


(Tee11/Shutterstock)
So far as huge knowledge storage goes, Amazon S3 has gained the warfare. Even amongst storage distributors whose initials usually are not A.W.S., S3 is the defacto normal for storing numerous knowledge. However AWS isn’t resting on its laurels with S3, as we noticed with final week’s launch of S3 Specific Zone. And in response to AWS Distinguished Engineer Andy Warfield, there are extra modifications and optimizations deliberate for S3 on the horizon.
The large get with S3 Specific One Zone, which was unveiled every week in the past at re:Invent 2023, is a 10x discount in latency, as measured from the second a chunk of information is requested and when S3 delivers it. It delivers knowledge in lower than 10 milliseconds, which is darn quick.
When the decrease latency and the upper price of S3 Specific One Zone relative to regional S3 are factored in, it corresponds with a 80% discount in whole price of possession (TCO) for some workloads, in response to AWS. Contemplating how a lot huge firms spend on huge knowledge storage and processing, that’s a whole lot of dough.
So, how did AWS obtain such remarking numbers? “It’s not a easy reply,” Warfield stated. AWS used a number of strategies.
For starters, it ditched the 2 further copies of information that AWS mechanically creates in several Availability Zones (AZs) with regional S3 and different storge merchandise. These further two copies shield in opposition to knowledge loss within the occasion that the first and first backup copy are misplaced, however in addition they add latency by rising the quantity of information despatched over networks earlier than storage occasions will be accomplished. The providing nonetheless retains two backup copies of buyer knowledge, however they’re saved regionally.
“By shifting issues to a single AZ bucket, we scale back the…distance the request needed to journey,” Warfield stated throughout an interview at re:Invent final week. “It’s nonetheless an 11 nines product, nevertheless it’s not designed to be resilient to the lack of a facility like regional S3 is.”
S3 Specific One Zone is the primary new bucket sort for S3 since AWS launched the product again in 2006, Warfield stated, nevertheless it’s not the primary AWS storage product that shops its knowledge in single website. “EBS [Elastic Block Store] is constructed that means as effectively,” he stated.
One other method AWS used to slash the community overhead of its distributed storage repository is by shifting authentication and authorization checks out of the mainline. As a substitute of requiring authentication and authorization checks to be accomplished with every particular person knowledge request, it’s doing all of it at the start of the session, Warfield stated.
“We noticed…that the price of doing [individual checks] ended up including a bunch of latency,” he stated. “Every request needed to pay a value. And so we redesigned the protocol to hoist these checks out to a session-level verify. So while you first join with the SDK with the shopper, you authenticate into S3. After which we’re capable of cache that for the session and actually restrict the overhead of per-access checks.”
AWS continues to be delivering the identical stage of safety, Warfield stated. However all of the heavy lifting is being moved to the entrance of the session, enabling extra light-weight checks to be accomplished from that time ahead, till one thing modifications within the coverage, he stated.
May we see this within the mainstream regional S3 product? “It’s a fantastic query,” Warfield stated. “I feel we could discover that.”
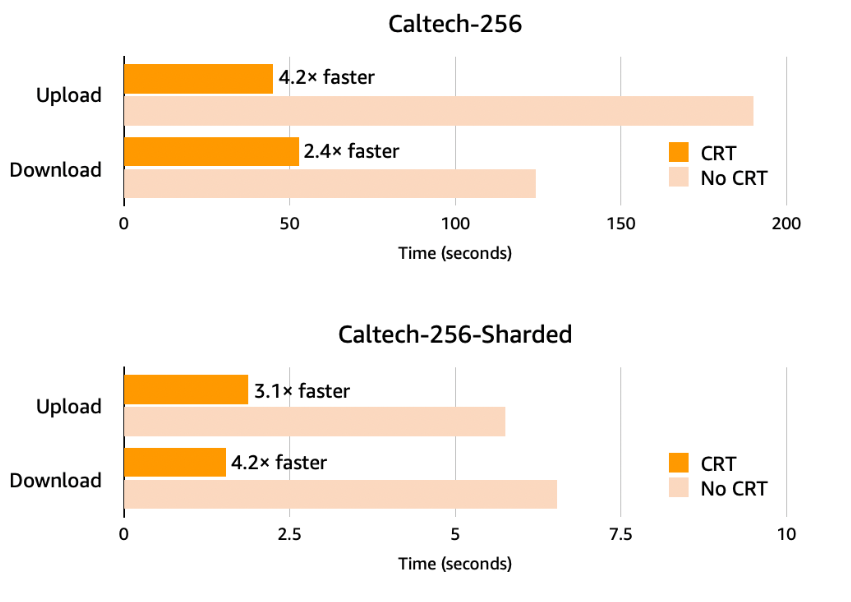
The brand new PyTorch library within the AWS CRT improves knowledge loading occasions from S3 (Picture supply AWS)
AWS can be utilizing “excessive efficiency media” to spice up efficiency and minimize latency with S3 Specific One Zone, Warfield stated. Whereas which will appear to suggest that AWS is utilizing NVMe drives, AWS has a coverage in opposition to figuring out precisely what media it’s utilizing beneath the covers. (This is identical cause why it’s by no means been confirmed by AWS, though it has been extensively suspected for a while, that S3 Glacier is predicated on tape drives.)
However S3 Specific One Zone isn’t the one means AWS is trying to velocity up knowledge serving out of S3. Earlier this 12 months, it launched the Frequent Runtime, or CRT, which is a bunch of open supply, client-side libraries for the REST API which can be written in C and that operate like a “souped-up SDK,” Warfield stated.
“It manages all the connections and requests going from the shopper to S3,” he stated. “So it auto-parallelizes all the things. It tracks well being. It form of treats S3 like the large distributed system that it’s. That library goals to get NIC entitlement, to saturate the community interface for request visitors to S3. and we’ve taken it as a device and linked it into an entire bunch of different shopper libraries.”
AWS made a few CRT-related bulletins at re:Invent final week. For starters it introduced that the AWS Command Line Interface (CLI) and SDK for Python at the moment are built-in with the CRT. The top result’s that customers ought to see higher efficiency on machine studying workloads developed with PyTorch, Warfield stated. “For knowledge loading and checkpointing in PyTorch, you simply get automated wonderful perofmacne off of S3,” he stated.
Earlier this 12 months, AWS launched Mountpoint, which wrappers S3 GET/PUT requests in an HDFS dialect, and is made accessible by way of the CRT. Mountpoint is designed to make it simpler to convey instruments developed within the Hadoop ecosystem into S3. For the previous 5 years or so, AWS has been getting a whole lot of requests to bolster S3 and make it extra appropriate and performant (i.e. much less latency) for Hadoop-era analytics instruments.
“In constructing out the size of S3, we ended up build up this enormous throughput window into the information, and folks operating Apache Hadoop, MapReduce jobs or Spark would burst up and they’d switch terabytes of information per second by that,” Warfield stated. “And now, as we’re shifting into these extra direct engagements, with coaching and inference or individuals simply writing apps on to S3, we have to shut the latency factor.”![]()
AWS has labored with many shoppers to optimize their analytics instruments to work with knowledge in S3. It’s written white papers about it, which individuals can learn in the event that they like. The purpose with CRT is to construct these efficiency optimizations straight into the product so that folks can get them mechanically, Warfield stated.
“So issues like, if you wish to switch a ton of information out of S3, right here’s how one can unfold that load throughout the front-end fleet, and get actually good efficiency,” he stated. “As a result of it’s a distributed system, typically you’re going to hit a bunch that’s not behaving as effectively correctly, and so it’s best to detect that and transfer it over. That is stuff that prospects have been already doing, and with the CRT launch, we’re making it automated.”
The corporate has extra investments deliberate for S3, together with outfitting S3 Specific One Zone with extra of the options which can be out there in regional S3, akin to automated knowledge tiering capabilities. The corporate might be customer-directed and look to clean out “no matter sharp edges of us face as they use it,” Warfield stated.
“There’s a ton of deep technical funding beneath the quilt within the numerous elements of the system,” Warfield stated about Specific. “We’re not speaking as a lot about what we’re planning on doing with that subsequent, however I’m fairly enthusiastic about how we’re going to have the ability to use that to launch an entire bunch of fairly [cool] stuff.”
AWS maintains 700,000 knowledge lakes on behalf of shoppers, spanning many exabytes of information and a mind-boggling 350 trillion objects. As these prospects take into account how they will leverage AI, they’re trying to their knowledge belongings and AWS to assist. Specific One Zone performs an vital position there.

Andy Warfield is a distinguished engineer at AWS who works on S3 and storage
“Specific is a option to transfer knowledge that they count on a whole lot of frequent entry on onto sooner media,” Warfield stated. “And the shopper work that we’ve accomplished with the PyTorch connector and Mountpoint hastens that finish of the information path.”
Many of those prospects have invested a whole lot of money and time in knowledge administration and knowledge preparation of their knowledge lakes, and are very effectively positioned to maneuver shortly with AI, Warfield stated.
“Quite a lot of the established knowledge lake prospects have been so quick to have the ability to leap on generative AI tooling. It’s been rewarding to see,” Warfield stated. “And a whole lot of the work that we’re doing with Bedrock…is the truth that it’s all API-driven. You’ll be able to take a mannequin, advantageous tune onto a personal copy with the information in your knowledge lake, and get entering into a day.”
The Hadoop-era of huge knowledge has handed, however lots of the classes dwell on. A kind of is shifting the compute to the information, which is one thing that AWS has embraced–on the insistence of its prospects, in fact.
“[Customers] are actually apprehensive about taking their knowledge to a indifferent set of tooling, as a result of they’ve already accomplished all this work on governance and knowledge perimeter, issues like that. They’ve a apply round it,” Warfield stated. “And so the Amazon method throughout all of this that basically resonates with the information lake prospects is bringing the fashions to your knowledge.”
Associated Gadgets:
AWS Launches Excessive-Pace Amazon S3 Specific One Zone
5 AWS Predictions as re:Invent 2023 Kicks Off
Object Storage a ‘Whole Cop Out,’ Hammerspace CEO Says. ‘You All Obtained Duped’
Editor’s observe: This text has been up to date to replicate the truth that S3 Specific One Zone nonetheless shops two backup copies of information, however they’re saved in the identical Availability Zone and never totally different AZs, as with normal S3.

{kind=link}