

Amazon SageMaker Studio is a completely built-in growth setting (IDE) for machine studying (ML) that allows information scientists and builders to carry out each step of the ML workflow, from getting ready information to constructing, coaching, tuning, and deploying fashions. SageMaker Studio comes with built-in integration with Amazon EMR, enabling information scientists to interactively put together information at petabyte scale utilizing frameworks resembling Apache Spark, Hive, and Presto proper from SageMaker Studio notebooks. With Amazon SageMaker, builders, information scientists, and SageMaker Studio customers can entry each uncooked information saved in Amazon Easy Storage Service (Amazon S3), and cataloged tabular information saved in a Hive metastore simply. SageMaker Studio’s assist for Apache Ranger creates a easy mechanism for making use of fine-grained entry management to the uncooked and cataloged information with grant and revoke insurance policies administered from a pleasant net interface.
On this submit, we present how one can authenticate into SageMaker Studio utilizing an present Energetic Listing (AD), with approved entry to each Amazon S3 and Hive cataloged information utilizing AD entitlements by way of Apache Ranger integration and AWS IAM Identification Heart (successor to AWS Single Signal-On). With this answer, you possibly can handle entry to a number of SageMaker environments and SageMaker Studio notebooks utilizing a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will entry solely the info and sources permitted by Apache Ranger insurance policies connected to the AD credentials, inclusive of desk and column-level entry.
With this functionality, a number of SageMaker Studio customers can hook up with the identical EMR cluster, gaining entry solely to information granted to their consumer or group, with audit data captured and visual in Amazon CloudWatch. This multi-tenant setting is feasible via consumer session isolation that stops customers from accessing datasets and cluster sources allotted to different customers. In the end, organizations can provision fewer clusters, scale back administrative overhead, and improve cluster utilization, saving workers time and cloud prices.
Resolution overview
We display this answer with an end-to-end use case utilizing a pattern ecommerce dataset. The dataset is on the market inside supplied AWS CloudFormation templates and consists of transactional ecommerce information (merchandise, orders, prospects) cataloged in a Hive metastore.
The answer makes use of two information analyst personas, Alex and Tina, every tasked with completely different evaluation requiring fine-grained limitations on dataset entry:
- Tina, an information scientist on the advertising and marketing workforce, is tasked with constructing a mannequin for buyer lifetime worth. Knowledge entry ought to solely be permitted to non-sensitive buyer, product, and orders information.
- Alex, an information scientist on the gross sales workforce, is tasked to generate product demand forecast, requiring entry to product and orders information. No buyer information is required.
The next determine illustrates our desired fine-grained entry.

The next diagram illustrates the answer structure.
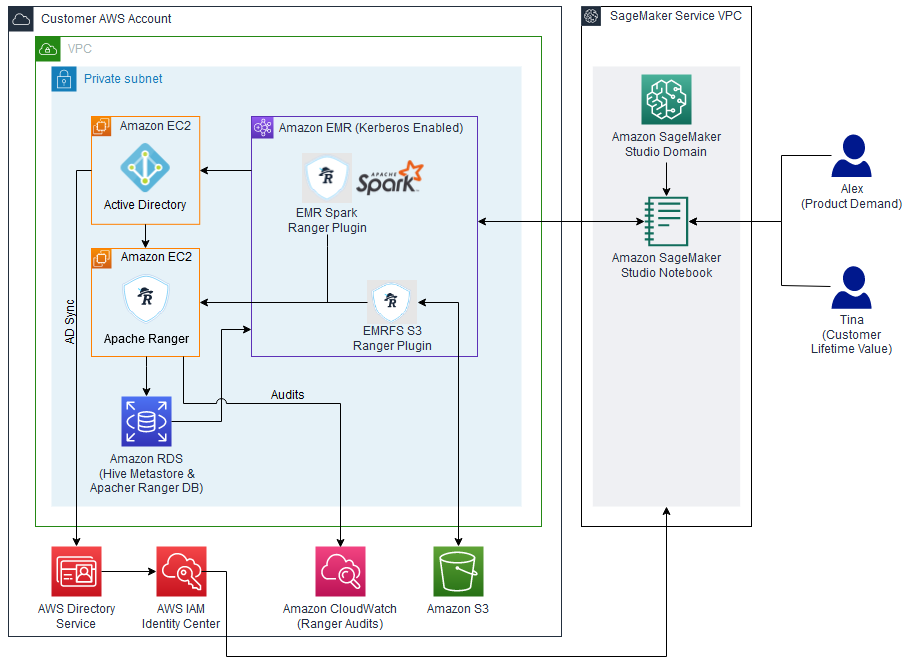
The structure is applied as follows:
- Microsoft Energetic Listing – Used to handle consumer authentication, choose AWS utility entry, and consumer and group membership for Apache Ranger secured information authorization
- Apache Ranger – Used to observe and handle complete information safety throughout the Hadoop and Amazon EMR platform
- Amazon EMR – Used to retrieve, put together, and analyze information from the Hive metastore utilizing Spark
- SageMaker Studio – An built-in IDE with purpose-built instruments to construct AI/ML fashions.
The next sections stroll via the setup of the architectural elements for this answer utilizing the CloudFormation stack.
Conditions
Earlier than you get began, ensure you have the next conditions:
Create sources with AWS CloudFormation
To construct the answer inside your setting, use the supplied CloudFormation templates to create the required AWS sources.
Word that working these CloudFormation templates and the next configuration steps will create AWS sources that will incur expenses. Moreover, all of the steps needs to be run in the identical Area.
Template 1
This primary template creates the next sources and takes roughly quarter-hour to finish:
- A Multi-AZ, multi-subnet VPC infrastructure, with managed NAT gateways within the public subnet for every Availability Zone
- S3 VPC endpoints and Elastic Community Interfaces
- A Home windows Energetic Listing area controller utilizing Amazon Elastic Compute Cloud (Amazon EC2) with cross-realm belief
- A Linux Bastion host (Amazon EC2) in an auto scaling group
To deploy this template, full the next steps:
- Sign up to the AWS Administration Console.
- On the Amazon EC2 console, create an EC2 key pair.
- Select Launch Stack :

- Choose the goal Area
- Confirm the stack title and supply the next parameters:
- The title of the important thing pair you created.
- Passwords for cross-realm belief, the Home windows area admin, LDAP bind, and default AD consumer. You should definitely report these passwords to make use of in future steps.
- Choose a minimal of three Availability Zones primarily based on the chosen Area.
- Evaluate the remaining parameters. No modifications are required for the answer, however you might change parameter values if desired.
- Select Subsequent after which select Subsequent once more.
- Evaluate the parameters.
- Choose I acknowledge that AWS CloudFormation may create IAM sources with customized names and I acknowledge that AWS CloudFormation may require the next functionality: CAPABILITY_AUTO_EXPAND.
- Select Submit.
Template 2
The second template creates the next sources and takes roughly 30–60 minutes to finish:
To deploy this template, full the next steps:
- Select Launch Stack :
- Choose the goal Area
- Confirm the stack title and supply the next parameters:
- Key pair title (created earlier).
LDAPHostPrivateIPdeal with, which could be discovered within the output part of the Home windows AD CloudFormation stack.- Passwords for the Home windows area admin, cross-realm belief, AD area consumer, and LDAP bind. Use the identical passwords as you probably did for the primary CloudFormation template.
- Passwords for the RDS for MySQL database and KDC admin. Report these passwords; they might be wanted in future steps.
- Log listing for the EMR cluster.
- VPC (it accommodates the title of the CloudFormation stack)
- Subnet particulars (align the subnet title with the parameter title).
- Set
AppsEMRto Hadoop, Spark, Hive, Livy, Hue, and Trino. - Depart
RangerAdminPasswordas is.
- Evaluate the remaining parameters. No modifications are required past what’s talked about, however you might change parameter values if desired.
- Select Subsequent, then select Subsequent once more.
- Evaluate the parameters.
- Choose I acknowledge that AWS CloudFormation may create IAM sources with customized names and I acknowledge that AWS CloudFormation may require the next functionality: CAPABILITY_AUTO_EXPAND.
- Select Submit.
Combine Energetic Listing with AWS accounts utilizing IAM Identification Heart
To allow customers to sign up to SageMaker with Energetic Listing credentials, a connection between IAM Identification Heart and Energetic Listing have to be established.
To connect with Microsoft Energetic Listing, we arrange AWS Listing Service utilizing AD Connector.
- On the Listing Service console, select Directories within the navigation pane.
- Select Arrange listing.
- For Listing sorts, choose AD Connector.
- Select Subsequent.

- For Listing measurement, choose the suitable measurement for AD Connector. For this submit, we choose Small.
- Select Subsequent.

- Select the VPC and personal subnets the place the Home windows AD area controller resides.
- Select Subsequent.

- Within the Energetic Listing info part, enter the next particulars (this info could be retrieved on the Outputs tab of the primary CloudFormation template):
- For Listing DNS Title, enter
awsemr.com. - For Listing NetBIOS title, enter
awsemr. - For DNS IP addresses, enter the IPv4 non-public IP deal with from AD Controller.
- Enter the service account consumer title and password that you just supplied throughout stack creation.
- For Listing DNS Title, enter
- Select Subsequent.

- Evaluate the settings and select Create listing.
After the listing is created, you will note its standing as Energetic on the Listing Companies console.
Arrange AWS Organizations
AWS Organizations helps IAM Identification Heart in just one Area at a time. To allow IAM Identification Heart on this Area, you have to first delete the IAM Identification Heart configuration if created in one other Area. Don’t delete an present IAM Identification Heart configuration except you’re positive it is not going to negatively affect present workloads.
- Navigate to the IAM Identification Heart console.
- If IAM Identification Heart has not been activated beforehand, select Allow. If a company doesn’t exist, an alert seems to create one.
- Select Create AWS group.
- Select Settings within the navigation pane.
- On the Identification supply tab, on the Actions menu, select Change id supply.

- For Select id supply, choose Energetic Listing.
- Select Subsequent.

- For Present Directories, select AWSEMR.COM.
- Select Subsequent.

- To substantiate the change, enter
ACCEPTwithin the affirmation enter field, then select Change id supply. Upon completion, you’ll be redirected to Settings, the place you obtain the alertConfigurable AD sync paused. - Select Resume sync.

- Select Settings within the navigation pane.
- On the Identification supply tab, on the Actions menu, select Handle sync.

- Select Add customers and teams to specify the customers and teams to sync from Energetic Listing to IAM Identification Heart.

- On the Customers tab, enter
tinaand select Add. - Enter
alexand select Add. - Select Submit.
- On the Teams tab, enter
datascienceand select Add. - Select Submit.

After your customers and teams are synced to IAM Identification Heart, you possibly can see them by selecting Customers or Teams within the navigation pane on the IAM Identification Heart console. Once they’re obtainable, you possibly can assign them entry to AWS accounts and cloud functions. The preliminary sync could take as much as 5 minutes.
Arrange a SageMaker area utilizing IAM Identification Heart
To arrange a SageMaker area, full the next steps:
- On the SageMaker console, select Domains within the navigation pane.
- Select Create area.
- Select Commonplace setup, then select Configure.

- For Area Title, enter a novel title in your area.
- For Authentication, select AWS IAM Identification Heart.
- Select Create a brand new position for the default execution position.
- Within the Create an IAM Function popup, select Any S3 bucket.
- Select Create position.
- Copy the position particulars for use in subsequent part for including a coverage for EMR cluster entry.
- Within the Community and storage part, specify the next:
- Select the VPC that you just created utilizing the primary CloudFormation template.
- Select a non-public subnet in an Availability Zone supported by SageMaker.
- Use the default safety group (
sg-XXXX). - Select VPC solely.
Word that there’s a public area referred to as AWSEMR.COM that may battle with the one created for this answer if Public web solely is chosen.
- Depart all different choices as default and select Subsequent.
- Within the Studio settings part, settle for the defaults and select Subsequent.
- Within the RStudio settings part, settle for the defaults and select Subsequent.
- Within the Canvas setting part, settle for the defaults and select Submit.
Add a coverage to offer SageMaker Studio entry to the EMR cluster
Full the next steps to provide SageMaker Studio entry to the EMR cluster:
- On the IAM console, select Roles within the navigation pane.
- Search and select for the position you copied earlier (
<AmazonSageMaker-ExecutionRole- XXXXXXXXXXXXXXX>). - On the Permissions tab, select Add permissions and Connect coverage.
- Seek for and select the coverage
AmazonEMRFullAccessPolicy_v2. - Select Add permissions.

Add customers and teams to entry the area
Full the next steps to provide customers and teams entry to the area:
- On the SageMaker console, select Domains within the navigation pane.
- Select the area you created earlier.
- On the Area particulars web page, select Assign customers and teams.

- On the Customers tab, choose the customers
tinaandalex. - On the Teams tab, choose the group
datascience. - Select Assign customers and teams.

Configure Spark information entry rights in Apache Ranger
Now that the AWS setting is ready up, we configure Hive dataset safety utilizing Apache Ranger.
To start out, gather the Apache Ranger URL particulars to entry the Ranger admin console:
- On the Amazon EC2 console, select Sources within the navigation pane, then Occasion (working).
- Select the Ranger server EC2 occasion and duplicate the non-public IP DNS title (IPv4 solely).
Subsequent, hook up with the Home windows area controller to make use of the related VPC to entry the Ranger admin console. That is performed by logging in to the Home windows server and launching an internet browser. - Set up the Distant Desktop Companies shopper in your pc to attach with Home windows Server.
- Authorize inbound visitors out of your pc to the Home windows AD area controller EC2 occasion.
- On the Amazon EC2 console, select Sources within the navigation pane, then Occasion (working).
- Select on the Home windows Area Controller (DC1) EC2 occasion ID and duplicate the general public IP DNS title (IPv4 solely).
- Use Microsoft Distant Desktop to log in to the Home windows area controller:
- Pc – Use the general public IP DNS title (IPv4 solely).
- Username – Enter
awsadmin. - Password – Use the password you set in the course of the first CloudFormation template setup.
- Disable the Enhanced Safety Configuration for Web Explorer.
- Launch Web Explorer and navigate to the Ranger admin console utilizing the non-public IP DNS title (IPv4 solely) related to the Ranger server famous earlier and port 6182 (for instance,
https://<RangerServer Non-public IP DNS title>:6182). - Select Proceed to this web site (not really helpful) for those who obtain a safety alert.
- Log in utilizing the default consumer title and password. In the course of the first logon, you need to modify your password and retailer it securely.
- Within the prime Ranger banner, select Settings and Customers/Teams/Roles.
- Verify Tina and Alex are listed as customers with a Consumer Supply of Exterior.
- Verify the
datasciencegroup is listed as a bunch with Group Supply of Exterior.
If the Tina or Alex customers aren’t listed, observe the Apache Ranger troubleshooting directions within the appendix on the finish of this submit.
Dataset insurance policies
The Apache Ranger entry coverage mannequin consists of two main elements: specification of the sources a coverage is utilized to, resembling information and directories, databases, tables, and columns, companies, and so forth, and the specification of entry situations (permissions) for particular customers and teams.
Configure your dataset coverage with the next steps:
- On the Ranger admin console, select the Ranger icon within the prime banner to return to the primary web page.
- Select the service title
amazonemrsparkinsideAMAZON-EMR-SPARK. - Select Add New Coverage and add a brand new coverage with the next parameters:
- For Coverage Title, enter
Knowledge Science Coverage. - For Database, enter
staginganddefault. - For EMR Spark Desk, enter
merchandiseandorders. - For EMR Spark Column, enter
*. - Within the Permit Circumstances part, for Choose Consumer, enter
tinaandalex, and for Permissions, enterchoose and browse.
- For Coverage Title, enter
- Select Add.

When utilizing Web Explorer & including a brand new coverage, you might obtain the errorSCRIPT438: Object would not assist property or technique 'assign'. On this case, set up and use an alternate browser resembling Firefox or Chrome. - Select Add New Coverage and add a brand new coverage for
tina:- For Coverage Title, enter
Buyer Demographics Coverage. - For Database, enter
staging. - For EMR Spark Desk, enter
Prospects. - For EMR Spark Column, select
customer_id,first_name,last_name,area, andstate. - Within the Permit Circumstances part, for Choose Consumer, enter
Tinaand for Permissions, enterchoose and browse.
- For Coverage Title, enter
- Select Add.

Configure Amazon S3 information entry rights in Apache Ranger
Full the next steps to configure Amazon S3 information entry rights:
- On the Ranger admin console, select the Ranger icon within the prime banner to return to the primary web page.
- Select the service title
amazonemrs3insideAMAZON-EMR-EMRFS. - Select Add New Coverage and add a coverage for the
datasciencegroup as follows:- For Coverage Title, enter
Knowledge Science S3 Coverage. - For S3 useful resource, enter the next:
aws-bigdata-blog/artifacts/aws-blog-emr-ranger/information/staging/merchandiseaws-bigdata-blog/artifacts/aws-blog-emr-ranger/information/staging/orders
- Within the Permit Circumstances, part, for Choose Consumer, enter
tinaandalex, and for Permissions, enterGetObjectandListObjects.
- For Coverage Title, enter
- Select Add.

- Select Add New Coverage and add a brand new coverage for
tina:- For Coverage Title, enter
Buyer Demographics S3 Coverage. - For S3 useful resource, enter
aws-bigdata-blog/artifacts/aws-blog-emr-ranger/information/staging/prospects. - Within the Permit Circumstances part, for Choose Consumer, enter Tina and for Permissions, enter
GetObjectandListObjects.
- For Coverage Title, enter
- Select Add.

Configure Amazon S3 consumer working folders
Whereas working with information, customers usually require information storage for interim outcomes. To offer every consumer with a non-public working listing, full the next steps:
- On the Ranger admin console, select Ranger icon within the prime banner to return to the primary web page.
- Select the service title
amazonemrs3insideAMAZON-EMR-EMRFS. - Select Add New Coverage and add a coverage for
{USER}as follows:- For Coverage Title, enter
Consumer Listing S3 Coverage. - For S3 useful resource, enter
<Bucket Title>/information/{USER}(use a bucket inside the account). - Allow Recursive.
- Within the Permit Circumstances, part, for Choose Consumer, enter
{USER}and for Permissions, enterGetObject,ListObjects,PutObject, andDeleteObject.
- For Coverage Title, enter
- Select Add.

Use the consumer entry login URL
Customers making an attempt to entry shared AWS functions by way of IAM Identification Heart have to first log in to the AWS setting with a customized hyperlink utilizing their Energetic Listing consumer title and password. The hyperlink wanted could be discovered on the IAM Identification Heart console.
- On the IAM Identification Heart console, select Settings within the navigation pane.
- On the Identification supply tab, find the consumer login hyperlink underneath AWS entry portal URL.
Check role-based information entry
To evaluation, information scientist Tina must construct a buyer lifetime worth mannequin, which requires entry to orders, product, and non-sensitive buyer information. Knowledge scientist Alex solely wants entry to orders and product information to construct a product demand mannequin.
On this part, we check the info entry ranges for every position.
Knowledge scientist Tina
Full the next steps:
- Log in utilizing the URL you positioned within the earlier step.
- Enter Microsoft AD consumer tina@awsemr.com and your password.
- Select the Amazon SageMaker Studio tile.
- Within the SageMaker Studio UI, begin a pocket book:
- Select File, New, and Pocket book.
- For Picture, select SparkMagic.
- For Kernel, select PySpark.
- For Occasion Sort, select ml.t3.medium.
- Select Choose.
- When the pocket book kernel begins, hook up with the EMR cluster by working the next code:
The EMR cluster ID particulars could be discovered on the Outputs tab of the EMR cluster CloudFormation stack created with the second template.
- Enter Microsoft AD
tina@AWSEMR.COMand your password. (Word thatusername@AWSEMR.COMis case-sensitive.) - Select Join.

Now we will check Tina’s information entry.
- In a brand new cell, enter the next question and run the cell:
Returned information will point out the desk objects accessible to Tina.
- In a brand new cell, run the next:
Returned information will embrace columns Tina has been granted entry.
Let’s check Tina’s entry to buyer information.
- In a brand new cell, run the next:
The previous question will lead to an Entry Denied error as a result of inclusion of delicate information columns.
Throughout advert hoc evaluation and mannequin constructing, it’s frequent for customers to create short-term datasets that should be persevered for a brief interval. Let’s check Tina’s means to create a working dataset and retailer ends in a non-public working listing.
- In a brand new cell, run the next:
- Earlier than working the next code, replace the S3 path variable <bucket title> to correspond to an S3 location inside your native account:
The previous question writes the created dataset as Parquet information within the S3 bucket specified.
Knowledge scientist: Alex
Full the next steps:
- Log in utilizing the URL you positioned within the earlier step.
- Enter Microsoft AD consumer
alex@awsemr.comand your password. - Select the Amazon SageMaker Studio tile.
- Within the SageMaker Studio UI, begin a pocket book:
- Select File, New, and Pocket book.
- For Picture, select SparkMagic.
- For Kernel, select PySpark.
- For Occasion Sort, select ml.t3.medium.
- Select Choose.
- When the pocket book kernel begins, hook up with the EMR cluster by working the next code:
- Enter Microsoft AD
alex@AWSEMR.COMand your password (word thatusername@AWSEMR.COMis case-sensitive). - Select Join. Now we will check Alex’s information entry.
- In a brand new cell, enter the next question and run the cell:
Returned information will point out the desk objects accessible to Alex. Word that the shoppers desk is lacking.
- In a brand new cell, run the next:
Returned information will embrace columns Alex has been granted entry.
Let’s check Alex’s entry to buyer information.
- In a brand new cell, run the next:
The previous question will lead to an Entry Denied error as a result of Alex doesn’t have entry to prospects.
We are able to confirm Ranger is chargeable for the denial by wanting on the CloudWatch logs.

Now which you can efficiently entry information, be at liberty to interactively discover, visualize, put together, and mannequin the info utilizing the completely different consumer personas.
Clear up
If you’re completed experimenting with this answer, clear up your sources:
- Shut down and replace SageMaker Studio and Studio apps. Make sure that all apps created as a part of this submit are deleted earlier than deleting the stack.
- Change the id supply for IAM Identification Heart again to Identification Heart Listing.
- Delete the listing AWSEMR.COM from Listing Companies.
- Empty the S3 buckets created by the CloudFormation stacks.
- Delete the stacks by way of the AWS CloudFormation console for the non-nested stacks beginning in reverse order.
Conclusion
This submit confirmed how one can implement fine-grained entry management in SageMaker Studio and Amazon EMR utilizing Apache Ranger and Microsoft Energetic Listing. We additionally demonstrated how a number of SageMaker Studio customers can hook up with the identical EMR cluster and entry completely different tables and columns utilizing Apache Ranger, whereby every consumer is scoped with permissions matching their particular person degree of entry to information. As well as, we demonstrated how the person customers can entry separate S3 folders for storing their intermediate information. We detailed the steps required to arrange the combination and supplied CloudFormation templates to arrange the bottom infrastructure from finish to finish.
To study extra about utilizing Amazon EMR with SageMaker Studio, seek advice from Put together Knowledge utilizing Amazon EMR. We encourage you to check out this new performance, and join with the Machine Studying & AI group if in case you have any questions or suggestions!
Appendix: Apache Ranger troubleshooting
The sync between Energetic Listing and Apache Ranger is ready for each 24 hours. To pressure a sync, full the next steps:
- Connect with the Apache Ranger server utilizing SSH. This may be performed utilizing instantly or Session Supervisor, a functionality of AWS Programs Supervisor, or via AWS Cloud9.
- As soon as related, problem the next instructions:
- To substantiate the sync, open the Ranger console as an admin.
- Select Audit within the prime banner.
- Select the Consumer Sync tab and ensure the occasion time.
In regards to the Authors
 Rahul Sarda is a Senior Analytics & ML Specialist at AWS. He’s a seasoned chief with over 20 years of expertise, who’s enthusiastic about serving to prospects construct scalable information and analytics options to realize well timed insights and make vital enterprise selections. In his spare time, he enjoys spending time together with his household, keep wholesome, working and highway biking.
Rahul Sarda is a Senior Analytics & ML Specialist at AWS. He’s a seasoned chief with over 20 years of expertise, who’s enthusiastic about serving to prospects construct scalable information and analytics options to realize well timed insights and make vital enterprise selections. In his spare time, he enjoys spending time together with his household, keep wholesome, working and highway biking.
 Varun Rao Bhamidimarri is a Sr Supervisor, AWS Analytics Specialist Options Architect workforce. His focus helps prospects with adoption of cloud-enabled analytics options to satisfy their enterprise necessities. Outdoors of labor, he loves spending time together with his spouse and two youngsters, keep wholesome, mediate and just lately picked up gardening in the course of the lockdown.
Varun Rao Bhamidimarri is a Sr Supervisor, AWS Analytics Specialist Options Architect workforce. His focus helps prospects with adoption of cloud-enabled analytics options to satisfy their enterprise necessities. Outdoors of labor, he loves spending time together with his spouse and two youngsters, keep wholesome, mediate and just lately picked up gardening in the course of the lockdown.

{kind=link}