

This submit is written in collaboration with Elijah Ball from Ontraport.
Clients are implementing knowledge and analytics workloads within the AWS Cloud to optimize value. When implementing knowledge processing workloads in AWS, you may have the choice to make use of applied sciences like Amazon EMR or serverless applied sciences like AWS Glue. Each choices decrease the undifferentiated heavy lifting actions like managing servers, performing upgrades, and deploying safety patches and will let you give attention to what’s necessary: assembly core enterprise aims. The distinction between each approaches can play a important function in enabling your group to be extra productive and progressive, whereas additionally saving cash and assets.
Providers like Amazon EMR give attention to providing you flexibility to help knowledge processing workloads at scale utilizing frameworks you’re accustomed to. For instance, with Amazon EMR, you may select from a number of open-source knowledge processing frameworks resembling Apache Spark, Apache Hive, and Presto, and fine-tune workloads by customizing issues resembling cluster occasion sorts on Amazon Elastic Compute Cloud (Amazon EC2) or use containerized environments operating on Amazon Elastic Kubernetes Service (Amazon EKS). This selection is finest suited when migrating workloads from huge knowledge environments like Apache Hadoop or Spark, or when utilized by groups which are acquainted with open-source frameworks supported on Amazon EMR.
Serverless providers like AWS Glue decrease the necessity to consider servers and give attention to providing extra productiveness and DataOps tooling for accelerating knowledge pipeline growth. AWS Glue is a serverless knowledge integration service that helps analytics customers uncover, put together, transfer, and combine knowledge from a number of sources by way of a low-code or no-code method. This selection is finest suited when organizations are resource-constrained and must construct knowledge processing workloads at scale with restricted experience, permitting them to expedite growth and diminished Whole Value of Possession (TCO).
On this submit, we present how our AWS buyer Ontraport evaluated the usage of AWS Glue and Amazon EMR to cut back TCO, and the way they diminished their storage value by 92% and their processing value by 80% with just one full-time developer.
Ontraport’s workload and resolution
Ontraport is a CRM and automation service that powers companies’ advertising, gross sales and operations multi function place—empowering companies to develop quicker and ship extra worth to their clients.
Log processing and evaluation is important to Ontraport. It permits them to supply higher providers and perception to clients resembling e mail marketing campaign optimization. For instance, e mail logs alone report 3–4 occasions for each one of many 15–20 million messages Ontraport sends on behalf of their purchasers every day. Evaluation of e mail transactions with suppliers resembling Google and Microsoft enable Ontraport’s supply workforce to optimize open charges for the campaigns of purchasers with huge contact lists.
A number of the huge log contributors are net server and CDN occasions, e mail transaction data, and customized occasion logs inside Ontraport’s proprietary functions. The next is a pattern breakdown of their day by day log contributions:
| Cloudflare request logs | 75 million data |
| CloudFront request logs | 2 million data |
| Nginx/Apache logs | 20 million data |
| Electronic mail logs | 50 million data |
| Normal server logs | 50 million data |
| Ontraport app logs | 6 million data |
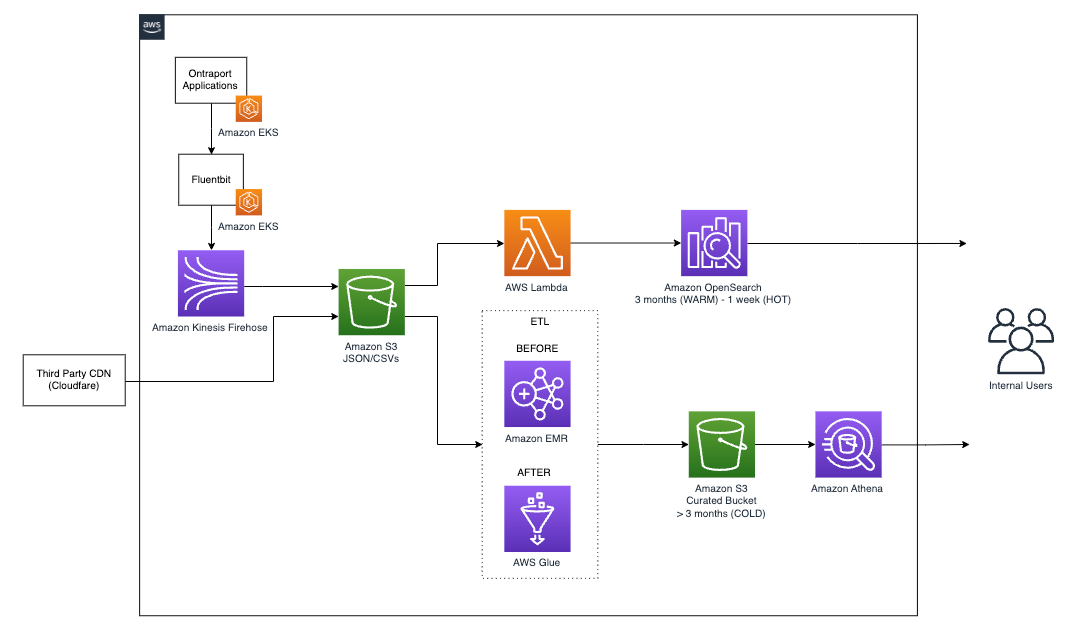
Ontraport’s resolution makes use of Amazon Kinesis and Amazon Kinesis Information Firehose to ingest log knowledge and write latest data into an Amazon OpenSearch Service database, from the place analysts and directors can analyze the final 3 months of information. Customized software logs report interactions with the Ontraport CRM so shopper accounts will be audited or recovered by the shopper help workforce. Initially, all logs had been retained again to 2018. Retention is multi-leveled by age:
- Lower than 1 week – OpenSearch scorching storage
- Between 1 week and three months – OpenSearch chilly storage
- Greater than 3 months – Extract, rework, and cargo (ETL) processed in Amazon Easy Storage Service (Amazon S3), obtainable by way of Amazon Athena
The next diagram reveals the structure of their log processing and analytics knowledge pipeline.
Evaluating the optimum resolution
With a purpose to optimize storage and evaluation of their historic data in Amazon S3, Ontraport carried out an ETL course of to rework and compress TSV and JSON information into Parquet information with partitioning by the hour. The compression and transformation helped Ontraport scale back their S3 storage prices by 92%.
In section 1, Ontraport carried out an ETL workload with Amazon EMR. Given the dimensions of their knowledge (tons of of billions of rows) and just one developer, Ontraport’s first try on the Apache Spark software required a 16-node EMR cluster with r5.12xlarge core and job nodes. The configuration allowed the developer to course of 1 12 months of information and decrease out-of-memory points with a tough model of the Spark ETL software.
To assist optimize the workload, Ontraport reached out to AWS for optimization suggestions. There have been a substantial variety of choices to optimize the workload inside Amazon EMR, resembling right-sizing Amazon Elastic Compute Cloud (Amazon EC2) occasion sort primarily based on workload profile, modifying Spark YARN reminiscence configuration, and rewriting parts of the Spark code. Contemplating the useful resource constraints (just one full-time developer), the AWS workforce beneficial exploring comparable logic with AWS Glue Studio.
A number of the preliminary advantages with utilizing AWS Glue for this workload embrace the next:
- AWS Glue has the idea of crawlers that gives a no-code method to catalog knowledge sources and establish schema from a number of knowledge sources, on this case, Amazon S3.
- AWS Glue gives built-in knowledge processing capabilities with summary strategies on prime of Spark that scale back the overhead required to develop environment friendly knowledge processing code. For instance, AWS Glue helps a DynamicFrame class comparable to a Spark DataFrame that gives extra flexibility when working with semi-structured datasets and will be rapidly remodeled right into a Spark DataFrame. DynamicFrames will be generated instantly from crawled tables or instantly from information in Amazon S3. See the next instance code:
- It minimizes the necessity for Ontraport to right-size occasion sorts and auto scaling configurations.
- Utilizing AWS Glue Studio interactive periods permits Ontraport to rapidly iterate when code modifications the place wanted when detecting historic log schema evolution.
Ontraport needed to course of 100 terabytes of log knowledge. The price of processing every terabyte with the preliminary configuration was roughly $500. That value got here right down to roughly $100 per terabyte after utilizing AWS Glue. Through the use of AWS Glue and AWS Glue Studio, Ontraport’s value of processing the roles was diminished by 80%.
Diving deep into the AWS Glue workload
Ontraport’s first AWS Glue software was a PySpark workload that ingested knowledge from TSV and JSON information in Amazon S3, carried out primary transformations on timestamp fields, and transformed the info kinds of a pair fields. Lastly, it writes output knowledge right into a curated S3 bucket as compressed Parquet information of roughly 1 GB in measurement and partitioned in 1-hour intervals to optimize for queries with Athena.
With an AWS Glue job configured with 10 staff of the kind G.2x configuration, Ontraport was in a position to course of roughly 500 million data in lower than 60 minutes. When processing 10 billion data, they had been in a position to improve the job configuration to a most of 100 staff with auto scaling enabled to finish the job inside 1 hour.
What’s subsequent?
Ontraport has been in a position to course of logs as early as 2018. The workforce is updating the processing code to permit for eventualities of schema evolution (resembling new fields) and parameterized some elements to completely automate the batch processing. They’re additionally trying to fine-tune the variety of provisioned AWS Glue staff to acquire optimum price-performance.
Conclusion
On this submit, we confirmed you the way Ontraport used AWS Glue to assist scale back growth overhead and simplify growth efforts for his or her ETL workloads with just one full-time developer. Though providers like Amazon EMR supply nice flexibility and optimization, the benefit of use and simplification in AWS Glue usually supply a quicker path for cost-optimization and innovation for small and medium companies. For extra details about AWS Glue, try Getting Began with AWS Glue.
Concerning the Authors
 Elijah Ball has been a Sys Admin at Ontraport for 12 years. He’s at present working to maneuver Ontraport’s manufacturing workloads to AWS and develop knowledge evaluation methods for Ontraport.
Elijah Ball has been a Sys Admin at Ontraport for 12 years. He’s at present working to maneuver Ontraport’s manufacturing workloads to AWS and develop knowledge evaluation methods for Ontraport.
 Pablo Redondo is a Principal Options Architect at Amazon Internet Providers. He’s a knowledge fanatic with over 16 years of FinTech and healthcare business expertise and is a member of the AWS Analytics Technical Area Group (TFC). Pablo has been main the AWS Acquire Insights Program to assist AWS clients obtain higher insights and tangible enterprise worth from their knowledge analytics initiatives.
Pablo Redondo is a Principal Options Architect at Amazon Internet Providers. He’s a knowledge fanatic with over 16 years of FinTech and healthcare business expertise and is a member of the AWS Analytics Technical Area Group (TFC). Pablo has been main the AWS Acquire Insights Program to assist AWS clients obtain higher insights and tangible enterprise worth from their knowledge analytics initiatives.
 Vikram Honmurgi is a Buyer Options Supervisor at Amazon Internet Providers. With over 15 years of software program supply expertise, Vikram is keen about helping clients and accelerating their cloud journey, delivering frictionless migrations, and guaranteeing our clients seize the complete potential and sustainable enterprise benefits of migrating to the AWS Cloud.
Vikram Honmurgi is a Buyer Options Supervisor at Amazon Internet Providers. With over 15 years of software program supply expertise, Vikram is keen about helping clients and accelerating their cloud journey, delivering frictionless migrations, and guaranteeing our clients seize the complete potential and sustainable enterprise benefits of migrating to the AWS Cloud.

{kind=link}