
On this weblog put up, I am going to describe how we use RocksDB at Rockset and the way we tuned it to get probably the most efficiency out of it. I assume that the reader is usually aware of how Log-Structured Merge tree based mostly storage engines like RocksDB work.
At Rockset, we wish our customers to have the ability to constantly ingest their knowledge into Rockset with sub-second write latency and question it in 10s of milliseconds. For this, we’d like a storage engine that may help each quick on-line writes and quick reads. RocksDB is a high-performance storage engine that’s constructed to help such workloads. RocksDB is utilized in manufacturing at Fb, LinkedIn, Uber and plenty of different firms. Initiatives like MongoRocks, Rocksandra, MyRocks and many others. used RocksDB as a storage engine for present in style databases and have been profitable at considerably lowering area amplification and/or write latencies. RocksDB’s key-value mannequin can also be best suited for implementing converged indexing. So we determined to make use of RocksDB as our storage engine. We’re fortunate to have vital experience on RocksDB in our group within the type of our CTO Dhruba Borthakur who based RocksDB at Fb. For every enter area in an enter doc, we generate a set of key-value pairs and write them to RocksDB.
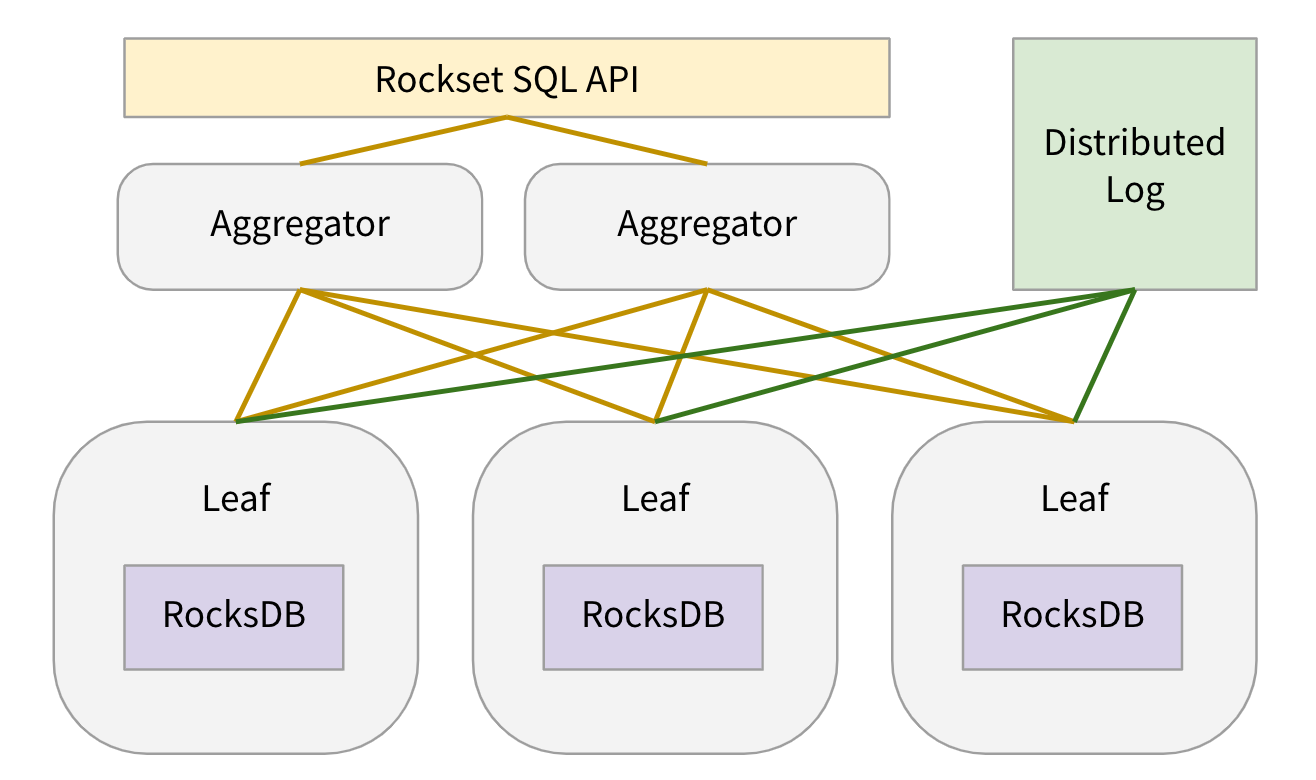
Let me rapidly describe the place the RocksDB storage nodes fall within the general system structure.
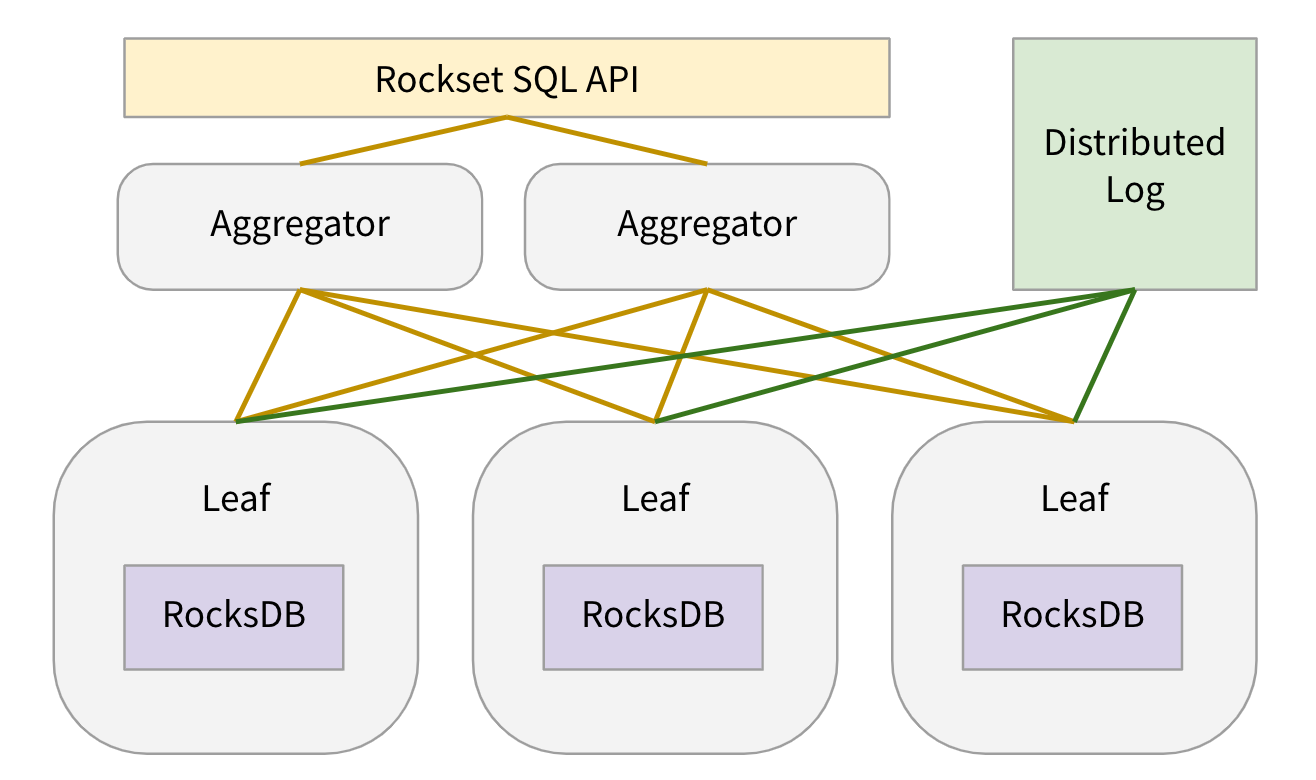
When a consumer creates a set, we internally create N shards for the gathering. Every shard is replicated k-ways (often ok=2) to realize excessive learn availability and every shard duplicate is assigned to a leaf node. Every leaf node is assigned many shard replicas of many collections. In our manufacturing setting every leaf node has round 100 shard replicas assigned to it. Leaf nodes create 1 RocksDB occasion for every shard duplicate assigned to them. For every shard duplicate, leaf nodes constantly pull updates from a DistributedLogStore and apply the updates to the RocksDB occasion. When a question is obtained, leaf nodes are assigned question plan fragments to serve knowledge from a number of the RocksDB situations assigned to them. For extra particulars on leaf nodes, please consult with Aggregator Leaf Tailer weblog put up or Rockset white paper.
To realize question latency of milliseconds underneath 1000s of qps of sustained question load per leaf node whereas constantly making use of incoming updates, we spent plenty of time tuning our RocksDB situations. Beneath, we describe how we tuned RocksDB for our use case.
RocksDB-Cloud
RocksDB is an embedded key-value retailer. The information in 1 RocksDB occasion isn’t replicated to different machines. RocksDB can not recuperate from machine failures. To realize sturdiness, we constructed RocksDB-Cloud. RocksDB-Cloud replicates all the info and metadata for a RocksDB occasion to S3. Thus, all SST recordsdata written by leaf nodes get replicated to S3. When a leaf node machine fails, all shard replicas on that machine get assigned to different leaf nodes. For every new shard duplicate task, a leaf node reads the RocksDB recordsdata for that shard from corresponding S3 bucket and picks up the place the failed leaf node left off.
Disable Write Forward Log
RocksDB writes all its updates to a write forward log and to the energetic in-memory memtable. The write forward log is used to recuperate knowledge within the memtables within the occasion of course of restart. In our case, all of the incoming updates for a set are first written to a DistributedLogStore. The DistributedLogStore itself acts as a write forward log for the incoming updates. Additionally, we don’t want to ensure knowledge consistency throughout queries. It’s okay to lose the info within the memtables and re-fetch it from the DistributedLogStore on restarts. For that reason, we disable RocksDB’s write forward log. Which means all our RocksDB writes occur in-memory.
Author Price Restrict
As talked about above, leaf nodes are liable for each making use of incoming updates and serving knowledge for queries. We are able to tolerate comparatively a lot increased latency for writes than for queries. As a lot as attainable, we all the time wish to use a fraction of obtainable compute capability for processing writes and most of compute capability for serving queries. We restrict the variety of bytes that may be written per second to all RocksDB situations assigned to a leaf node. We additionally restrict the variety of threads used to use writes to RocksDB situations. This helps reduce the affect RocksDB writes might have on question latency. Additionally, by throttling writes on this method, we by no means find yourself with imbalanced LSM tree or set off RocksDB’s built-in unpredictable back-pressure/stall mechanism. Word that each of those options should not out there in RocksDB, however we applied them on high of RocksDB. RocksDB helps a charge limiter to throttle writes to the storage system, however we’d like a mechanism to throttle writes from the applying to RocksDB.
Sorted Write Batch
RocksDB can obtain increased write throughput if particular person updates are batched in a WriteBatch and additional if consecutive keys in a write batch are in a sorted order. We make the most of each of those. We batch incoming updates into micro-batches of ~100KB measurement and kind them earlier than writing them to RocksDB.
Dynamic Stage Goal Sizes
In an LSM tree with leveled compaction coverage, recordsdata from a stage don’t get compacted with recordsdata from the subsequent stage till the goal measurement of the present stage is exceeded. And the goal measurement for every stage is computed based mostly on the required L1 goal measurement and stage measurement multiplier (often 10). This often leads to increased area amplification than desired till the final stage has reached its goal measurement as described on RocksDB weblog. To alleviate this, RocksDB can dynamically set goal sizes for every stage based mostly on the present measurement of the final stage. We use this function to realize the anticipated 1.111 area amplification with RocksDB whatever the quantity of information saved within the RocksDB occasion. It may be turned on by setting AdvancedColumnFamilyOptions::level_compaction_dynamic_level_bytes to true.
Shared Block Cache
As talked about above, leaf nodes are assigned many shard replicas of many collections and there may be one RocksDB occasion for every shard duplicate. As a substitute of utilizing a separate block cache for every RocksDB occasion, we use 1 international block cache for all RocksDB situations on the leaf node. This helps obtain higher reminiscence utilization by evicting unused blocks throughout all shard replicas out of leaf reminiscence. We give block cache about 25% of the reminiscence out there on a leaf pod. We deliberately don’t make block cache even larger even when there may be spare reminiscence out there that isn’t used for processing queries. It’s because we wish the working system web page cache to have that spare reminiscence. Web page cache shops compressed blocks whereas block cache shops uncompressed blocks, so web page cache can extra densely pack file blocks that aren’t so scorching. As described in Optimizing Area Amplification in RocksDB paper, web page cache helped cut back file system reads by 52% for 3 RocksDB deployments noticed at Fb. And web page cache is shared by all containers on a machine, so the shared web page cache serves all leaf containers working on a machine.
No Compression For L0 & L1
By design, L0 and L1 ranges in an LSM tree include little or no knowledge in comparison with different ranges. There may be little to be gained by compressing the info in these ranges. However, we might avoid wasting cpu by not compressing knowledge in these ranges. Each L0 to L1 compaction must entry all recordsdata in L1. Additionally, vary scans can not use bloom filter and have to lookup all recordsdata in L0. Each of those frequent cpu-intensive operations would use much less cpu if knowledge in L0 and L1 doesn’t should be uncompressed when learn or compressed when written. For this reason, and as advisable by RocksDB group, we don’t compress knowledge in L0 and L1, and use LZ4 for all different ranges.
Bloom Filters On Key Prefixes
As described in our weblog put up, Converged Index™: The Secret Sauce Behind Rockset’s Quick Queries, we retailer each column of each doc in RocksDB a number of key ranges. For queries, we learn every of those key ranges in a different way. Particularly, we don’t ever lookup a key in any of those key ranges utilizing the precise key. We often merely search to a key utilizing a smaller, shared prefix of the important thing. Subsequently, we set BlockBasedTableOptions::whole_key_filtering to false in order that entire keys should not used to populate and thereby pollute the bloom filters created for every SST. We additionally use a customized ColumnFamilyOptions::prefix_extractor in order that solely the helpful prefix of the secret is used for setting up the bloom filters.
Iterator Freepool
When studying knowledge from RocksDB for processing queries, we have to create 1 or extra rocksdb::Iterators. For queries that carry out vary scans or retrieve many fields, we have to create many iterators. Our cpu profile confirmed that creating these iterators is dear. We use a freepool of those iterators and attempt to reuse iterators inside a question. We can not reuse iterators throughout queries as every iterator refers to a selected RocksDB snapshot and we use the identical RocksDB snapshot for a question.
Lastly, right here is the complete listing of configuration parameters we specify for our RocksDB situations.
Choices.max_background_flushes: 2
Choices.max_background_compactions: 8
Choices.avoid_flush_during_shutdown: 1
Choices.compaction_readahead_size: 16384
ColumnFamilyOptions.comparator: leveldb.BytewiseComparator
ColumnFamilyOptions.table_factory: BlockBasedTable
BlockBasedTableOptions.checksum: kxxHash
BlockBasedTableOptions.block_size: 16384
BlockBasedTableOptions.filter_policy: rocksdb.BuiltinBloomFilter
BlockBasedTableOptions.whole_key_filtering: 0
BlockBasedTableOptions.format_version: 4
LRUCacheOptionsOptions.capability : 8589934592
ColumnFamilyOptions.write_buffer_size: 134217728
ColumnFamilyOptions.compression[0]: NoCompression
ColumnFamilyOptions.compression[1]: NoCompression
ColumnFamilyOptions.compression[2]: LZ4
ColumnFamilyOptions.prefix_extractor: CustomPrefixExtractor
ColumnFamilyOptions.compression_opts.max_dict_bytes: 32768
Be taught extra about how Rockset makes use of RocksDB:

{kind=link}