

SOCAR is the main Korean mobility firm with sturdy competitiveness in car-sharing. SOCAR has develop into a complete mobility platform in collaboration with Nine2One, an e-bike sharing service, and Modu Firm, a web-based parking platform. Backed by superior expertise and information, SOCAR solves mobility-related social issues, similar to parking difficulties and site visitors congestion, and modifications the automobile ownership-oriented mobility habits in Korea.
SOCAR is constructing a brand new fleet administration system to handle the various actions and processes that should happen to ensure that fleet automobiles to run on time, inside funds, and at most effectivity. To realize this, SOCAR is trying to construct a extremely scalable information platform utilizing AWS providers to gather, course of, retailer, and analyze web of issues (IoT) streaming information from numerous automobile units and historic operational information.
This in-car system information, mixed with operational information similar to automobile particulars and reservation particulars, will present a basis for analytics use circumstances. For instance, SOCAR will have the ability to notify clients if they’ve forgotten to show their headlights off or to schedule a service if a battery is working low. Sadly, the earlier structure didn’t allow the enrichment of IoT information with operational information and couldn’t assist streaming analytics use circumstances.
AWS Information Lab provides accelerated, joint-engineering engagements between clients and AWS technical assets to create tangible deliverables that speed up information and analytics modernization initiatives. The Construct Lab is a 2–5-day intensive construct with a technical buyer workforce.
On this publish, we share how SOCAR engaged the Information Lab program to help them in constructing a prototype answer to beat these challenges, and to construct the premise for accelerating their information undertaking.
Use case 1: Streaming information analytics and real-time management
SOCAR needed to make the most of IoT information for a brand new enterprise initiative. A fleet administration system, the place information comes from IoT units within the automobiles, is a key enter to drive enterprise selections and derive insights. This information is captured by AWS IoT and despatched to Amazon Managed Streaming for Apache Kafka (Amazon MSK). By becoming a member of the IoT information to different operational datasets, together with reservations, automobile info, system info, and others, the answer can assist plenty of features throughout SOCAR’s enterprise.
An instance of real-time monitoring is when a buyer turns off the automobile engine and closes the automobile door, however the headlights are nonetheless on. By utilizing IoT information associated to the automobile mild, door, and engine, a notification is distributed to the shopper to tell them that the automobile headlights ought to be turned off.
Though this real-time management is necessary, in addition they wish to acquire historic information—each uncooked and curated information—in Amazon Easy Storage Service (Amazon S3) to assist historic analytics and visualizations through the use of Amazon QuickSight.
Use case 2: Detect desk schema change
The primary problem SOCAR confronted was current batch ingestion pipelines that had been liable to breaking when schema modifications occurred within the supply techniques. Moreover, these pipelines didn’t ship information in a means that was straightforward for enterprise analysts to eat. In an effort to meet the long run information volumes and enterprise necessities, they wanted a sample for the automated monitoring of batch pipelines with notification of schema modifications and the power to proceed processing.
The second problem was associated to the complexity of the JSON information being ingested. The present batch pipelines weren’t flattening the five-level nested construction, which made it tough for enterprise customers and analysts to achieve enterprise insights with none effort on their finish.
Overview of answer
On this answer, we adopted the serverless information structure to determine a knowledge platform for SOCAR. This serverless structure allowed SOCAR to run information pipelines constantly and scale mechanically with no setup value and with out managing servers.
AWS Glue is used for each the streaming and batch information pipelines. Amazon Kinesis Information Analytics is used to ship streaming information with subsecond latencies. When it comes to storage, information is saved in Amazon S3 for historic information evaluation, auditing, and backup. Nevertheless, when frequent studying of the most recent snapshot information is required by a number of customers and functions concurrently, the info is saved and browse from Amazon DynamoDB tables. DynamoDB is a key-value and doc database that may assist tables of just about any dimension with horizontal scaling.
Let’s talk about the parts of the answer intimately earlier than strolling by the steps of your complete information circulation.
Element 1: Processing IoT streaming information with enterprise information
The primary information pipeline (see the next diagram) processes IoT streaming information with enterprise information from an Amazon Aurora MySQL-Suitable Version database.
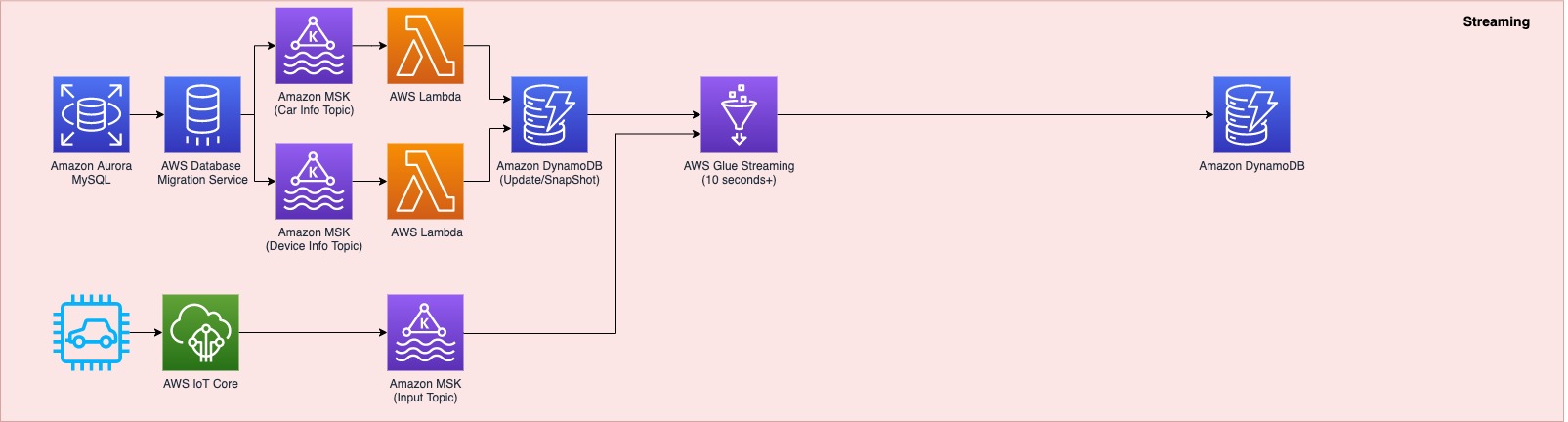
Each time a transaction happens in two tables within the Aurora MySQL database, this transaction is captured as information after which loaded into two MSK matters by way of AWS Database Administration (AWS DMS) duties. One matter conveys the automobile info desk, and the opposite matter is for the system info desk. This information is loaded right into a single DynamoDB desk that incorporates all of the attributes (or columns) that exist within the two tables within the Aurora MySQL database, together with a major key. This single DynamoDB desk incorporates the most recent snapshot information from the 2 DB tables, and is necessary as a result of it incorporates the most recent info of all of the automobiles and units for the lookup in opposition to the streaming IoT information. If the lookup had been completed on the database instantly with the streaming information, it could affect the manufacturing database efficiency.
When the snapshot is on the market in DynamoDB, an AWS Glue streaming job runs constantly to gather the IoT information and be a part of it with the most recent snapshot information within the DynamoDB desk to supply the up-to-date output, which is written into one other DynamoDB desk.
The up-to-date information in DynamoDB is used for real-time monitoring and management that SOCAR’s Information Analytics workforce performs for security upkeep and fleet administration. This information is finally consumed by plenty of apps to carry out numerous enterprise actions, together with route optimization, real-time monitoring for oil consumption and temperature, and to determine a driver’s driving sample, tire put on and defect detection, and real-time automobile crash notifications.
Element 2: Processing IoT information and visualizing the info in dashboards
The second information pipeline (see the next diagram) batch processes the IoT information and visualizes it in QuickSight dashboards.
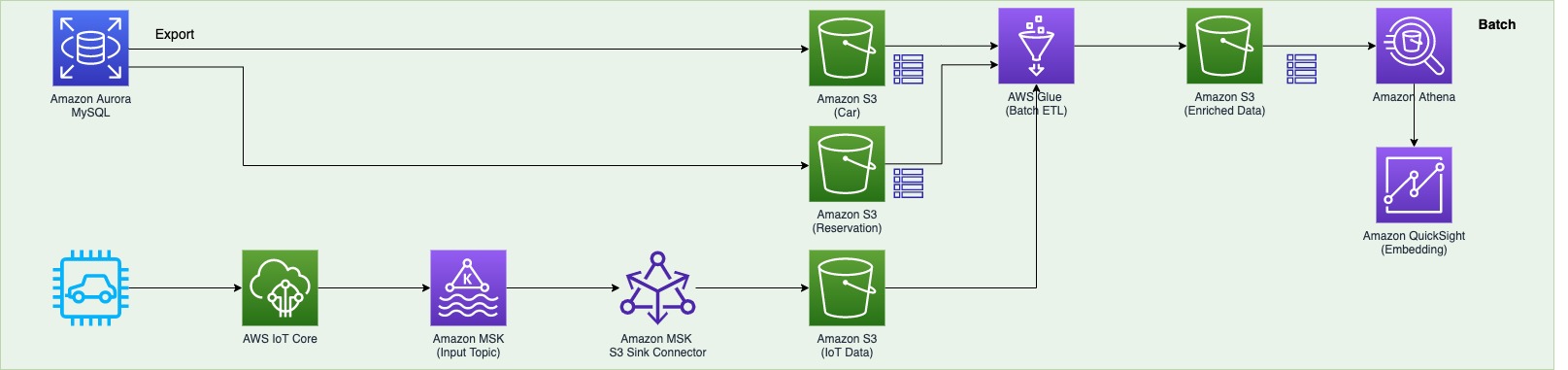
There are two information sources. The primary is the Aurora MySQL database. The 2 database tables are exported into Amazon S3 from the Aurora MySQL cluster and registered within the AWS Glue Information Catalog as tables. The second information supply is Amazon MSK, which receives streaming information from AWS IoT Core. This requires you to create a safe AWS Glue connection for an Apache Kafka information stream. SOCAR’s MSK cluster requires SASL_SSL as a safety protocol (for extra info, check with Authentication and authorization for Apache Kafka APIs). To create an MSK connection in AWS Glue and arrange connectivity, we use the next CLI command:
Element 3: Actual-time management
The third information pipeline processes the streaming IoT information in millisecond latency from Amazon MSK to supply the output in DynamoDB, and sends a notification in actual time if any data are recognized as an outlier based mostly on enterprise guidelines.

AWS IoT Core gives integrations with Amazon MSK to arrange real-time streaming information pipelines. To take action, full the next steps:
- On the AWS IoT Core console, select Act within the navigation pane.
- Select Guidelines, and create a brand new rule.
- For Actions, select Add motion and select Kafka.
- Select the VPC vacation spot if required.
- Specify the Kafka matter.
- Specify the TLS bootstrap servers of your Amazon MSK cluster.
You possibly can view the bootstrap server URLs within the shopper info of your MSK cluster particulars. The AWS IoT rule was created with the Kafka matter as an motion to supply information from AWS IoT Core to Kafka matters.
SOCAR used Amazon Kinesis Information Analytics Studio to investigate streaming information in actual time and construct stream-processing functions utilizing commonplace SQL and Python. We created one desk from the Kafka matter utilizing the next code:
Then we utilized a question with enterprise logic to determine a specific set of data that should be alerted. When this information is loaded again into one other Kafka matter, AWS Lambda features set off the downstream motion: both load the info right into a DynamoDB desk or ship an e-mail notification.
Element 4: Flattening the nested construction JSON and monitoring schema modifications
The ultimate information pipeline (see the next diagram) processes complicated, semi-structured, and nested JSON information.

This step makes use of an AWS Glue DynamicFrame to flatten the nested construction after which land the output in Amazon S3. After the info is loaded, it’s scanned by an AWS Glue crawler to replace the Information Catalog desk and detect any modifications within the schema.
Information circulation: Placing all of it collectively
The next diagram illustrates our full information circulation with every part.

Let’s stroll by the steps of every pipeline.
The primary information pipeline (in purple) processes the IoT streaming information with the Aurora MySQL enterprise information:
- AWS DMS is used for ongoing replication to constantly apply supply modifications to the goal with minimal latency. The supply consists of two tables within the Aurora MySQL database tables (
carinfoanddeviceinfo), and every is linked to 2 MSK matters by way of AWS DMS duties. - Amazon MSK triggers a Lambda operate, so at any time when a subject receives information, a Lambda operate runs to load information into DynamoDB desk.
- There’s a single DynamoDB desk with columns that exist from the
carinfodesk and thedeviceinfodesk of the Aurora MySQL database. This desk consists of all the info from two tables and shops the most recent information by performing anupsertoperation. - An AWS Glue job constantly receives the IoT information and joins it with information within the DynamoDB desk to supply the output into one other DynamoDB goal desk.
- This goal desk incorporates the ultimate information, which incorporates all of the system and automobile standing info from the IoT units in addition to metadata from the Aurora MySQL desk.
The second information pipeline (in inexperienced) batch processes IoT information to make use of in dashboards and for visualization:
- The automobile and reservation information (in two DB tables) is exported by way of a SQL command from the Aurora MySQL database with the output information obtainable in an S3 bucket. The folders that include information are registered as an S3 location for the AWS Glue crawler and develop into obtainable by way of the AWS Glue Information Catalog.
- The MSK enter matter constantly receives information from AWS IoT. Every automobile has plenty of IoT units, and every system captures information and sends it to an MSK enter matter. The Amazon MSK S3 sink connector is configured to export information from Kafka matters to Amazon S3 in JSON codecs. As well as, the S3 connector exports information by guaranteeing exactly-once supply semantics to shoppers of the S3 objects it produces.
- The AWS Glue job runs in a every day batch to load the historic IoT information into Amazon S3 and into two tables (check with step 1) to supply the output information in an Enriched folder in Amazon S3.
- Amazon Athena is used to question information from Amazon S3 and make it obtainable as a dataset in QuickSight for visualizing historic information.
The third information pipeline (in blue) processes streaming IoT information from Amazon MSK with millisecond latency to supply the output in DynamoDB and ship a notification:
- An Amazon Kinesis Information Analytics Studio pocket book powered by Apache Zeppelin and Apache Flink is used to construct and deploy its output as a Kinesis Information Analytics utility. This utility masses information from Amazon MSK in actual time, and customers can apply enterprise logic to pick explicit occasions coming from the IoT real-time information, for instance, the automobile engine is off and the doorways are closed, however the headlights are nonetheless on. The actual occasion that customers wish to seize may be despatched to a different MSK matter (Outlier) by way of the Kinesis Information Analytics utility.
- Amazon MSK triggers a Lambda operate, so at any time when a subject receives information, a Lambda operate runs to ship an e-mail notification to customers which might be subscribed to an Amazon Easy Notification Service (Amazon SNS) matter. An e-mail is revealed utilizing an SNS notification.
- The Kinesis Information Analytics utility masses information from AWS IoT, applies enterprise logic, after which masses it into one other MSK matter (output). Amazon MSK triggers a Lambda operate when information is acquired, which masses information right into a DynamoDB Append desk.
- Amazon Kinesis Information Analytics Studio is used to run SQL instructions for advert hoc interactive evaluation on streaming information.
The ultimate information pipeline (in yellow) processes complicated, semi-structured, and nested JSON information, and sends a notification when a schema evolves.
- An AWS Glue job runs and reads the JSON information from Amazon S3 (as a supply), applies logic to flatten the nested schema utilizing a DynamicFrame, and pivots out array columns from the flattened body.
- The output is saved in Amazon S3 and is mechanically registered to the AWS Glue Information Catalog desk.
- Each time there’s a new attribute or change within the JSON enter information at any stage within the nested construction, the brand new attribute and alter are captured in Amazon EventBridge as an occasion from the AWS Glue Information Catalog. An e-mail notification is revealed utilizing Amazon SNS.
Conclusion
On account of the four-day Construct Lab, the SOCAR workforce left with a working prototype that’s customized match to their wants, gaining a transparent path to manufacturing. The Information Lab allowed the SOCAR workforce to construct a brand new streaming information pipeline, enrich IoT information with operational information, and improve the present information pipeline to course of complicated nested JSON information. This establishes a baseline structure to assist the brand new fleet administration system past the car-sharing enterprise.
Concerning the Authors
 DoYeun Kim is the Head of Information Engineering at SOCAR. He’s a passionate software program engineering skilled with 19+ years expertise. He leads a workforce of 10+ engineers who’re liable for the info platform, information warehouse and MLOps engineering, in addition to constructing in-house information merchandise.
DoYeun Kim is the Head of Information Engineering at SOCAR. He’s a passionate software program engineering skilled with 19+ years expertise. He leads a workforce of 10+ engineers who’re liable for the info platform, information warehouse and MLOps engineering, in addition to constructing in-house information merchandise.
 SangSu Park is a Lead Information Architect in SOCAR’s cloud DB workforce. His ardour is to continue to learn, embrace challenges, and try for mutual development by communication. He likes to journey in quest of new cities and locations.
SangSu Park is a Lead Information Architect in SOCAR’s cloud DB workforce. His ardour is to continue to learn, embrace challenges, and try for mutual development by communication. He likes to journey in quest of new cities and locations.
 YoungMin Park is a Lead Architect in SOCAR’s cloud infrastructure workforce. His philosophy in life is-whatever it could be-to problem, fail, study, and share such experiences to construct a greater tomorrow for the world. He enjoys constructing experience in numerous fields and basketball.
YoungMin Park is a Lead Architect in SOCAR’s cloud infrastructure workforce. His philosophy in life is-whatever it could be-to problem, fail, study, and share such experiences to construct a greater tomorrow for the world. He enjoys constructing experience in numerous fields and basketball.
 Younggu Yun is a Senior Information Lab Architect at AWS. He works with clients across the APAC area to assist them obtain enterprise targets and remedy technical issues by offering prescriptive architectural steering, sharing finest practices, and constructing progressive options collectively. In his free time, his son and he are obsessive about Lego blocks to construct inventive fashions.
Younggu Yun is a Senior Information Lab Architect at AWS. He works with clients across the APAC area to assist them obtain enterprise targets and remedy technical issues by offering prescriptive architectural steering, sharing finest practices, and constructing progressive options collectively. In his free time, his son and he are obsessive about Lego blocks to construct inventive fashions.
 Vicky Falconer leads the AWS Information Lab program throughout APAC, providing accelerated joint engineering engagements between groups of buyer builders and AWS technical assets to create tangible deliverables that speed up information analytics modernization and machine studying initiatives.
Vicky Falconer leads the AWS Information Lab program throughout APAC, providing accelerated joint engineering engagements between groups of buyer builders and AWS technical assets to create tangible deliverables that speed up information analytics modernization and machine studying initiatives.

{kind=link}