
Kubernetes at Rockset
At Rockset, we use Kubernetes (k8s) for cluster orchestration. It runs all our manufacturing microservices — from our ingest staff to our query-serving tier. Along with internet hosting all of the manufacturing infrastructure, every engineer has their very own Kubernetes namespace and devoted assets that we use to regionally deploy and take a look at new variations of code and configuration. This sandboxed atmosphere for growth permits us to make software program releases confidently a number of instances each week. On this weblog publish, we are going to discover a instrument we constructed internally that provides us visibility into Kubernetes occasions, a wonderful supply of details about the state of the system, which we discover helpful in troubleshooting the system and understanding its long-term well being.
Why We Care About Kubernetes Occasions
Kubernetes emits occasions each time some change happens in any of the assets that it’s managing. These occasions usually comprise vital metadata concerning the entity that triggered it, the kind of occasion (Regular, Warning, Error, and so on.) and the trigger. This knowledge is often saved in etcd and made out there whenever you run sure kubectl instructions.
$ kubectl describe pods jobworker-c5dc75db8-7m5ln
...
...
...
Occasions:
Kind Motive Age From Message
---- ------ ---- ---- -------
Regular Scheduled 7m default-scheduler Efficiently assigned grasp/jobworker-c5dc75db8-7m5ln to ip-10-202-41-139.us-west-2.compute.inner
Regular Pulling 6m kubelet, ip-XXX-XXX-XXX-XXX.us-west-2.compute.inner pulling picture "..."
Regular Pulled 6m kubelet, ip-XXX-XXX-XXX-XXX.us-west-2.compute.inner Efficiently pulled picture "..."
Regular Created 6m kubelet, ip-XXX-XXX-XXX-XXX.us-west-2.compute.inner Created container
Regular Began 6m kubelet, ip-XXX-XXX-XXX-XXX.us-west-2.compute.inner Began container
Warning Unhealthy 2m (x2 over 2m) kubelet, ip-XXX-XXX-XXX-XXX.us-west-2.compute.inner Readiness probe failed: Get http://XXX.XXX.XXX.XXX:YYY/healthz: dial tcp join: connection refused
These occasions assist perceive what occurred behind the scenes when a selected entity entered a particular state. One other place to see an aggregated checklist of all occasions is by accessing all occasions by way of kubectl get occasions.
$ kubectl get occasions
LAST SEEN TYPE REASON KIND MESSAGE
5m Regular Scheduled Pod Efficiently assigned grasp/jobworker-c5dc75db8-7m5ln to ip-XXX-XXX-XXX-XXX.us-west-2.compute.inner
5m Regular Pulling Pod pulling picture "..."
4m Regular Pulled Pod Efficiently pulled picture "..."
...
...
...
As will be seen above, this provides us particulars – the entity that emitted the occasion, the kind/severity of the occasion, in addition to what triggered it. This info could be very helpful when seeking to perceive modifications which might be occurring within the system. One extra use of those occasions is to know long-term system efficiency and reliability. For instance, sure node and networking errors that trigger pods to restart could not trigger service disruptions in a extremely out there setup however usually will be hiding underlying circumstances that place the system at elevated danger.
In a default Kubernetes setup, the occasions are persevered into etcd, a key-value retailer. etcd is optimized for fast strongly constant lookups, however falls quick on its skill to supply analytical skills over the info. As dimension grows, etcd additionally has hassle maintaining and subsequently, occasions get compacted and cleaned up periodically. By default, solely the previous hour of occasions is preserved by etcd.
The historic context can be utilized to know long-term cluster well being, incidents that occurred up to now and the actions taken to mitigate them inside Kubernetes, and construct correct publish mortems. Although we checked out different monitoring instruments for occasions, we realized that we had a possibility to make use of our personal product to research these occasions in a approach that no different monitoring product might, and use it to assemble a visualization of the states of all of our Kubernetes assets.

Overview
To ingest the Kubernetes occasions, we use an open supply instrument by Heptio known as eventrouter. It reads occasions from the Kubernetes API server and forwards them to a specified sink. The sink will be something from Amazon S3 to an arbitrary HTTP endpoint. With a purpose to hook up with a Rockset assortment, we determined to construct a Rockset connector for eventrouter to regulate the format of the info uploaded to our assortment. We contributed this Rockset sink into the upstream eventrouter challenge. This connector is absolutely easy — it takes all acquired occasions and emits them into Rockset. The actually cool half is that for ingesting these occasions, that are JSON payloads that adjust throughout various kinds of entities, we don’t must construct any schema or do structural transformations. We will emit the JSON occasion as-is right into a Rockset assortment and question it as if it have been a full SQL desk. Rockset mechanically converts JSON occasions into SQL tables by first indexing all of the json fields utilizing Converged Indexing after which mechanically schematizing them by way of Good Schemas.
The front-end utility is a skinny layer over the SQL layer that permits filtering occasions by namespace and entity kind (Pod, Deployment, and so on.), after which inside these entity sorts, cluster occasions by regular/errors. The aim is to have a histogram of those occasions to visually examine and perceive the state of the cluster over an prolonged time frame. After all, what we reveal is solely a subset of what may very well be constructed – one can think about rather more advanced analyses – like analyzing community stability, deployment processes, canarying software program releases and even utilizing the occasion retailer as a key diagnostic instrument to find correlations between cluster-level alerts and Kubernetes-level modifications.
Setup
Earlier than we will start receiving occasions from eventrouter into Rockset, we should create a group in Rockset. That is the gathering that each one eventrouter occasions are saved in. You are able to do this with a free account from https://console.rockset.com/create.
A set in Rockset can ingest knowledge from a specified supply, or will be despatched occasions by way of the REST API. We’ll use the latter, so, we create a group that’s backed by this Write API. Within the Rockset console, we will create such a group by choosing “Write API” as the info supply.

When creating the gathering, we will choose a retention, say, 120 days or any cheap period of time to provide us some sense of cluster well being. This retention is utilized based mostly on a particular area in Rockset, _event_time. We’ll map this area to a particular area inside the JSON occasion payload we are going to obtain from eventrouter known as occasion.lastTimestamp. The transformation perform seems to be like the next:
UNIX_MILLIS(PARSE_TIMESTAMP_ISO8601(occasion.lastTimestamp))
After creating the gathering, we will now arrange and use eventrouter to start receiving Kubernetes occasions.

Now, receiving occasions from eventrouter requires yet one more factor – a Rockset API key. We will use API keys in Rockset to put in writing JSON to a group, and to make queries. On this case, we create an API key known as eventrouter_write from Handle > API keys.

Copy the API key as we would require it in our subsequent step organising eventrouter to ship occasions into the Rockset assortment we simply arrange. You’ll be able to arrange eventrouter by cloning the eventrouter repository and edit the YAML file yaml/deployment.yaml to appear to be the next:
# eventrouter/yaml/deployment.yaml
config.json: |-
{
"sink": "rockset"
"rocksetServer": "https://api.rs2.usw2.rockset.com",
"rocksetAPIKey": "<API_KEY>",
"rocksetCollectionName": "eventrouter_events",
"rocksetWorkspaceName": "commons",
}
You’ll be able to substitute the <API_KEY> with the Rockset API key we simply created within the earlier step. Now, we’re prepared! Run kubectl apply -f yaml/deployment.yaml, and eventrouter can begin watching and forwarding occasions immediately. Wanting on the assortment inside Rockset, it is best to begin seeing occasions flowing in and being made out there as a SQL desk. We will question it as proven beneath from the Rockset console and get a way of among the occasions flowing in. We will run full SQL over it – together with all sorts of filters, joins, and so on.

Querying Knowledge
We will now begin asking some fascinating questions from our cluster and get an understanding of cluster well being. One query that we wished to ask was – how usually are we deploying new photos into manufacturing. We operated on a strict launch schedule, however there are occasions after we rollout and rollback photos.
With replicasets as (
choose
e.occasion.purpose as purpose,
e.occasion.lastTimestamp as ts,
e.occasion.metadata.title as title,
REGEXP_EXTRACT(e.occasion.message, 'Created pod: (.*)', 1) as pod
from
commons.eventrouter_events e
the place
e.occasion.involvedObject.variety = 'ReplicaSet'
and e.occasion.metadata.namespace="manufacturing"
and e.occasion.purpose = 'SuccessfulCreate'
),
pods as (
choose
e.occasion.purpose as purpose,
e.occasion.message as message,
e.occasion.lastTimestamp as ts,
e.occasion.involvedObject.title as title,
REGEXP_EXTRACT(
e.occasion.message,
'pulling picture "imagerepo/folder/(.*?)"',
1
) as picture
from
commons.eventrouter_events e
the place
e.occasion.involvedObject.variety = 'Pod'
and e.occasion.metadata.namespace="manufacturing"
and e.occasion.message like '%pulling picture%'
and e.occasion.involvedObject.title like 'aggregator%'
)
SELECT * from (
choose
MAX(p.ts) as ts, MAX(r.pod) as pod, MAX(p.picture) as picture, r.title
from
pods p
JOIN replicasets r on p.title = r.pod
GROUP BY r.title) sq
ORDER BY ts DESC
restrict 100;
The above question offers with our deployments, which in flip create replicasets and finds the final date on which we deployed a selected picture.
+------------------------------------------+----------------------------------------+-----------------------------+----------------+
| picture | title | pod | ts |
|------------------------------------------+----------------------------------------+-----------------------------+----------------|
| leafagg:0.6.14.20190928-58cdee6dd4 | aggregator-c478b597.15c8811219b0c944 | aggregator-c478b597-z8fln | 2019-09-28T04:53:05Z |
| leafagg:0.6.14.20190928-58cdee6dd4 | aggregator-c478b597.15c881077898d3e0 | aggregator-c478b597-wvbdb | 2019-09-28T04:52:20Z |
| leafagg:0.6.14.20190928-58cdee6dd4 | aggregator-c478b597.15c880742e034671 | aggregator-c478b597-j7jjt | 2019-09-28T04:41:47Z |
| leafagg:0.6.14.20190926-a553e0af68 | aggregator-587f77c45c.15c8162d63e918ec | aggregator-587f77c45c-qjkm7 | 2019-09-26T20:14:15Z |
| leafagg:0.6.14.20190926-a553e0af68 | aggregator-587f77c45c.15c8160fefed6631 | aggregator-587f77c45c-9c47j | 2019-09-26T20:12:08Z |
| leafagg:0.6.14.20190926-a553e0af68 | aggregator-587f77c45c.15c815f341a24725 | aggregator-587f77c45c-2pg6l | 2019-09-26T20:10:05Z |
| leafagg:0.6.14.20190924-b2e6a85445 | aggregator-58d76b8459.15c77b4c1c32c387 | aggregator-58d76b8459-4gkml | 2019-09-24T20:56:02Z |
| leafagg:0.6.14.20190924-b2e6a85445 | aggregator-58d76b8459.15c77b2ee78d6d43 | aggregator-58d76b8459-jb257 | 2019-09-24T20:53:57Z |
| leafagg:0.6.14.20190924-b2e6a85445 | aggregator-58d76b8459.15c77b131e353ed6 | aggregator-58d76b8459-rgcln | 2019-09-24T20:51:58Z |
+------------------------------------------+----------------------------------------+-----------------------------+----------------+
This excerpt of photos and pods, with timestamp, tells us rather a lot about the previous couple of deploys and after they occurred. Plotting this on a chart would inform us about how constant we have now been with our deploys and the way wholesome our deployment practices are.
Now, transferring on to efficiency of the cluster itself, operating our personal hand-rolled Kubernetes cluster means we get a number of management over upgrades and the system setup however it’s value seeing when nodes could have been misplaced/community partitioned inflicting them to be marked as unready. The clustering of such occasions can inform us rather a lot concerning the stability of the infrastructure.
With nodes as (
choose
e.occasion.purpose,
e.occasion.message,
e.occasion.lastTimestamp as ts,
e.occasion.metadata.title
from
commons.eventrouter_events e
the place
e.occasion.involvedObject.variety = 'Node'
AND e.occasion.kind="Regular"
AND e.occasion.purpose = 'NodeNotReady'
ORDER by ts DESC
)
choose
*
from
nodes
Restrict 100;
This question offers us the instances the node standing went NotReady and we will attempt to cluster this knowledge utilizing SQL time capabilities to know how usually points are occurring over particular buckets of time.
+------------------------------------------------------------------------------+--------------------------------------------------------------+--------------+----------------------+
| message | title | purpose | ts |
|------------------------------------------------------------------------------+--------------------------------------------------------------+--------------+----------------------|
| Node ip-xx-xxx-xx-xxx.us-xxxxxx.compute.inner standing is now: NodeNotReady | ip-xx-xxx-xx-xxx.us-xxxxxx.compute.inner.yyyyyyyyyyyyyyyy | NodeNotReady | 2019-09-30T02:13:19Z |
| Node ip-xx-xxx-xx-xxx.us-xxxxxx.compute.inner standing is now: NodeNotReady | ip-xx-xxx-xx-xxx.us-xxxxxx.compute.inner.yyyyyyyyyyyyyyyy | NodeNotReady | 2019-09-30T02:13:19Z |
| Node ip-xx-xxx-xx-xxx.us-xxxxxx.compute.inner standing is now: NodeNotReady | ip-xx-xxx-xx-xxx.us-xxxxxx.compute.inner.yyyyyyyyyyyyyyyy | NodeNotReady | 2019-09-30T02:14:20Z |
| Node ip-xx-xxx-xx-xxx.us-xxxxxx.compute.inner standing is now: NodeNotReady | ip-xx-xxx-xx-xxx.us-xxxxxx.compute.inner.yyyyyyyyyyyyyyyy | NodeNotReady | 2019-09-30T02:13:19Z |
| Node ip-xx-xxx-xx-xx.us-xxxxxx.compute.inner standing is now: NodeNotReady | ip-xx-xxx-xx-xx.us-xxxxxx.compute.inner.yyyyyyyyyyyyyyyy | NodeNotReady | 2019-09-30T00:10:11Z |
+------------------------------------------------------------------------------+--------------------------------------------------------------+--------------+----------------------+
We will moreover search for pod and container stage occasions like after they get OOMKilled and correlate that with different occasions occurring within the system. In comparison with a time sequence database like prometheus, the ability of SQL lets us write and JOIN various kinds of occasions to attempt to piece collectively various things that occurred round a selected time interval, which can be causal.
For visualizing occasions, we constructed a easy instrument that makes use of React that we use internally to look by and do some primary clustering of Kubernetes occasions and errors occurring in them. We’re releasing this dashboard into open supply and would like to see what the neighborhood may use this for. There are two foremost elements to the visualization of Kubernetes occasions. First is a high-level overview of the cluster at a per-resource granularity. This enables us to see a realtime occasion stream from our deployments and pods, and to see at what state each single useful resource in our Kubernetes system is. There’s additionally an choice to filter by namespace – as a result of sure units of providers run in their very own namespace, this enables us to drill down into a particular namespace to take a look at occasions.

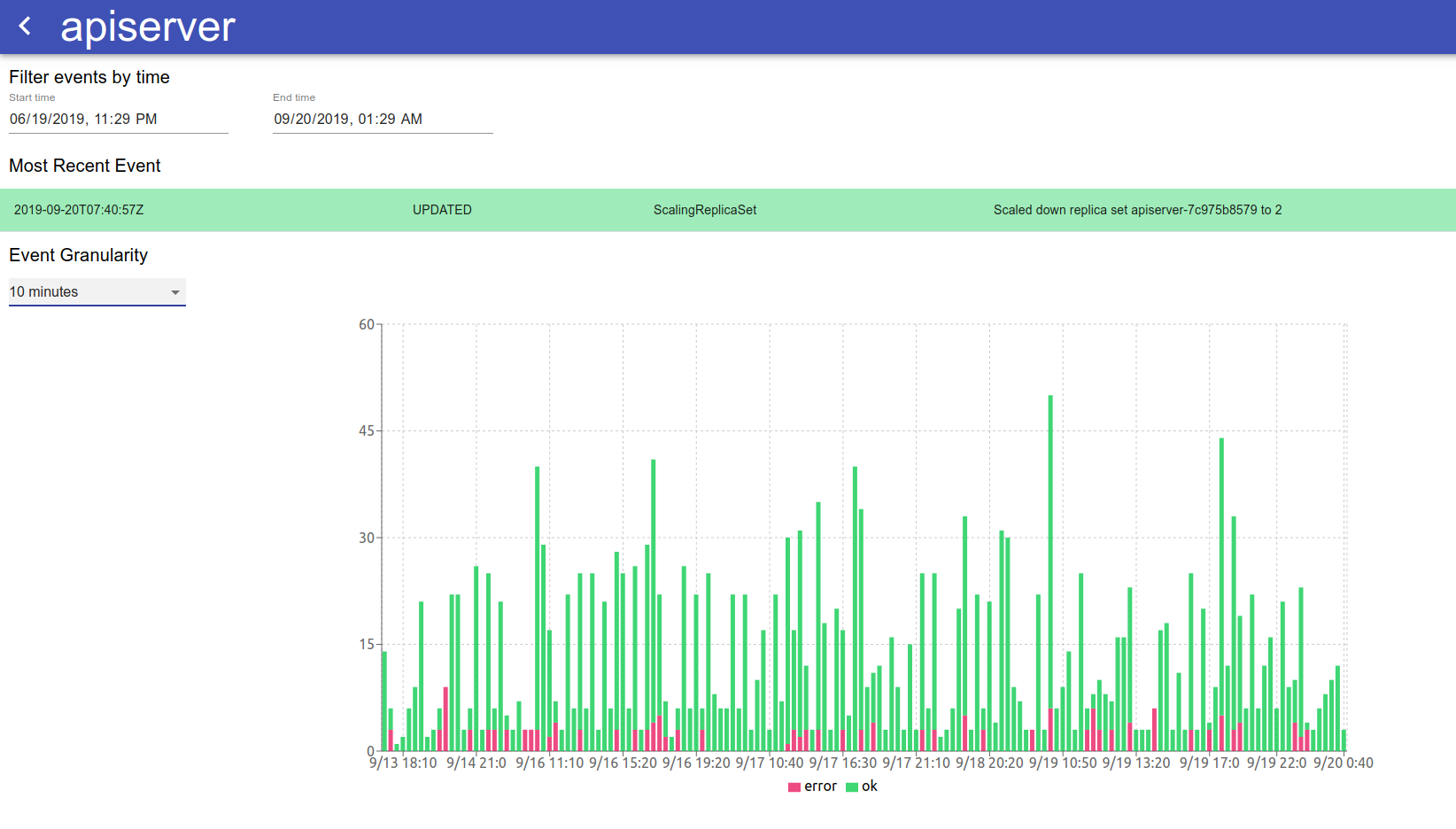
If we have an interest within the well being and state of any explicit useful resource, every per-resource abstract is clickable and opens a web page with an in depth overview of the occasion logs of that useful resource, with a graph that reveals the occasions and errors over time to supply a holistic image of how the useful resource is being managed.

The graph on this visualization has adjustable granularity, and the change in time vary permits for viewing the occasions for a given useful resource over any specified interval. Hovering over a particular bar on the stacked bar chart permits us to see the sorts of errors occurring throughout that point interval for useful over-time analytics of what’s occurring to a particular useful resource. The desk of occasions listed beneath the graph is sorted by occasion time and in addition tells incorporates the identical info because the graph – that’s, a chronological overview of all of the occasions that occurred to this particular k8s useful resource. The graph and desk are useful methods to know why a Kubernetes useful resource has been failing up to now, and any traits over time that will accompany that failure (for instance, if it coincides with the discharge of a brand new microservice).
Conclusion
At the moment, we’re utilizing the real-time visualization of occasions to research our personal Kubernetes deployments in each growth and manufacturing. This instrument and knowledge supply permits us to see our deployments as they’re ongoing with out having to wrangle the kubectl interface to see what’s damaged and why. Moreover, this instrument is useful to get a retrospective look on previous incidents. For instance – if we spot transient points, we now have the ability to return in time and take a retrospective have a look at transient manufacturing points, discovering patterns of why it might have occurred, and what we will do to forestall the incident from occurring once more sooner or later.
The flexibility to entry historic Kubernetes occasion logs at wonderful granularity is a strong abstraction that gives us at Rockset a greater understanding of the state of our Kubernetes system than kubectl alone would enable us. This distinctive knowledge supply and visualization permits us to watch our deployments and assets, in addition to have a look at points from a historic perspective. We’d love so that you can do this, and contribute to it if you happen to discover it helpful in your individual environments!
Hyperlink: https://github.com/rockset/recipes/tree/grasp/k8s-event-visualization

{kind=link}