

On this weblog submit, we current a high-level description of the methodology underpinning these feeds, which we now have documented in additional element in a paper accessible on ArXiv.
Drawback
Given historic and up to date prospects’ interactions, what are probably the most related gadgets to show on the house web page of each buyer from a given set of things equivalent to promotional gadgets or newly launched gadgets? To reply this query at scale, there are 4 challenges that we wanted to beat:
- Buyer illustration problem – Bol has greater than 13 million prospects with various pursuits and interplay conduct. How will we develop buyer profiles?
- Merchandise illustration problem – Bol has greater than 40 million gadgets on the market, every having its personal wealthy metadata and interplay information. How will we symbolize gadgets?
- Matching problem – how will we effectively and successfully match interplay information of 13 million prospects with probably 40 million gadgets?
- Rating problem – In what order will we present the highest N gadgets per buyer from a given set of related merchandise candidates?
On this weblog, we concentrate on addressing the primary three challenges.
Resolution
To deal with the three of the 4 challenges talked about above, we use embeddings. Embeddings are floating level numbers of a sure dimension (e.g. 128). They’re additionally known as representations or (semantic) vectors. Embeddings have semantics. They’re skilled in order that related objects have related embeddings, whereas dissimilar objects are skilled to have totally different embeddings. Objects may very well be any sort of knowledge together with textual content, picture, audio, and video. In our case, the objects are merchandise and prospects. As soon as embeddings can be found, they’re used for a number of functions equivalent to environment friendly similarity matching, clustering, or serving as enter options in machine studying fashions. In our case, we use them for environment friendly similarity matching. See Determine 1 for examples of merchandise embeddings.

Determine 1: Objects in a catalog are represented with embeddings, that are floating numbers of a sure dimension (e.g. 128). Embeddings are skilled to be related when gadgets have widespread traits or serve related features, whereas people who differ are skilled to have dissimilar embeddings. Embeddings are generally used for similarity matching. Any sort of knowledge might be embedded. Textual content (language information), tabular information, picture, and audio can all be embedded both individually or collectively.
The widespread method to utilizing embeddings for personalization is to depend on a user-item framework (see Determine 2). Within the user-item framework, customers and gadgets are represented with embeddings in a shared embedding area. Customers have embeddings that replicate their pursuits, derived from their historic searches, clicks and purchases, whereas gadgets have embeddings that seize the interactions on them and the metadata data accessible within the catalog. Personalization within the user-item framework works by matching person embeddings with the index of merchandise embeddings.
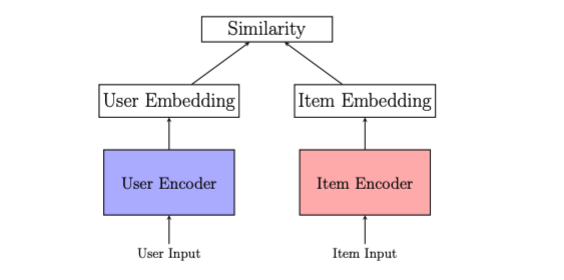
Determine 2: Person-to-item framework: Single vectors from the person encoder restrict illustration and interpretability as a result of customers have various and altering pursuits. Protecting person embeddings recent (i.e.capturing most up-to-date pursuits) calls for high-maintenance infrastructure due to the necessity to run the embedding mannequin with most up-to-date interplay information.
We began with the user-item framework and realized that summarizing customers with single vectors has two points:
- Single vector illustration bottleneck. Utilizing a single vector to symbolize prospects introduces challenges as a result of variety and complexity of person pursuits, compromising each the capability to precisely symbolize customers and the interpretability of the illustration by obscuring which pursuits are represented and which aren’t.
- Excessive infrastructure and upkeep prices. Producing and sustaining up-to-date person embeddings requires substantial funding when it comes to infrastructure and upkeep. Every new person motion requires executing the person encoder to generate recent embeddings and the next suggestions. Moreover, the person encoder have to be giant to successfully mannequin a sequence of interactions, resulting in costly coaching and inference necessities.
To beat the 2 points, we moved from a user-to-item framework to utilizing an item-to-item framework (additionally known as query-to-item or query-to-target framework). See Determine 3. Within the item-to-item framework, we symbolize customers with a set of question gadgets. In our case, question gadgets consult with gadgets that prospects have both seen or bought. On the whole, they might additionally embody search queries.

Determine 3: Question-to-item framework: Question embeddings and their similarities are precomputed. Customers are represented by a dynamic set of queries that may be up to date as wanted.
Representing customers with a set of question gadgets gives three benefits:
- Simplification of real-time deployment: Buyer question units can dynamically be up to date as interactions occur. And this may be finished with out operating any mannequin in real-time. That is attainable as a result of all gadgets within the catalog are recognized to be potential view or purchase queries, permitting for the pre-computation of outcomes for all queries.
- Enhanced interpretability: Any customized merchandise advice might be traced again to an merchandise that’s both seen or bought.
- Elevated computational effectivity: The queries which are used to symbolize customers are shared amongst customers. This permits computational effectivity because the question embeddings and their respective similarities might be re-used as soon as computed for any buyer.
Pfeed – A technique for producing customized feed
Our methodology for creating customized feed suggestions, which we name Pfeed, includes 4 steps (See Figures 4).
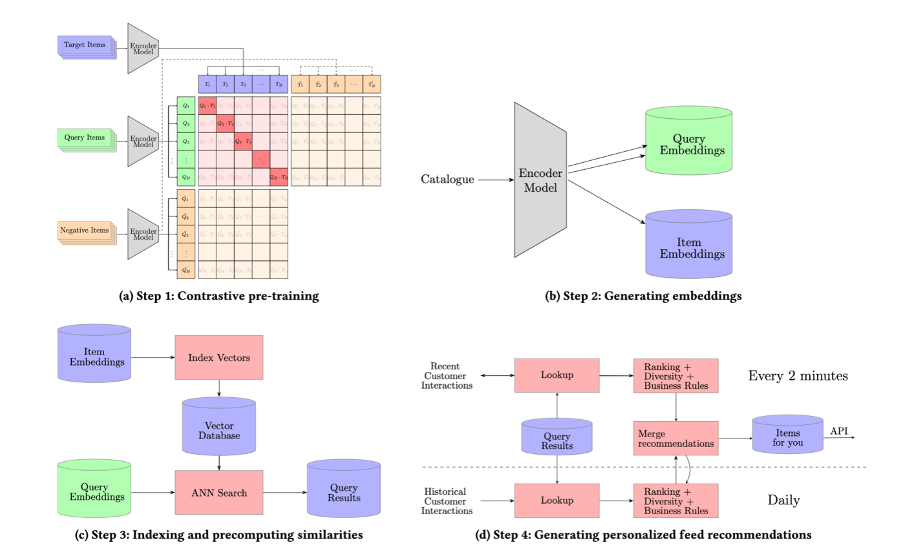
Determine 4: The most important steps concerned in producing close to real-time customized suggestions
Step 1 is about coaching a transformer encoder mannequin to seize the item-to-item relationships proven in Determine 5. Right here, our innovation is that we use three particular tokens to seize the distinct roles that gadgets play in numerous contexts: view question, purchase question and, goal merchandise.
View queries are gadgets clicked throughout a session resulting in the acquisition of particular gadgets, thus creating view-buy relationships. Purchase queries, then again, are gadgets continuously bought along side or shortly earlier than different gadgets, establishing buy-buy relationships.
We consult with the gadgets that observe view or purchase queries as goal gadgets. A transformer mannequin is skilled to seize the three roles of an merchandise utilizing three distinct embeddings. As a result of our mannequin generates the three embeddings of an merchandise in a single shot, we name it a SIMO mannequin (Single Enter Multi Output Mannequin). See paper for extra particulars relating to the structure and the coaching technique.
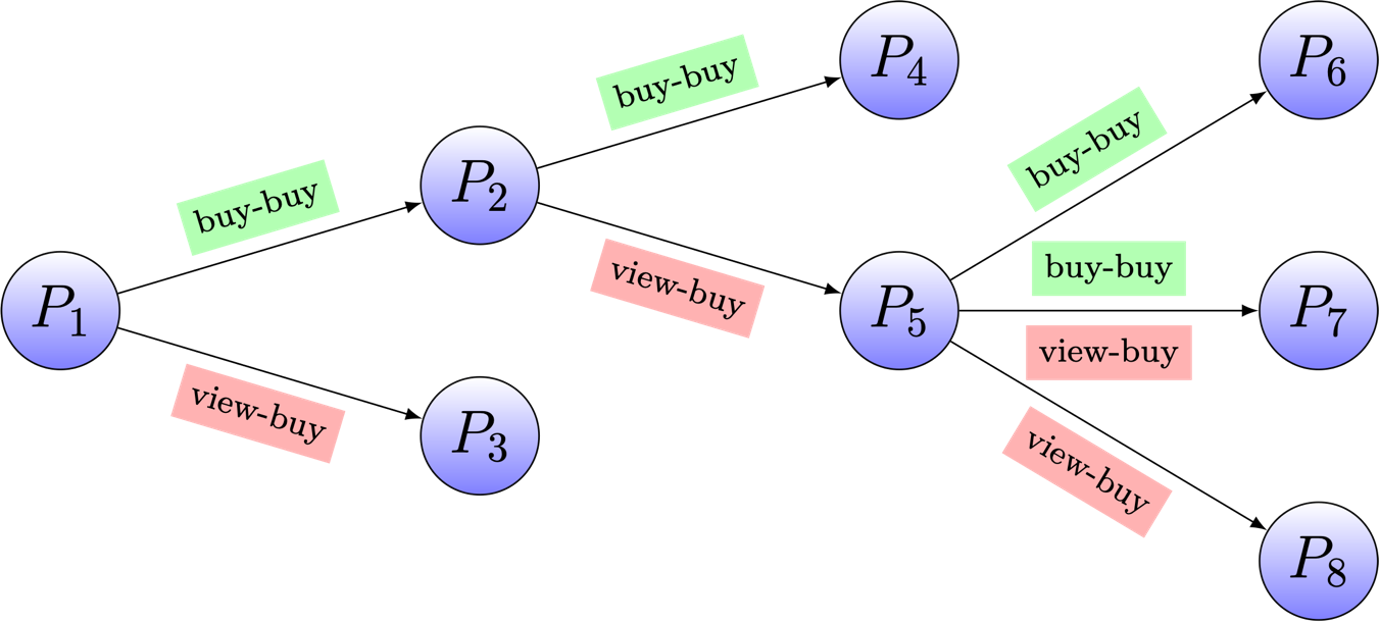
Determine 5: Product relationships: most prospects that purchase P_2 additionally purchase P_4, ensuing right into a buy-buy relationship. Most prospects that view product P_2 find yourself shopping for P_5, ensuing right into a view-buy relationship. On this instance, P_2 performs three kinds of roles – view question, purchase question ,and goal merchandise. The purpose of coaching an encoder mannequin is to seize these current item-to-item relationships after which generalize this understanding to incorporate new potential connections between gadgets, thereby increasing the graph with believable new item-to-item relationships.
Step 2 is about utilizing the transformer encoder skilled in step 1 and producing embeddings for all gadgets within the catalog.
Step 3 is about indexing the gadgets that have to be matched (e.g. gadgets with promotional labels or gadgets which are new releases). The gadgets which are listed are then matched towards all potential queries (seen or bought gadgets). The outcomes of the search are then saved in a lookup desk.
Step 4 is about producing customized feeds per buyer primarily based on buyer interactions and the lookup desk from step 3. The method for producing a ranked listing of things per person consists of: 1) deciding on queries for every buyer (as much as 100), 2) retrieving as much as 10 potential subsequent items- to-buy for every question, and three) combining this stuff and making use of rating, variety, and enterprise standards (See Determine 4d). This course of is executed every day for all prospects and each two minutes for these energetic within the final two minutes. Suggestions ensuing from current queries are prioritized over these from historic ones. All these steps are orchestrated with Airflow.
Purposes of Pfeed
We utilized Pfeed to generate varied customized feeds at Bol, viewable on the app or web site with titles like Prime offers for you, Prime picks for you, and New for you. The feeds differ on not less than one among two components: the precise gadgets focused for personalization and/or the queries chosen to symbolize buyer pursuits. There may be additionally one other feed known as Choose Offers for you. On this feed, gadgets with Choose Offers are customized solely for Choose members, prospects who pay annual charges for sure advantages. You could find Choose Offers for you on empty baskets.
On the whole, Pfeed is designed to generate”X for you” feed by limiting the search index or the search output to include solely gadgets belonging to class 𝑋 for all potential queries.
Analysis
We carry out two kinds of analysis – offline and on-line. The offline analysis is used for fast validation of the effectivity and high quality of embeddings. The web analysis is used to evaluate the impression of the embeddings in personalizing prospects’ homepage experiences.
Offline analysis
We use about two million matching query-target pairs and about a million random gadgets for coaching, validation and testing within the proportion of 80%, 10%, %10. We randomly choose one million merchandise from the catalog, forming a distractor set, which is then combined with the true targets within the take a look at dataset. The target of analysis is to find out, for recognized matching query-target pairs, the share of occasions the true targets are among the many prime 10 retrieved gadgets for his or her respective queries inthe embedding area utilizing dot product (Recall@10). The upper the rating, the higher. Desk 1 exhibits that two embedding fashions, known as SIMO-128 and SISO-128, obtain comparable Recall@10 scores. The SIMO-128 mannequin generates three 128 dimensional embeddings in a single shot, whereas the SISO-128 generates the identical three 128-dimensional embeddings however in three separate runs. The effectivity benefit of SIMO-128 implies that we will generate embeddings for your entire catalog a lot sooner with out sacrificing embedding high quality.
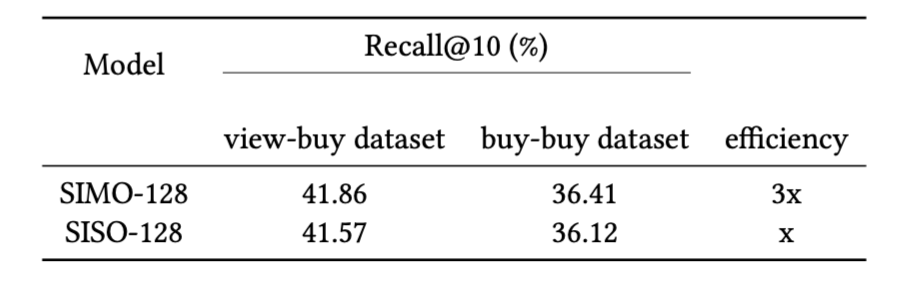
Desk 1: Recall@Okay on view-buy and buy-buy datasets. The SIMO-128 mannequin performs comparably to the SISO-128 mannequin whereas being 3 occasions extra environment friendly throughout inference.
The efficiency scores in Desk 1 are computed from an encoder mannequin that generates 128-dimensional embeddings. What occurs if we use bigger dimensions? Desk 2 gives the reply to that query. After we enhance the dimensionality of embeddings with out altering every other side, bigger dimensional vectors have a tendency to provide larger high quality embeddings, as much as a sure restrict.
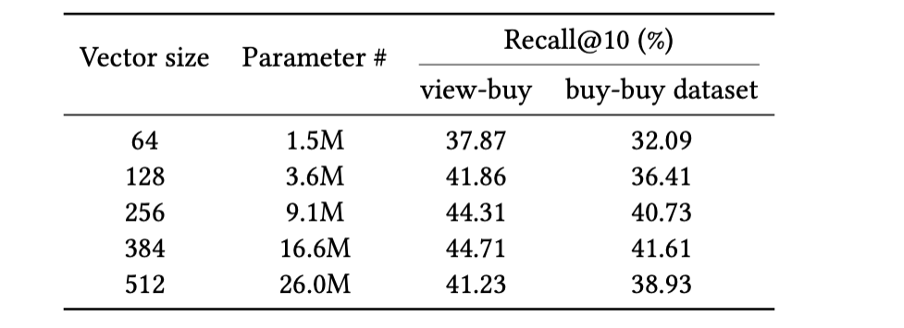
Desk 2: Affect of hidden dimension vector dimension on Recall@Okay. Protecting different components of the mannequin the identical and rising solely the hidden dimension results in elevated efficiency till a sure restrict.
One difficult side in Pfeed is dealing with query-item pairs with complicated relations (1-to-many, many-to-one, and many-to-many). An instance is a diaper buy.
There are fairly just a few gadgets which are equally more likely to be bought together with or shortly earlier than/after the acquisition of diaper gadgets equivalent to child garments and toys.
Such complicated query-item relations are more durable to seize with embeddings. Desk 3 exhibits Recall@10 scores for various ranges of relationship complexity. Efficiency on query-to-item with complicated relations is decrease than these with easy relations (1-to-1 relation).
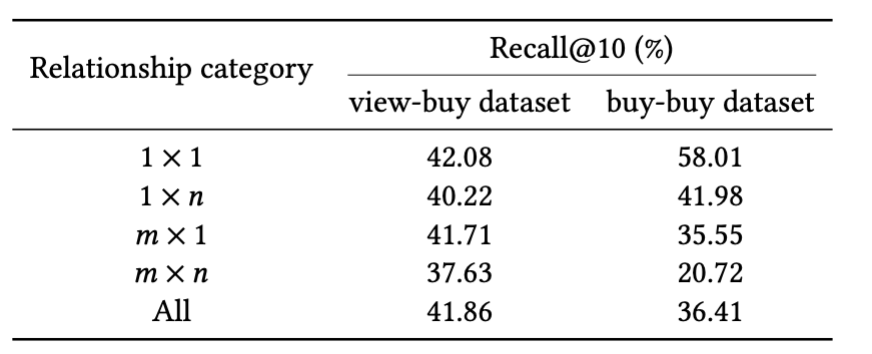
Desk 3: Retrieval efficiency is larger on take a look at information with easy 1 x 1 relations than with complicated relations (1 x n, m x 1 and m x n relations).
On-line experiment
We ran a web based experiment to guage the enterprise impression of Pfeed. We in contrast a remedy group receiving customized Prime offers for you merchandise lists (generated by Pfeed) towards a management group that obtained a non-personalized Prime offers listing, curated by promotion specialists.
This experiment was performed over a two-week interval with an excellent 50- 50 break up between the 2 teams. Customized prime offers suggestions result in a 27% enhance in engagement (want listing additions) and a 4.9% uplift in conversion in comparison with expert-curated non-personalized prime offers suggestions (See Desk 4).

Desk 4: Customized prime offers suggestions result in a 27% enhance in engagement (want listing additions) and a 4.9% uplift in conversion in comparison with expert-curated non-personalized prime offers suggestions.
Conclusions and future work
We launched Pfeed, a way deployed at Bol for producing customized product feeds: Prime offers for you, Prime picks for you, New for you, and Choose offers for you. Pfeed makes use of a query-to-item framework, which differs from the dominant user-item framework in customized recommender methods. We highlighted three advantages: 1) Simplified real-time deployment. 2) Improved interpretability. 3) Enhanced computational effectivity.
Future work on Pfeed will concentrate on increasing the mannequin embedding capabilities to deal with complicated query-to-item relations equivalent to that of diaper gadgets being co-purchased with various different child gadgets. Second line of future work can concentrate on dealing with specific modelling of generalization and memorization of relations, adaptively selecting both method primarily based on frequency. Continuously occurring query-to-item pairs may very well be memorized and people who contain tail gadgets (low frequency or newly launched gadgets) may very well be modelled primarily based on content material options equivalent to title and descriptions. At present, Pfeed solely makes use of content material for modelling each head and tail gadgets.
If any such work conjures up you or you’re searching for new challenges, take into account checking for accessible alternatives on bol’s careers web site.
Acknowledgements
We thank Nick Tinnemeier and Eryk Lewinson for suggestions on this submit.

{kind=link}