take 6 hours and now take solely 6 seconds.”
— Alessio Basso, Chief Architect, HSBC - Price Effectivity: Almost each buyer we discuss to who migrates to a streaming structure with Spark Structured Streaming or DLT on Databricks realizes instantaneous and vital value financial savings. Adopting streaming architectures can result in vital value financial savings, particularly for variable workloads. With Spark Structured Streaming, you solely eat sources when processing information, eliminating the necessity for devoted clusters for batch processing.
Prospects utilizing DLT pipelines understand much more value financial savings from elevated improvement velocity and drastically decreased time spent managing operational trivialities like deployment infrastructure, dependency mapping, model management, checkpointing and retries, backfill dealing with, governance, and so forth.
“As extra real-time and high-volume information feeds had been activated for consumption [on Databricks], ETL/ELT prices elevated at a proportionally decrease and linear fee in comparison with the ETL/ELT prices of the legacy Multi Cloud Information Warehouse.”
— Sai Ravuru, Senior Supervisor of Information Science & Analytics, JetBlue“The most effective half is that we’re in a position to do all of this extra cost-efficiently. For a similar value as our earlier multi-cloud information warehouse, we are able to work quicker, extra collaboratively, extra flexibly, with extra information sources, and at scale.”
“Our focus to optimize worth/efficiency was met head-on by Databricks… infrastructure prices are 34% decrease than earlier than, and there is been a 24% value discount in operating our ETL pipelines as nicely. Extra importantly, our fee of experimentation has improved tremendously.”
— Mohit Saxena, Co-founder and Group CTO, InMobi - Unified Governance Throughout Actual-Time and Historic Information: Streaming architectures centralized on the Databricks Lakehouse Platform are the one approach to simply guarantee unified governance throughout real-time and historic information. Solely Databricks contains Unity Catalog, the trade’s first unified governance answer for information and AI on the lakehouse. Governance by means of Unity Catalog accelerates information and AI initiatives whereas guaranteeing regulatory compliance in a simplified method, guaranteeing streaming pipelines and real-time purposes sit inside the broader context of a singularly ruled information platform.
“Doing all the pieces from ETL and engineering to analytics and ML beneath the identical umbrella removes boundaries and makes it simple for everybody to work with the info and one another.”
— Sergey Blanket, Head of Enterprise Intelligence, Grammarly“Earlier than we had assist for Unity Catalog, we had to make use of a separate course of and pipeline to stream information into S3 storage and a special course of to create a knowledge desk out of it. With Unity Catalog integration, we are able to streamline, create and handle tables from the DLT pipeline immediately.”
— Yue Zhang, Workers Software program Engineer, Block“Databricks has helped Columbia’s EIM workforce speed up ETL and information preparation, attaining a 70% discount in ETL pipeline creation time whereas lowering the period of time to course of ETL workloads from 4 hours to solely 5 minutes… Extra enterprise items are utilizing it throughout the enterprise in a self-service method that was not potential earlier than. I can not say sufficient in regards to the constructive impression that Databricks has had on Columbia.”
Streaming architectures put together your information infrastructure for evolving wants as information era continues to speed up. By getting ready for real-time information processing now, you may be higher geared up to deal with rising information volumes and evolving enterprise wants. In different phrases – you’ll be able to simply tweak that slider in case your latency SLAs evolve, somewhat than having to rearchitect.
Getting Began with Databricks for Streaming Architectures
There are a number of causes that over 2,000 prospects are operating greater than 10 million weekly streaming jobs on the Databricks Lakehouse Platform. Prospects belief Databricks for constructing streaming architectures as a result of:
- Not like a multi-cloud information warehouse, you’ll be able to really do streaming on Databricks – for streaming analytics, in addition to streaming ML and real-time apps.
- Not like Flink, it is (1) very simple, and (2) ALLOWS you to set the associated fee/latency slider nevertheless you want – everytime you need.
- Not like native public cloud options, it is one easy unified platform that does not require stitching collectively a number of companies.
- Not like another platform, it permits groups to decide on the implementation technique that is proper for them. They will construct their very own Spark Structured Streaming pipelines, or summary all of the operational complexity with Delta Reside Tables. In reality, many purchasers have a mixture of each throughout completely different pipelines.
Listed here are just a few methods to begin exploring streaming architectures on Databricks:
Takeaways
Streaming architectures have a number of advantages over conventional batch processing, and are solely turning into extra essential. Spark Structured Streaming lets you implement a future-proof streaming structure now and simply tune for value vs. latency. Databricks is the perfect place to run Spark workloads.
If your online business requires 24/7 streams and real-time analytics, ML, or operational apps, then run your clusters 24/7 with Structured Streaming in steady mode. If it does not, then use Structured Streaming’s incremental batch processing with Set off = AvailableNow. (See our documentation particularly round optimizing prices by balancing always-on and triggered streaming). Both means, think about DLT pipelines for automating a lot of the operational overhead.
In brief – in case you are processing a whole lot of information, you most likely have to implement a streaming structure. From once-a-day to once-a-second and beneath, Databricks makes it simple and saves you cash.

{kind=link}