
A lot of our customers implement operational reporting and analytics on DynamoDB utilizing Rockset as a SQL intelligence layer to serve dwell dashboards and purposes. As an engineering group, we’re continuously looking for alternatives to enhance their SQL-on-DynamoDB expertise.
For the previous few weeks, we’ve got been arduous at work tuning the efficiency of our DynamoDB ingestion course of. Step one on this course of was diving into DynamoDB’s documentation and performing some experimentation to make sure that we have been utilizing DynamoDB’s learn APIs in a method that maximizes each the steadiness and efficiency of our system.
Background on DynamoDB APIs
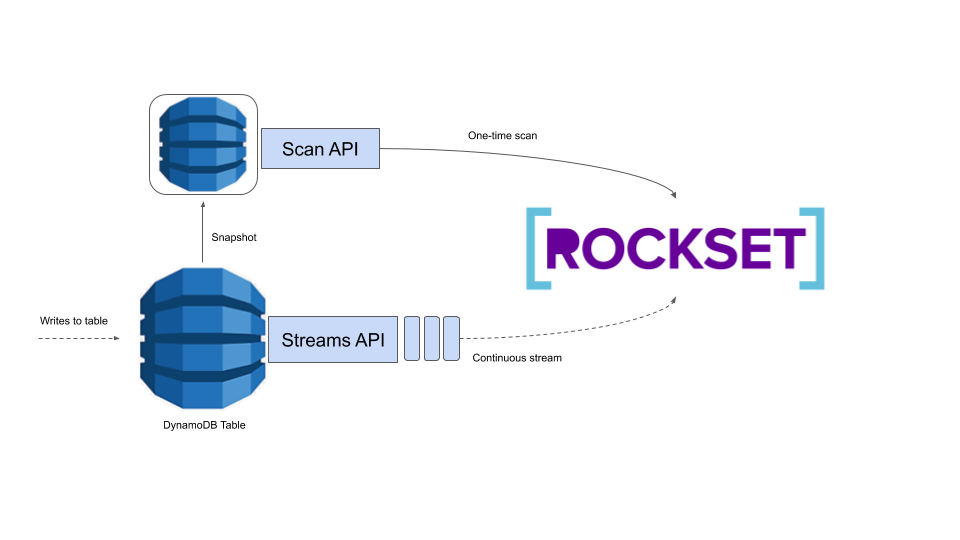
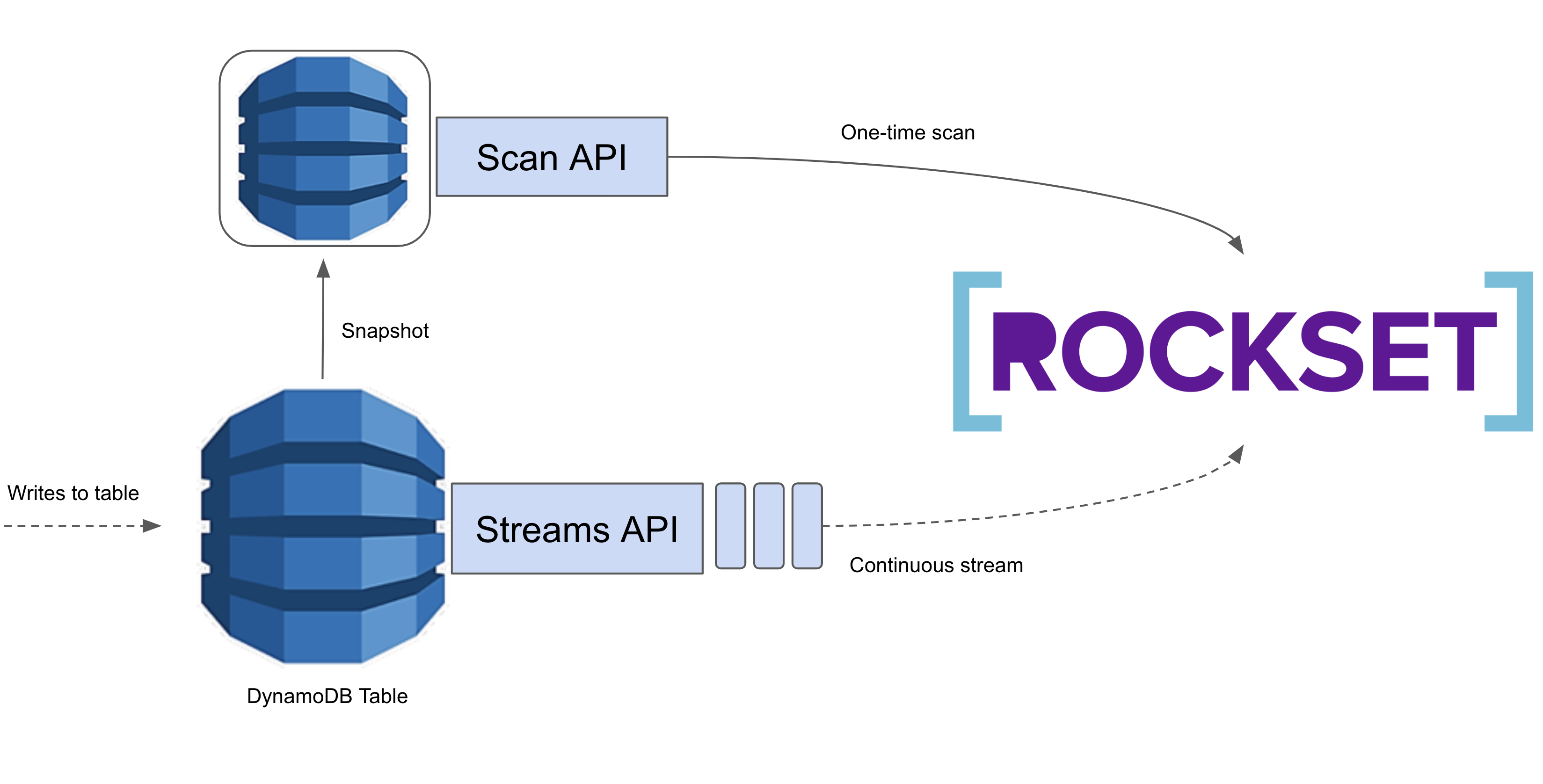
AWS presents a Scan API and a Streams API for studying knowledge from DynamoDB. The Scan API permits us to linearly scan a whole DynamoDB desk. That is costly, however generally unavoidable. We use the Scan API the primary time we load knowledge from a DynamoDB desk to a Rockset assortment, as we’ve got no technique of gathering all the information aside from scanning by way of it. After this preliminary load, we solely want to watch for updates, so utilizing the Scan API can be fairly wasteful. As an alternative, we use the Streams API which supplies us a time-ordered queue of updates utilized to the DynamoDB desk. We learn these updates and apply them into Rockset, giving customers realtime entry to their DynamoDB knowledge in Rockset!
The problem we’ve been endeavor is to make ingesting knowledge from DynamoDB into Rockset as seamless and cost-efficient as doable given the constraints offered by knowledge sources, like DynamoDB. Following, I’ll talk about just a few of points we bumped into in tuning and stabilizing each phases of our DynamoDB ingestion course of whereas conserving prices low for our customers.
Scans
How we measure scan efficiency
In the course of the scanning section, we purpose to constantly maximize our learn throughput from DynamoDB with out consuming greater than a user-specified variety of RCUs per desk. We wish ingesting knowledge into Rockset to be environment friendly with out interfering with current workloads operating on customers’ dwell DynamoDB tables.
Understanding the best way to set scan parameters
From very preliminary testing, we observed that our scanning section took fairly a very long time to finish so we did some digging to determine why. We ingested a DynamoDB desk into Rockset and noticed what occurred through the scanning section. We anticipated to constantly devour the entire provisioned throughput.
Initially, our RCU consumption appeared like the next:
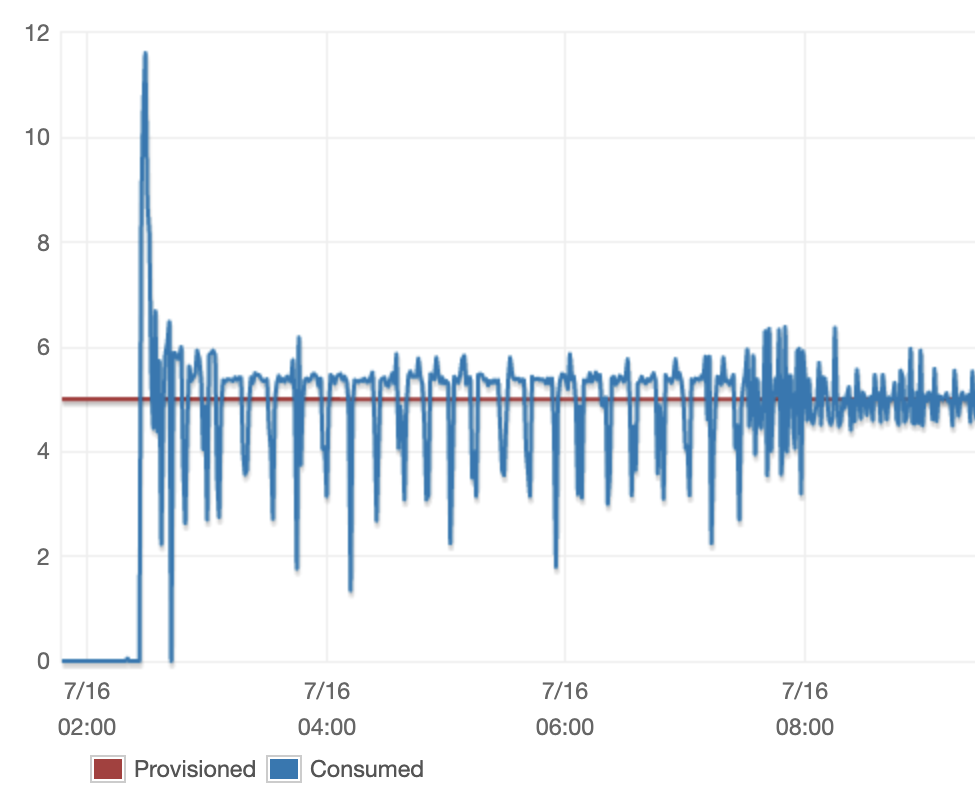
We noticed an inexplicable degree of fluctuation within the RCU consumption over time, notably within the first half of the scan. These fluctuations are unhealthy as a result of every time there’s a serious drop within the throughput, we find yourself lengthening the ingestion course of and rising our customers DynamoDB prices.
The issue was clear however the underlying trigger was not apparent. On the time, there have been just a few variables that we have been controlling fairly naively. DynamoDB exposes two vital variables: web page dimension and section rely, each of which we had set to fastened values. We additionally had our personal price limiter which throttled the variety of DynamoDB Scan API calls we made. We had additionally set the restrict this price limiter was implementing to a set worth. We suspected that certainly one of these variables being sub-optimally configured was the probably reason behind the huge fluctuations we have been observing.
Some investigation revealed that the reason for the fluctuation was primarily the speed limiter. It turned out the fastened restrict we had set on our price limiter was too low, so we have been getting throttled too aggressively by our personal price limiter. We determined to repair this downside by configuring our limiter primarily based on the quantity of RCU allotted to the desk. We are able to simply (and do plan to) transition to utilizing a user-specified variety of RCU for every desk, which is able to enable us to restrict Rockset’s RCU consumption even when customers have RCU autoscaling enabled.
public int getScanRateLimit(AmazonDynamoDB shopper, String tableName,
int numSegments) {
TableDescription tableDesc = shopper.describeTable(tableName).getTable();
// Be aware: this can return 0 if the desk has RCU autoscaling enabled
remaining lengthy tableRcu = tableDesc.getProvisionedThroughput().getReadCapacityUnits();
remaining int numSegments = config.getNumSegments();
return desiredRcuUsage / numSegments;
}
For every section, we carry out a scan, consuming capability on our price limiter as we devour DynamoDB RCU’s.
public void doScan(AmazonDynamoDb shopper, String tableName, int numSegments) {
RateLimiter rateLimiter = RateLimiter.create(getScanRateLimit(shopper,
tableName, numSegments))
whereas (!performed) {
ScanResult outcome = shopper.scan(/* feed scan request in */);
// do processing ...
rateLimiter.purchase(outcome.getConsumedCapacity().getCapacityUnits());
}
}
The results of our new Scan configuration was the next:
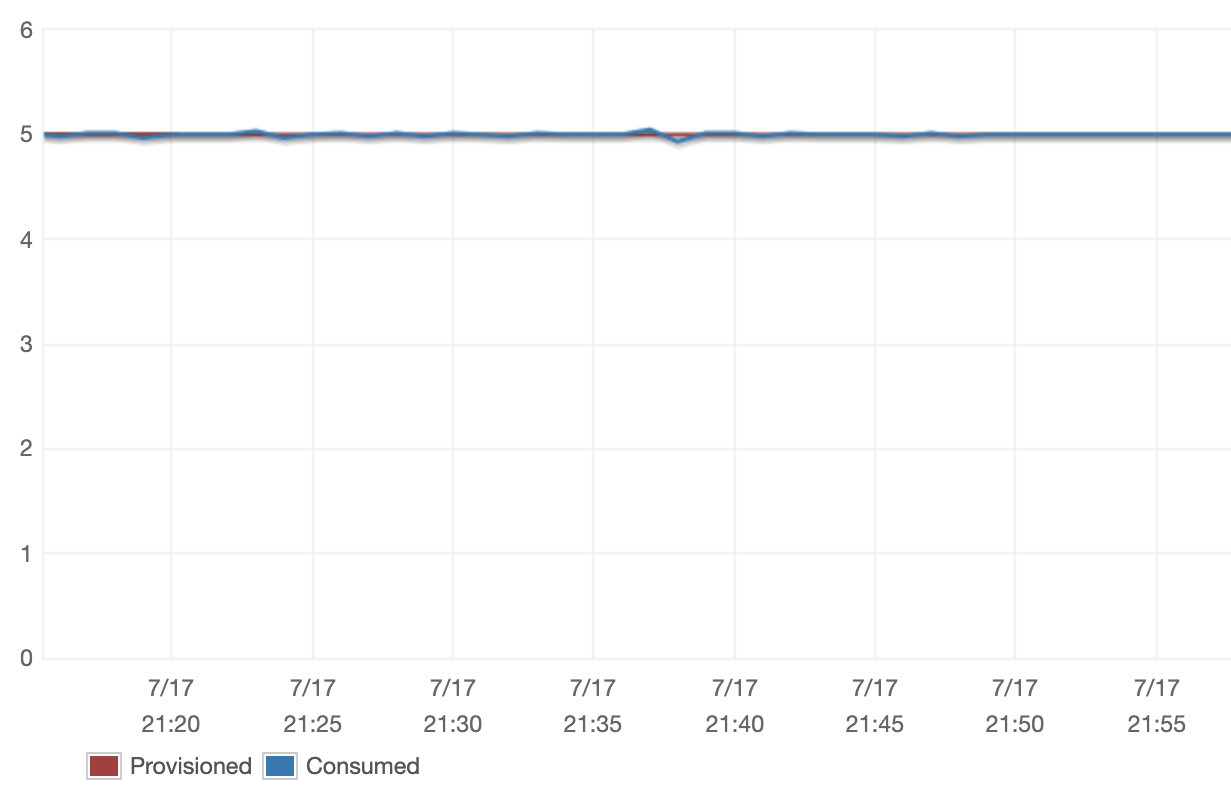
We have been joyful to see that, with our new configuration, we have been capable of reliably management the quantity of throughput we consumed. The issue we found with our price limiter dropped at gentle our underlying want for extra dynamic DynamoDB Scan configurations. We’re persevering with to run experiments to find out the best way to dynamically set the web page dimension and section rely primarily based on table-specific knowledge, however we additionally moved onto coping with a few of the challenges we have been going through with DynamoDB Streams.
Streams
How we measure streaming efficiency
Our objective through the streaming section of ingestion is to reduce the period of time it takes for an replace to enter Rockset after it’s utilized in DynamoDB whereas conserving the associated fee utilizing Rockset as little as doable for our customers. The first value issue for DynamoDB Streams is the variety of API calls we make. DynamoDB’s pricing permits customers 2.5 million free API calls and costs $0.02 per 100,000 requests past that. We wish to attempt to keep as near the free tier as doable.
Beforehand we have been querying DynamoDB at a price of ~300 requests/second as a result of we encountered a number of empty shards within the streams we have been studying. We believed that we’d have to iterate by way of all of those empty shards whatever the price we have been querying at. To mitigate the load we placed on customers’ Dynamo tables (and in flip their wallets), we set a timer on these reads after which stopped studying for five minutes if we didn’t discover any new information. Provided that this mechanism ended up charging customers who didn’t even have a lot knowledge in DynamoDB and nonetheless had a worst case latency of 5 minutes, we began investigating how we may do higher.
Lowering the frequency of streaming calls
We ran a number of experiments to make clear our understanding of the DynamoDB Streams API and decide whether or not we may scale back the frequency of the DynamoDB Streams API calls our customers have been being charged for. For every experiment, we diversified the period of time we waited between API calls and measured the typical period of time it took for an replace to a DynamoDB desk to be mirrored in Rockset.
Inserting information into the DynamoDB desk at a continuing price of two information/second, the outcomes have been as follows:

Inserting information into the DynamoDB desk in a bursty sample, the outcomes have been as follows:

The outcomes above confirmed that making 1 API name each second is lots to make sure that we keep sub-second latencies. Our preliminary assumptions have been fallacious, however these outcomes illuminated a transparent path ahead. We promptly modified our ingestion course of to question DynamoDB Streams for brand new knowledge solely as soon as per second so as give us the efficiency we’re searching for at a a lot diminished value to our customers.
Calculating our value discount
Since with DynamoDB Streams we’re immediately liable for our customers prices, we determined that we would have liked to exactly calculate the associated fee our customers incur because of the method we use DynamoDB Streams. There are two elements which wholly decide the quantity that customers shall be charged for DynamoDB Streams: the variety of Streams API calls made and the quantity of knowledge transferred. The quantity of knowledge transferred is basically past our management. Every API name response unavoidably transfers a small quantity (768 bytes) of knowledge. The remaining is all person knowledge, which is barely learn into Rockset as soon as. We targeted on controlling the variety of DynamoDB Streams API calls we make to customers’ tables as this was beforehand the motive force of our customers’ DynamoDB prices.
Following is a breakdown of the associated fee we estimate with our newly reworked ingestion course of:

We have been joyful to see that, with our optimizations, our customers ought to incur nearly no extra value on their DynamoDB tables resulting from Rockset!
Conclusion
We’re actually excited that the work we’ve been doing has efficiently pushed DynamoDB prices down for our customers whereas permitting them to work together with their DynamoDB knowledge in Rockset in realtime!
This can be a simply sneak peek into a few of the challenges and tradeoffs we’ve confronted whereas working to make ingesting knowledge from DynamoDB into Rockset as seamless as doable. In the event you’re excited by studying extra about the best way to operationalize your DynamoDB knowledge utilizing Rockset try a few of our latest materials and keep tuned for updates as we proceed to construct Rockset out!
If you would like to see Rockset and DynamoDB in motion, you need to try our transient product tour.
Different DynamoDB assets:

{kind=link}