

Amazon OpenSearch Service is a managed service that makes it straightforward to safe, deploy, and function OpenSearch and legacy Elasticsearch clusters at scale within the AWS Cloud. Amazon OpenSearch Service provisions all of the assets on your cluster, launches it, and routinely detects and replaces failed nodes, decreasing the overhead of self-managed infrastructures. The service makes it straightforward so that you can carry out interactive log analytics, real-time software monitoring, web site searches, and extra by providing the most recent variations of OpenSearch, assist for 19 variations of Elasticsearch (1.5 to 7.10 variations), and visualization capabilities powered by OpenSearch Dashboards and Kibana (1.5 to 7.10 variations).
Within the newest service software program launch, we’ve up to date the shard allocation logic to be load-aware in order that when shards are redistributed in case of any node failures, the service disallows surviving nodes from getting overloaded by shards beforehand hosted on the failed node. That is particularly essential for Multi-AZ domains to offer constant and predictable cluster efficiency.
If you want extra background on shard allocation logic normally, please see Demystifying Elasticsearch shard allocation.
The problem
An Amazon OpenSearch Service area is alleged to be “balanced” when the variety of nodes are equally distributed throughout configured Availability Zones, and the entire variety of shards are distributed equally throughout all of the out there nodes with out focus of shards of anyone index on anyone node. Additionally, OpenSearch has a property referred to as “Zone Consciousness” that, when enabled, ensures that the first shard and its corresponding reproduction are allotted in numerous Availability Zones. If in case you have a couple of copy of knowledge, having a number of Availability Zones offers higher fault tolerance and availability. Within the occasion, the area is scaled out or scaled in or throughout the failure of node(s), OpenSearch routinely redistributes the shards between out there nodes whereas obeying the allocation guidelines based mostly on zone consciousness.
Whereas the shard-balancing course of ensures that shards are evenly distributed throughout Availability Zones, in some instances, if there may be an sudden failure in a single zone, shards will get reallocated to the surviving nodes. This may end result within the surviving nodes getting overwhelmed, impacting cluster stability.
As an illustration, if one node in a three-node cluster goes down, OpenSearch redistributes the unassigned shards, as proven within the following diagram. Right here “P“ represents a major shard copy, whereas “R“ represents a reproduction shard copy.
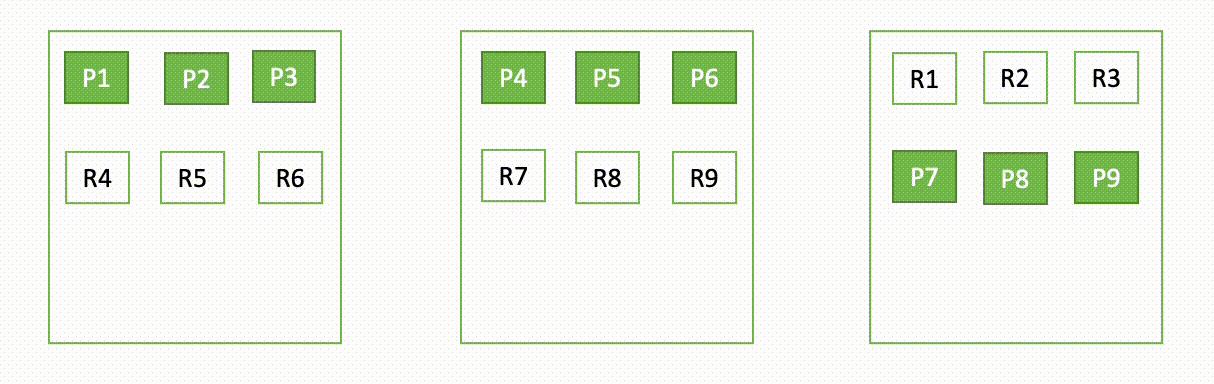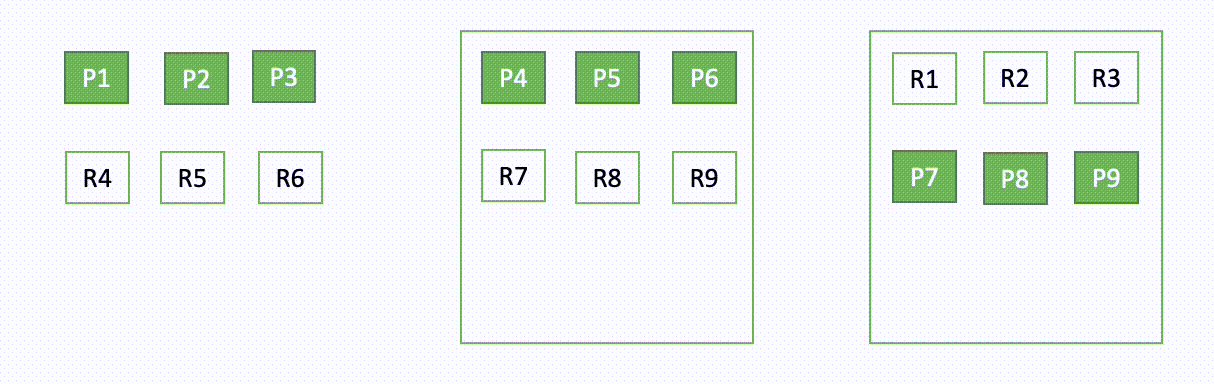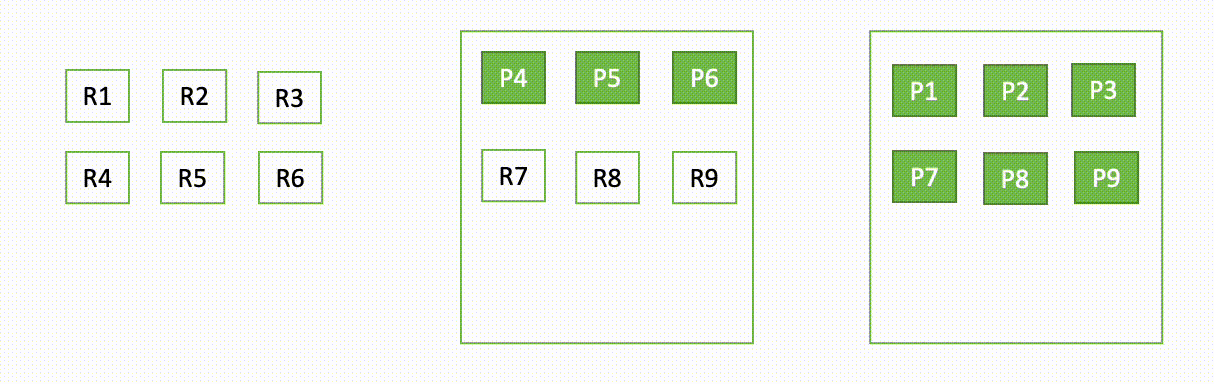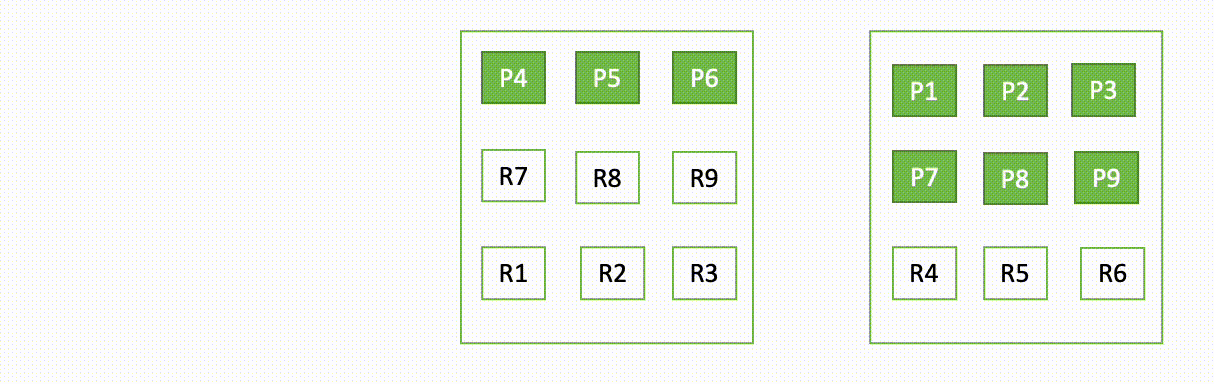
This habits of the area may be defined in two elements – throughout failure and through restoration.
Throughout failure
A website deployed throughout a number of Availability Zones can encounter a number of forms of failures throughout its lifecycle.
Full zone failure
A cluster might lose a single Availability Zone because of quite a lot of causes and in addition all of the nodes in that zone. As we speak, the service tries to put the misplaced nodes within the remaining wholesome Availability Zones. The service additionally tries to re-create the misplaced shards within the remaining nodes whereas nonetheless following the allocation guidelines. This can lead to some unintended penalties.
- When the shards of the impacted zone are getting reallocated to wholesome zones, they set off shard recoveries that may enhance the latencies because it consumes further CPU cycles and community bandwidth.
- For an n-AZ, n-copy setup, (n>1), the surviving n-1 Availability Zones are allotted with the nth shard copy, which may be undesirable as it may well trigger skewness in shard distribution, which might additionally end in unbalanced visitors throughout nodes. These nodes can get overloaded, resulting in additional failures.
Partial zone failure
Within the occasion of a partial zone failure or when the area loses solely a number of the nodes in an Availability Zone, Amazon OpenSearch Service tries to switch the failed nodes as shortly as attainable. Nevertheless, in case it takes too lengthy to switch the nodes, OpenSearch tries to allocate the unassigned shards of that zone into the surviving nodes within the Availability Zone. If the service can’t change the nodes within the impacted Availability Zone, it might allocate them within the different configured Availability Zone, which can additional skew the distribution of shards each throughout and throughout the zone. This once more has unintended penalties.
- If the nodes on the area do not need sufficient cupboard space to accommodate the extra shards, the area may be write-blocked, impacting indexing operation.
- Because of the skewed distribution of shards, the area may expertise skewed visitors throughout the nodes, which might additional enhance the latencies or timeouts for learn and write operations.
Restoration
As we speak, so as to keep the specified node rely of the area, Amazon OpenSearch Service launches knowledge nodes within the remaining wholesome Availability Zones, much like the eventualities described within the failure part above. In an effort to guarantee correct node distribution throughout all of the Availability Zones after such an incident, handbook intervention was wanted by AWS.
What’s altering
To enhance the general failure dealing with and minimizing the affect of failure on the area well being and efficiency, Amazon OpenSearch Service is performing the next modifications:
- Compelled Zone Consciousness: OpenSearch has a preexisting shard balancing configuration referred to as pressured consciousness that’s used to set the Availability Zones to which shards should be allotted. For instance, when you have an consciousness attribute referred to as zone and configure nodes in
zone1andzone2, you should utilize pressured consciousness to forestall OpenSearch from allocating replicas if just one zone is on the market:
With this instance configuration, should you begin two nodes with node.attr.zone set to zone1 and create an index with 5 shards and one reproduction, OpenSearch creates the index and allocates the 5 major shards however no replicas. Replicas are solely allotted as soon as nodes with node.attr.zone set to zone2 can be found.
Amazon OpenSearch Service will use the pressured consciousness configuration on Multi-AZ domains to make sure that shards are solely allotted in accordance with the principles of zone consciousness. This is able to stop the sudden enhance in load on the nodes of the wholesome Availability Zones.
- Load-Conscious Shard Allocation: Amazon OpenSearch Service will think about components just like the provisioned capability, precise capability, and whole shard copies to calculate if any node is overloaded with extra shards based mostly on anticipated common shards per node. It might stop shard task when any node has allotted a shard rely that goes past this restrict.
Word that any unassigned major copy would nonetheless be allowed on the overloaded node to forestall the cluster from any imminent knowledge loss.
Equally, to deal with the handbook restoration challenge (as described within the Restoration part above), Amazon OpenSearch Service can be making modifications to its inside scaling element. With the newer modifications in place, Amazon OpenSearch Service won’t launch nodes within the remaining Availability Zones even when it goes by means of the beforehand described failure situation.
Visualizing the present and new habits
For instance, an Amazon OpenSearch Service area is configured with 3-AZ, 6 knowledge nodes, 12 major shards, and 24 reproduction shards. The area is provisioned throughout AZ-1, AZ-2, and AZ-3, with two nodes in every of the zones.
Present shard allocation:
Whole variety of shards: 12 Major + 24 Duplicate = 36 shards
Variety of Availability Zones: 3
Variety of shards per zone (zone consciousness is true): 36/3 = 12
Variety of nodes per Availability Zone: 2
Variety of shards per node: 12/2 = 6
The next diagram offers a visible illustration of the area setup. The circles denote the rely of shards allotted to the node. Amazon OpenSearch Service will allocate six shards per node.

Throughout a partial zone failure, the place one node in AZ-3 fails, the failed node is assigned to the remaining zone, and the shards within the zone are redistributed based mostly on the out there nodes. After the modifications described above, the cluster won’t create a brand new node or redistribute shards after the failure of the node.
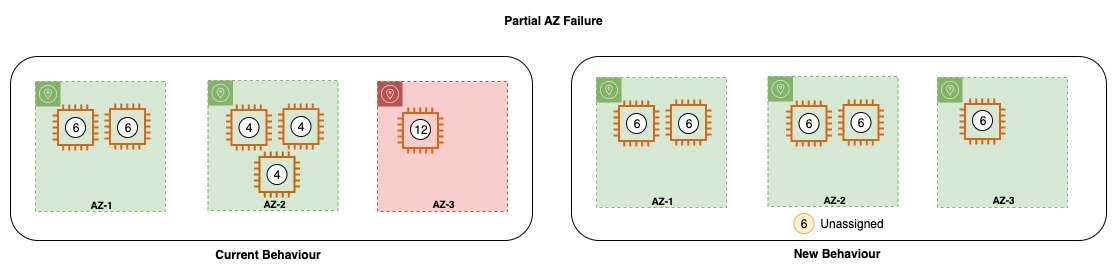
Within the diagram above, with the lack of one node in AZ-3, Amazon OpenSearch Service would attempt to launch the alternative capability in the identical zone. Nevertheless, because of some outage, the zone may be impaired and would fail to launch the alternative. In such an occasion, the service tries to launch deficit capability in one other wholesome zone, which could result in zone imbalance throughout Availability Zones. Shards on the impacted zone get stuffed on the surviving node in the identical zone. Nevertheless, with the brand new habits, the service would attempt to try launching capability in the identical zone however would keep away from launching deficit capability in different zones to keep away from imbalance. The shard allocator would additionally be sure that the surviving nodes don’t get overloaded.
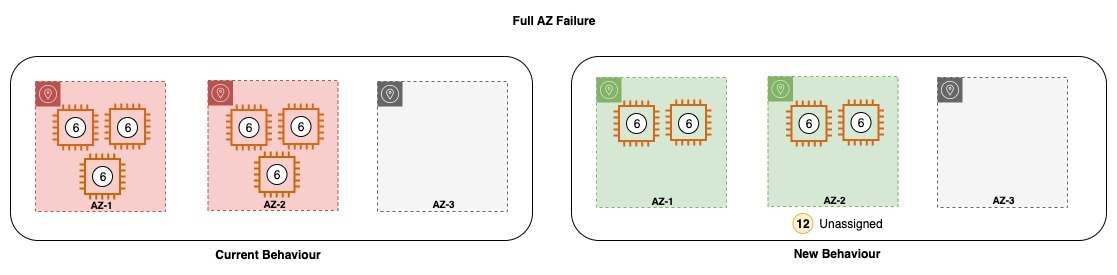
Equally, in case all of the nodes in AZ-3 are misplaced, or the AZ-3 turns into impaired, Amazon OpenSearch Service brings up the misplaced nodes within the remaining Availability Zone and in addition redistributes the shards on the nodes. Nevertheless, after the brand new modifications, Amazon OpenSearch Service will neither allocate nodes to the remaining zone or it can attempt to re-allocate misplaced shards to the remaining zone. Amazon OpenSearch Service will anticipate the Restoration to occur and for the area to return to the unique configuration after restoration.
In case your area shouldn’t be provisioned with sufficient capability to face up to the lack of an Availability Zone, you might expertise a drop in throughput on your area. It’s due to this fact strongly beneficial to comply with one of the best practices whereas sizing your area, which suggests having sufficient assets provisioned to face up to the lack of a single Availability Zone failure.

At the moment, as soon as the area recovers, the service requires handbook intervention to steadiness capability throughout Availability Zones, which additionally entails shard actions. Nevertheless, with the brand new behaviour, there isn’t a intervention wanted throughout the restoration course of as a result of the capability returns within the impacted zone and the shards are additionally routinely allotted to the recovered nodes. This ensures that there aren’t any competing priorities on the remaining assets.
What you possibly can anticipate
After you replace your Amazon OpenSearch Service area to the most recent service software program launch, the domains which have been configured with greatest practices may have extra predictable efficiency even after shedding one or many knowledge nodes in an Availability Zone. There will probably be decreased instances of shard overallocation in a node. It’s a good follow to provision ample capability to have the ability to tolerate a single zone failure
You may at occasions see a website turning yellow throughout such sudden failures since we gained’t assign reproduction shards to overloaded nodes. Nevertheless, this doesn’t imply that there will probably be knowledge loss in a well-configured area. We are going to nonetheless ensure that all primaries are assigned throughout the outages. There’s an automatic restoration in place, which is able to maintain balancing the nodes within the area and guaranteeing that the replicas are assigned as soon as the failure recovers.
Replace the service software program of your Amazon OpenSearch Service area to get these new modifications utilized to your area. Extra particulars on the service software program replace course of are within the Amazon OpenSearch Service documentation.
Conclusion
On this put up we noticed how Amazon OpenSearch Service not too long ago improved the logic to distribute nodes and shards throughout Availability Zones throughout zonal outages.
This alteration will assist the service to make sure extra constant and predictable efficiency throughout node or zonal failures. Domains gained’t see any elevated latencies or write blocks throughout processing writes and reads, which used to floor earlier at occasions because of over-allocation of shards on nodes.
In regards to the authors
 Bukhtawar Khan is a Senior Software program Engineer engaged on Amazon OpenSearch Service. He’s keen on distributed and autonomous techniques. He’s an lively contributor to OpenSearch.
Bukhtawar Khan is a Senior Software program Engineer engaged on Amazon OpenSearch Service. He’s keen on distributed and autonomous techniques. He’s an lively contributor to OpenSearch.
 Anshu Agarwal is a Senior Software program Engineer engaged on AWS OpenSearch at Amazon Net Companies. She is enthusiastic about fixing issues associated to constructing scalable and extremely dependable techniques.
Anshu Agarwal is a Senior Software program Engineer engaged on AWS OpenSearch at Amazon Net Companies. She is enthusiastic about fixing issues associated to constructing scalable and extremely dependable techniques.
 Shourya Dutta Biswas is a Software program Engineer engaged on AWS OpenSearch at Amazon Net Companies. He’s enthusiastic about constructing extremely resilient distributed techniques.
Shourya Dutta Biswas is a Software program Engineer engaged on AWS OpenSearch at Amazon Net Companies. He’s enthusiastic about constructing extremely resilient distributed techniques.
 Rishab Nahata is a Software program Engineer engaged on OpenSearch at Amazon Net Companies. He’s fascinated about fixing issues in distributed techniques. He’s lively contributor to OpenSearch.
Rishab Nahata is a Software program Engineer engaged on OpenSearch at Amazon Net Companies. He’s fascinated about fixing issues in distributed techniques. He’s lively contributor to OpenSearch.
 Ranjith Ramachandra is an Engineering Supervisor engaged on Amazon OpenSearch Service at Amazon Net Companies.
Ranjith Ramachandra is an Engineering Supervisor engaged on Amazon OpenSearch Service at Amazon Net Companies.
 Jon Handler is a Senior Principal Options Architect, specializing in AWS search applied sciences – Amazon CloudSearch, and Amazon OpenSearch Service. Based mostly in Palo Alto, he helps a broad vary of consumers get their search and log analytics workloads deployed proper and functioning effectively.
Jon Handler is a Senior Principal Options Architect, specializing in AWS search applied sciences – Amazon CloudSearch, and Amazon OpenSearch Service. Based mostly in Palo Alto, he helps a broad vary of consumers get their search and log analytics workloads deployed proper and functioning effectively.

{kind=link}