

Google, eBay, and others have the power to seek out “comparable” pictures. Have you ever ever questioned how this works? This functionality transcends what’s attainable with strange key phrase search and as an alternative makes use of semantic search to return comparable or associated pictures. This weblog will cowl a quick historical past of semantic search, its use of vectors, and the way it differs from key phrase search.
Creating Understanding with Semantic Search
Conventional textual content search embodies a elementary limitation: precise matching. All it might do is to examine, at scale, whether or not a question matches some textual content. Greater-end engines skate round this drawback with further tips like lemmatization and stemming, for instance equivalently matching “ship”, “despatched”, or “sending”, however when a specific question expresses an idea with a unique phrase than the corpus (the set of paperwork to be searched), queries fail and customers get pissed off. To place it one other approach, the search engine has no understanding of the corpus.
Our brains simply don’t work like search engines like google. We predict in ideas and concepts. Over a lifetime we progressively assemble a psychological mannequin of the world, all of the whereas setting up an inside panorama of ideas, info, notions, abstractions, and an internet of connections amongst them. Since associated ideas dwell “close by” on this panorama, it’s easy to recall one thing with a different-but-related phrase that also maps to the identical idea.
Whereas synthetic intelligence analysis stays removed from replicating human intelligence, it has produced helpful insights that make it attainable to carry out search at the next, or semantic stage, matching ideas as an alternative of key phrases. Vectors, and vector search, are on the coronary heart of this revolution.
From Key phrases to Vectors
A typical information construction for textual content search is a reverse index, which works very similar to the index behind a printed e book. For every related key phrase, the index retains an inventory of occurrences particularly paperwork from the corpus; then resolving a question entails manipulating these lists to compute a ranked record of matching paperwork.
In distinction, vector search makes use of a radically totally different approach of representing gadgets: vectors. Discover that the previous sentence modified from speaking about textual content to a extra generic time period, gadgets. We’ll get again to that momentarily.
What’s a vector? Merely an inventory or array of numbers–think, java.util.Vector for instance—however with emphasis on its mathematical properties. Among the many helpful properties of vectors, also referred to as embeddings, is that they kind an area the place semantically comparable gadgets are shut to one another.
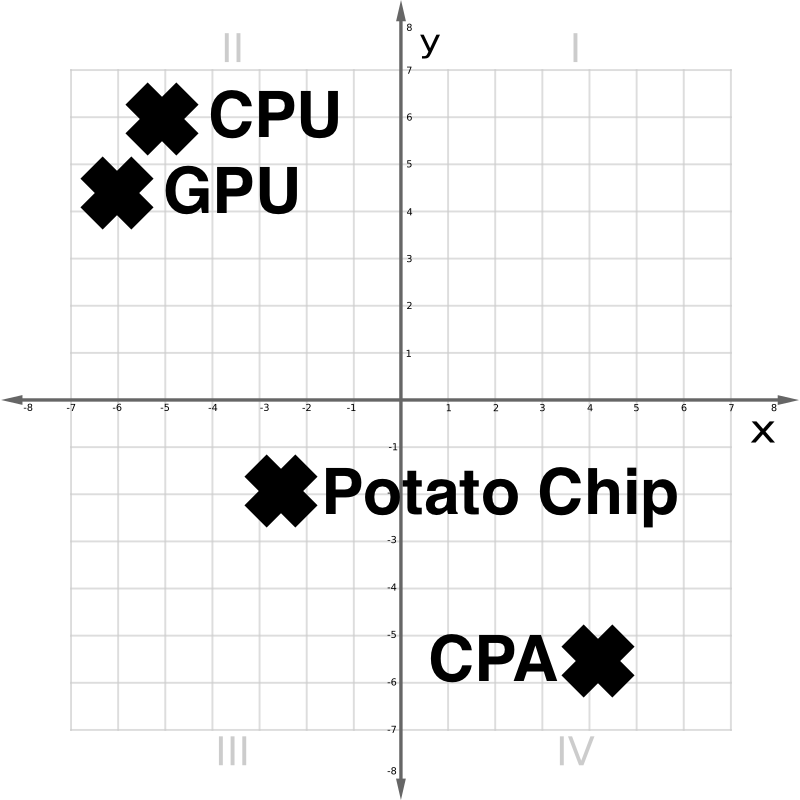
Within the vector area in Determine 1 above, we see {that a} CPU and a GPU are conceptually shut. A Potato Chip is distantly associated. A CPA, or accountant, although lexically much like a CPU, is kind of totally different.
The total story of vectors requires a quick journey via a land of neural networks, embeddings, and 1000’s of dimensions.
Neural Networks and Embeddings
Articles abound describing the speculation and operation of neural networks, that are loosely modeled on how organic neurons interconnect. This part will give a fast refresher. Schematically a neural web seems to be like Determine 2:
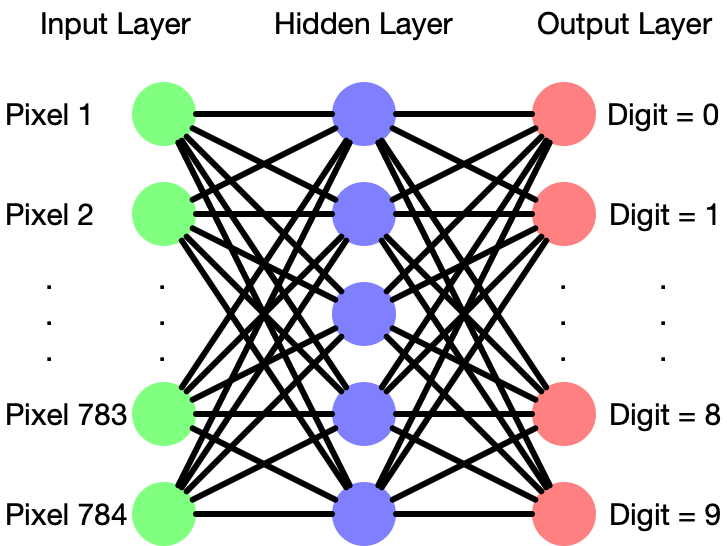
A neural community consists of layers of ‘neurons’ every of which accepts a number of inputs with weights, both additive or multiplicative, which it combines into an output sign. The configuration of layers in a neural community varies fairly a bit between totally different purposes, and crafting simply the fitting “hyperparameters” for a neural web requires a talented hand.
One ceremony of passage for machine studying college students is to construct a neural web to acknowledge handwritten digits from a dataset known as MNIST, which has labeled pictures of handwritten digits, every 28×28 pixels. On this case, the leftmost layer would want 28×28=784 neurons, one receiving a brightness sign from every pixel. A center “hidden layer” has a dense net of connections to the primary layer. Normally neural nets have many hidden layers, however right here there’s just one. Within the MNIST instance, the output layer would have 10 neurons, representing what the community “sees,” particularly possibilities of digits 0-9.
Initially, the community is actually random. Coaching the community entails repeatedly tweaking the weights to be a tiny bit extra correct. For instance, a crisp picture of an “8” ought to gentle up the #8 output at 1.0, leaving the opposite 9 all at 0. To the extent this isn’t the case, that is thought of an error, which will be mathematically quantified. With some intelligent math, it’s attainable to work backward from the output, nudging weights to scale back the general error in a course of known as backpropagation. Coaching a neural community is an optimization drawback, discovering an acceptable needle in an enormous haystack.
The pixel inputs and digit outputs all have apparent that means. However after coaching, what do the hidden layers characterize? This can be a good query!
Within the MNIST case, for some skilled networks, a specific neuron or group of neurons in a hidden layer would possibly characterize an idea like maybe “the enter accommodates a vertical stroke” or “the enter accommodates a closed loop”. With none express steering, the coaching course of constructs an optimized mannequin of its enter area. Extracting this from the community yields an embedding.
Textual content Vectors, and Extra
What occurs if we practice a neural community on textual content?
One of many first tasks to popularize phrase vectors known as word2vec. It trains a neural community with a hidden layer of between 100 and 1000 neurons, producing a phrase embedding.
On this embedding area, associated phrases are shut to one another. However even richer semantic relationships are expressible as but extra vectors. For instance, the vector between the phrases KING and PRINCE is almost the identical because the vector between QUEEN and PRINCESS. Primary vector addition expresses semantic facets of language that didn’t should be explicitly taught.
Surprisingly, these methods work not solely on single phrases, but in addition for sentences and even entire paragraphs. Totally different languages will encode in a approach that comparable phrases are shut to one another within the embedding area.
Analogous methods work on pictures, audio, video, analytics information, and anything {that a} neural community will be skilled on. Some “multimodal” embeddings enable, for instance, pictures and textual content to share the identical embedding area. An image of a canine would find yourself near the textual content “canine”. This appears like magic. Queries will be mapped to the embedding area, and close by vectors—whether or not they characterize textual content, information, or anything–will map to related content material.
Some Makes use of for Vector Search
Due to its shared ancestry with LLMs and neural networks, vector search is a pure slot in generative AI purposes, usually offering exterior retrieval for the AI. A number of the foremost makes use of for these sorts of use circumstances are:
- Including ‘reminiscence’ to a LLM past the restricted context window measurement
- A chatbot that shortly finds essentially the most related sections of paperwork in your company community, and palms them off to a LLM for summarization or as solutions to Q&A. (That is known as Retrieval Augmented Technology)
Moreover, vector search works nice in areas the place the search expertise must work extra carefully to how we expect, particularly for grouping comparable gadgets, resembling:
- Search throughout paperwork in a number of languages
- Discovering visually comparable pictures, or pictures much like movies.
- Fraud or anomaly detection, as an illustration if a specific transaction/doc/e mail produces an embedding that’s farther away from a cluster of extra typical examples.
- Hybrid search purposes, utilizing each conventional search engine know-how in addition to vector search to mix the strengths of every.
In the meantime, conventional key phrase based mostly search nonetheless has its strengths, and stays helpful for a lot of apps, particularly the place a person is aware of precisely what they’re searching for, together with structured information, linguistic evaluation, authorized discovery, and faceted or parametric search.
However that is solely a small style of what’s attainable. Vector search is hovering in recognition, and powering increasingly more purposes. How will your subsequent venture use vector search? Learn the way Rockset helps vector search right here.

{kind=link}