

Ingesting a excessive quantity of streaming knowledge has been a defining attribute of operational analytics workloads with Amazon OpenSearch Service. Many of those workloads contain both self-managed Apache Kafka or Amazon Managed Streaming for Apache Kafka (Amazon MSK) to fulfill their knowledge streaming wants. Consuming knowledge from Amazon MSK and writing to OpenSearch Service has been a problem for purchasers. AWS Lambda, customized code, Kafka Join, and Logstash have been used for ingesting this knowledge. These strategies contain instruments that have to be constructed and maintained. On this submit, we introduce Amazon MSK as a supply to Amazon OpenSearch Ingestion, a serverless, totally managed, real-time knowledge collector for OpenSearch Service that makes this ingestion even simpler.
Answer overview
The next diagram reveals the circulate from knowledge sources to Amazon OpenSearch Service.
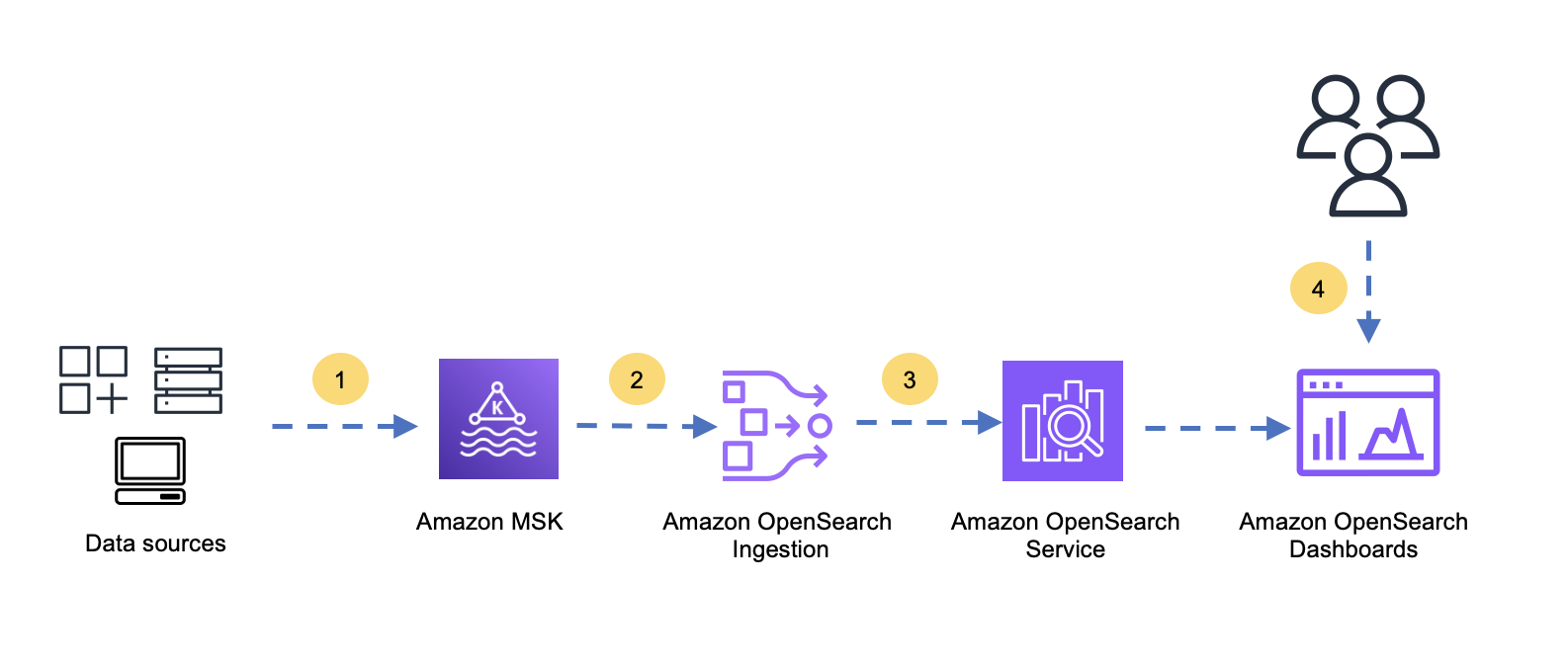
The circulate incorporates the next steps:
- Information sources produce knowledge and ship that knowledge to Amazon MSK
- OpenSearch Ingestion consumes the information from Amazon MSK.
- OpenSearch Ingestion transforms, enriches, and writes the information into OpenSearch Service.
- Customers search, discover, and analyze the information with OpenSearch Dashboards.
Conditions
You will want a provisioned MSK cluster created with acceptable knowledge sources. The sources, as producers, write knowledge into Amazon MSK. The cluster ought to be created with the suitable Availability Zone, storage, compute, safety and different configurations to fit your workload wants. To provision your MSK cluster and have your sources producing knowledge, see Getting began utilizing Amazon MSK.
As of this writing, OpenSearch Ingestion helps Amazon MSK provisioned, however not Amazon MSK Serverless. Nevertheless, OpenSearch Ingestion can reside in the identical or totally different account the place Amazon MSK is current. OpenSearch Ingestion makes use of AWS PrivateLink to learn knowledge, so it’s essential to activate multi-VPC connectivity in your MSK cluster. For extra info, see Amazon MSK multi-VPC non-public connectivity in a single Area. OpenSearch Ingestion can write knowledge to Amazon Easy Storage Service (Amazon S3), provisioned OpenSearch Service, and Amazon OpenSearch Service. On this resolution, we use a provisioned OpenSearch Service area as a sink for OSI. Discuss with Getting began with Amazon OpenSearch Service to create a provisioned OpenSearch Service area. You will want acceptable permission to learn knowledge from Amazon MSK and write knowledge to OpenSearch Service. The next sections define the required permissions.
Permissions required
To learn from Amazon MSK and write to Amazon OpenSearch Service, you must create a an AWS Id and Entry Administration (IAM) position utilized by Amazon OpenSearch Ingestion. On this submit we use a job known as pipeline-Position for this goal. To create this position please see Creating IAM roles.
Studying from Amazon MSK
OpenSearch Ingestion will want permission to create a PrivateLink connection and different actions that may be carried out in your MSK cluster. Edit your MSK cluster coverage to incorporate the next snippet with acceptable permissions. In case your OpenSearch Ingestion pipeline resides in an account totally different out of your MSK cluster, you will have a second part to permit this pipeline. Use correct semantic conventions when offering the cluster, subject, and group permissions and take away the feedback from the coverage earlier than utilizing.
Edit the pipeline position’s inline coverage to incorporate the next permissions. Guarantee that you’ve eliminated the feedback earlier than utilizing the coverage.
Writing to OpenSearch Service
On this part, you present the pipeline position with crucial permissions to jot down to OpenSearch Service. As a greatest apply, we suggest utilizing fine-grained entry management in OpenSearch Service. Use OpenSearch dashboards to map a pipeline position to an acceptable backend position. For extra info on mapping roles to customers, see Managing permissions. For instance, all_access is a built-in position that grants administrative permission to all OpenSearch capabilities. When deploying to a manufacturing setting, make sure that you employ a job with sufficient permissions to jot down to your OpenSearch area.

Creating OpenSearch Ingestion pipelines
The pipeline position now has the right set of permissions to learn from Amazon MSK and write to OpenSearch Service. Navigate to the OpenSearch Service console, select Pipelines, then select Create pipeline.
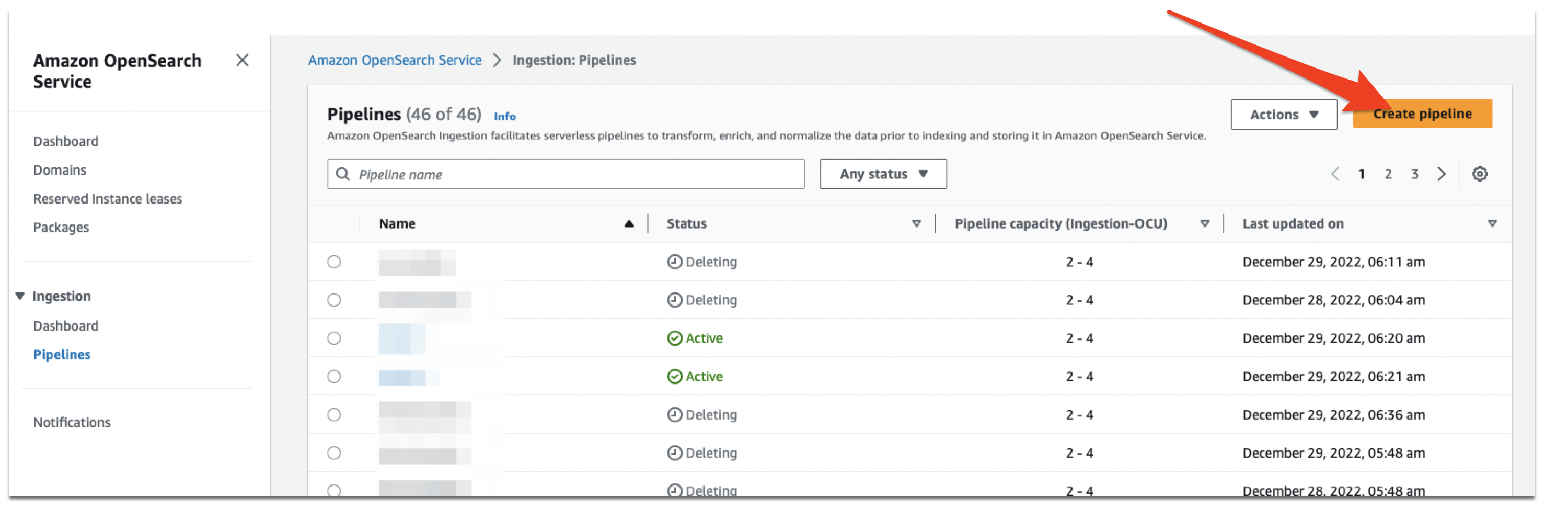
Select an appropriate title for the pipeline. and se the pipeline capability with acceptable minimal and most OpenSearch Compute Unit (OCU). Then select ‘AWS-MSKPipeline’ from the dropdown menu as proven under.
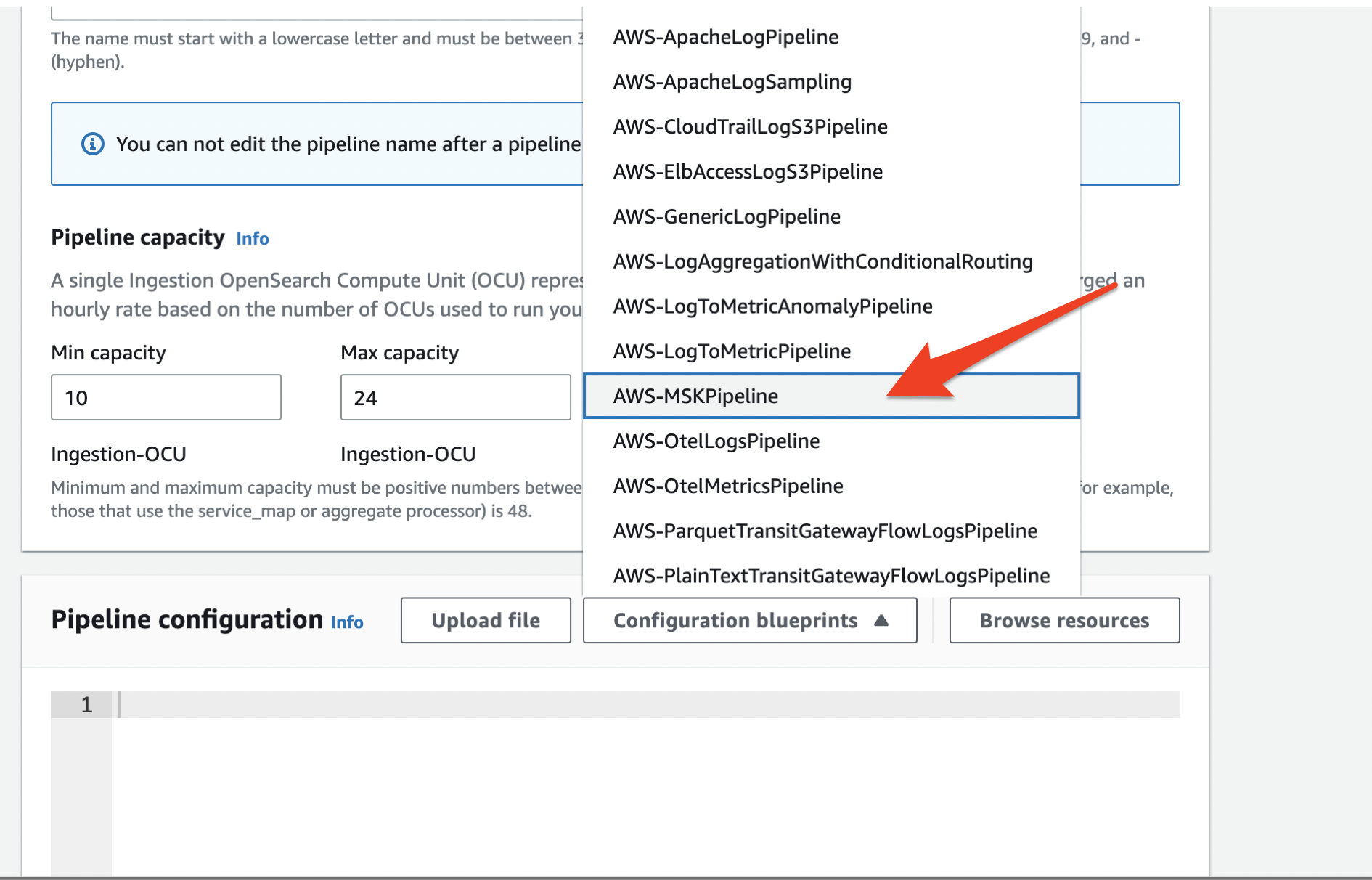
Use the offered template to fill in all of the required fields. The snippet within the following part reveals the fields that must be stuffed in pink.
Configuring Amazon MSK supply
The next pattern configuration snippet reveals each setting you must get the pipeline operating:
We use the next parameters:
- acknowledgements – Set to
truefor OpenSearch Ingestion to make sure that the information is delivered to the sinks earlier than committing the offsets in Amazon MSK. The default worth is ready to false. - title – This specifies subject OpenSearch Ingestion can learn from. You possibly can learn a most of 4 subjects per pipeline.
- group_id – This parameter specifies that the pipeline is a part of the buyer group. With this setting, a single shopper group may be scaled to as many pipelines as wanted for very excessive throughput.
- serde_format – Specifies a deserialization methodology for use for the information learn from Amazon MSK. The choices are JSON and plaintext.
- AWS sts_role_arn and OpenSearch sts_role_arn – Specifies the position OpenSearch Ingestion makes use of for studying and writing. Specify the ARN of the position you created from the final part. OpenSearch Ingestion at present makes use of the identical position for studying and writing.
- MSK arn – Specifies the MSK cluster to devour knowledge from.
- OpenSearch host and index – Specifies the OpenSearch area URL and the place the index ought to write.
When you could have configured the Kafka supply, select the community entry kind and log publishing choices. Public pipelines don’t contain PrivateLink and they won’t incur a price related to PrivateLink. Select Subsequent and evaluate all configurations. When you find yourself happy, select Create pipeline.
Log in to OpenSearch Dashboards to see your indexes and search the information.
Beneficial compute models (OCUs) for the MSK pipeline
Every compute unit has one shopper per subject. Brokers will stability partitions amongst these shoppers for a given subject. Nevertheless, when the variety of partitions is larger than the variety of shoppers, Amazon MSK will host a number of partitions on each shopper. OpenSearch Ingestion has built-in auto scaling to scale up or down primarily based on CPU utilization or variety of pending information within the pipeline. For optimum efficiency, partitions ought to be distributed throughout many compute models for parallel processing. If subjects have numerous partitions, for instance, greater than 96 (most OCUs per pipeline), we suggest configuring a pipeline with 1–96 OCUs as a result of it’ll auto scale as wanted. If a subject has a low variety of partitions, for instance, lower than 96, then maintain the utmost compute unit to similar because the variety of partitions. When pipeline has a couple of subject, person can decide a subject with highest variety of partitions as a reference to configure most computes models. By including one other pipeline with a brand new set of OCUs to the identical subject and shopper group, you may scale the throughput nearly linearly.
Clear up
To keep away from future costs, clear up any unused assets out of your AWS account.
Conclusion
On this submit, you noticed easy methods to use Amazon MSK as a supply for OpenSearch Ingestion. This not solely addresses the benefit of knowledge consumption from Amazon MSK, however it additionally relieves you of the burden of self-managing and manually scaling shoppers for various and unpredictable high-speed, streaming operational analytics knowledge. Please confer with the ‘sources’ listing underneath ‘supported plugins’ part for exhaustive listing of sources from which you’ll be able to ingest knowledge.
In regards to the authors
 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search purposes and options. Muthu is within the subjects of networking and safety, and relies out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search purposes and options. Muthu is within the subjects of networking and safety, and relies out of Austin, Texas.
 Arjun Nambiar is a Product Supervisor with Amazon OpenSearch Service. He focusses on ingestion applied sciences that allow ingesting knowledge from all kinds of sources into Amazon OpenSearch Service at scale. Arjun is involved in massive scale distributed techniques and cloud-native applied sciences and relies out of Seattle, Washington.
Arjun Nambiar is a Product Supervisor with Amazon OpenSearch Service. He focusses on ingestion applied sciences that allow ingesting knowledge from all kinds of sources into Amazon OpenSearch Service at scale. Arjun is involved in massive scale distributed techniques and cloud-native applied sciences and relies out of Seattle, Washington.
 Raj Sharma is a Sr. SDM with Amazon OpenSearch Service. He builds large-scale distributed purposes and options. Raj is within the subjects of Analytics, databases, networking and safety, and relies out of Palo Alto, California.
Raj Sharma is a Sr. SDM with Amazon OpenSearch Service. He builds large-scale distributed purposes and options. Raj is within the subjects of Analytics, databases, networking and safety, and relies out of Palo Alto, California.

{kind=link}