

This weblog submit is in collaboration with Lawrence Whittle (Chief Business Officer) at Verana Well being.
Throughout industries, information scientists spend as much as 80% of their time attempting to correctly put together and cleanse datasets for information mining and synthetic intelligence (AI). For scientific researchers, life science analysts, and healthcare professionals, this problem is amplified by the added regulatory burdens round healthcare information, requiring affected person information to be anonymized whereas nonetheless offering demographic and inhabitants data essential to appropriate for bias. The information problem in healthcare is exacerbated by the truth that as much as 80% of the info is unstructured.
For this reason Verana Well being got here into existence. In partnership with three main medical societies, we’ve got constructed an unique, real-world information community of greater than 20,000 healthcare clinicians, roughly 90 million de-identified sufferers and greater than 500 million affected person visits. By offering high-quality, curated datasets (Qdata®), prepared for exploration by researchers and information scientists, we will help clinicians and life sciences corporations speed up medical innovation.
Our Verana Well being prospects and companions make the most of these datasets to assist determine trial sufferers, perceive population-level impression of public well being coverage selections, and monitor the security and therapy patterns of sufferers receiving their medicine. When you think about that the typical drug discovery course of takes a couple of decade and prices about $1-2 billion per drug, accelerating the method by even a single month may translate into tens of thousands and thousands of {dollars} in financial savings or accelerated income. The true distinction between Verana Well being’s Qdata choices, in comparison with the final information market, is high quality. High quality is outlined throughout a number of dimensions resembling cohort dimension, longitudinal nature (~10 years of information), and most significantly, depth of variables which might be a direct results of our method to reap beforehand untapped variables from unstructured information that has traditionally been locked in scientific notes and pictures.
So, how will we flip all of that information into insights? We use the Databricks Lakehouse to ingest, course of, and set up our petabyte-scale information warehouse of well being data.
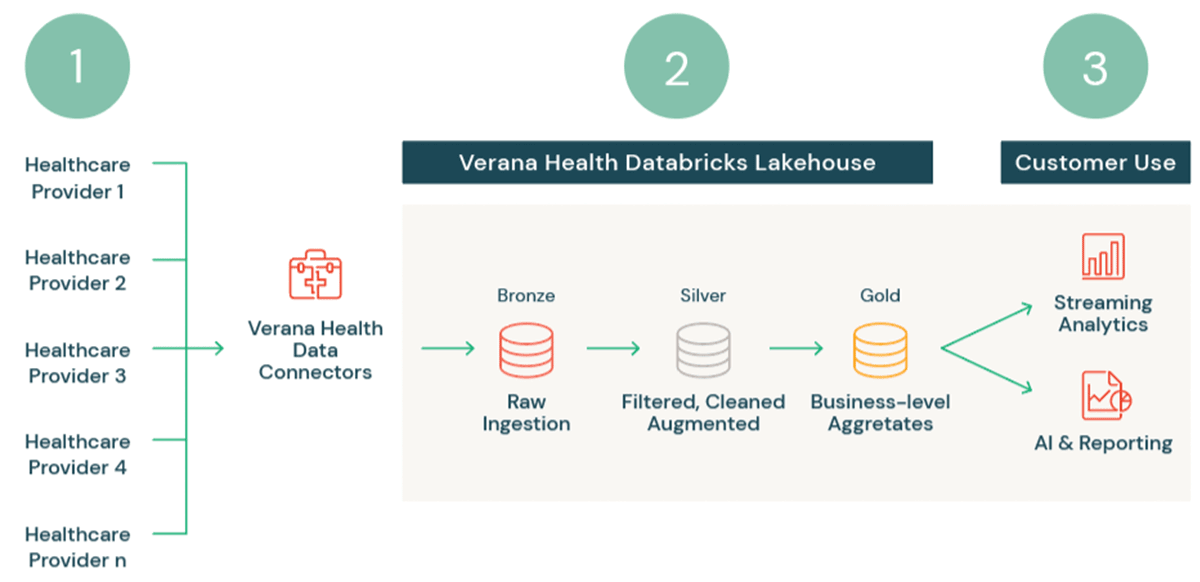
Verana Well being runs on Databricks Lakehouse
The Databricks and Verana Well being collaboration is a crucial factor for the availability of high-quality datasets to the life sciences and clinician market. The built-in options normalize and curate petabytes of well being data throughout three therapeutic areas of neurology, ophthalmology and urology. This allows Verana Well being to leverage the info for scientific trial optimization, real-world proof research, inhabitants well being analytics, and publication of Advantage-based Incentive Fee System high quality measures for Facilities for Medicare and Medicaid Providers (CMS) reporting.
To begin, we pull the info into the Lakehouse from our unique community of specialty medical society companions utilizing purpose-built information connectors to make sure affected person confidentiality (1). We then leverage Delta Lake’s multi-hop structure (bronze, silver, gold) to progressively cleanse, put together, and set up the info for downstream utilization (2).
- Uncooked information is ingested as bronze tables.
- Every supply clinician would possibly use completely different codecs or schema for his or her digital well being information, so information is normalized, cleansed, and arranged in silver. Additional transformations, resembling de-identification, are utilized for the gold tables (2). Pure language processing may also be utilized at this stage to, for instance, convert free-form clinician notes into usable variables.
- These gold tables at the moment are able to be shared with our prospects as totally cleansed and prepped information merchandise to be used in analytics and AI (3).
With the Databricks Unity Catalog, we’re capable of centralize entry management, auditing, lineage, and information discovery throughout Databricks workspaces. Particularly, we are able to outline and management entry all the way down to the desk, column, and row stage — guaranteeing the appropriate information is shared with a researcher with out requiring him/her to filter by means of massive chunks of pointless information. This has saved huge quantities of time and compute prices.
Serving to scientists collaborate higher and quicker
Our Verana Well being information scientists make the most of Databricks notebooks for interactive exploration in addition to code improvement. A simple-to-use internet interface permits them to work in most popular languages resembling SQL, Python, and R (even throughout the identical pocket book). Outcomes may be positioned instantly into dashboards and in-line visualizations, in addition to exported to exterior instruments resembling Tableau and Google Docs. Notebooks and code are simply managed with supply management (git), separate from information and outcomes.
Complicated analyses may be created leveraging workflows, which permits our Verana Well being information scientists to orchestrate complicated calculations by connecting particular person analyses and code. Workflows can then be run manually, robotically triggered by arrival of recent information, or on a schedule. Full outcomes, execution time metrics, and messages are accessible throughout and after runs. This protects scientists vital time, in comparison with operating complicated calculations interactively.
Behind the scenes, Databricks supplies wealthy options for efficiency tuning and value optimization. These embrace a natively compiled Apache Spark implementation (Photon acceleration), which permits analyses to run as much as 20% quicker; and non-interactive job clusters, which can be utilized inside workflows for added 20% efficiency acquire. Different key options embrace Delta tables, which permit our information scientists to assemble very massive datasets incrementally–and extract variations by date or tag. This helps totally reproducible outcomes with out the price and complexity of managing a number of copies.
Maximizing real-world information for unprecedented healthcare insights
Verana Well being is on the forefront of digital well being, leveraging its in depth real-world information community and strategic collaborations to revolutionize healthcare. With Databricks, Verana Well being is ready to maximize the worth of its huge quantities of information, enabling the supply of high-quality datasets and empowering researchers, analysts, and clinicians.
Via Databricks’ superior capabilities, Verana Well being can effectively analyze and discover complicated well being data, collaborate seamlessly, and generate invaluable insights. The mixing of Databricks, with Verana Well being’s platform, enhances our capability to optimize scientific trials, conduct real-world proof research, drive inhabitants well being analytics, and help CMS reporting. By combining cutting-edge know-how with deep experience, Verana Well being and Databricks are driving innovation and propelling the healthcare trade ahead.

{kind=link}